AIに世界最高レベルの効率をもたらす
ゼロ ダーク シリコンソリューション
AMD-ザイリンクス (ザイリンクス株式会社)
Adaptive and Embedded Computing Group (AECG)
Data Center and Communications Group (DCCG)
堀江義弘
2022年 6月2日
2.
2
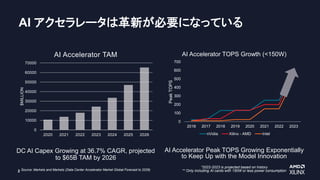
AI アクセラレータは革新が必要になっている
DC AICapex Growing at 36.7% CAGR, projected
to $65B TAM by 2026
Source: Markets and Markets (Data Center Accelerator Market Global Forecast to 2026)
AI Accelerator Peak TOPS Growing Exponentially
to Keep Up with the Model Innovation
*2022-2023 is projected based on history
** Only including AI cards with 150W or less power consumption
0
100
200
300
400
500
600
700
2016 2017 2018 2019 2020 2021 2022 2023
Peak
TOPS
AI Accelerator TOPS Growth (<150W)
nVidia Xilinx - AMD Intel
0
10000
20000
30000
40000
50000
60000
70000
2020 2021 2022 2023 2024 2025 2026
$MILLION
AI Accelerator TAM
3.
3
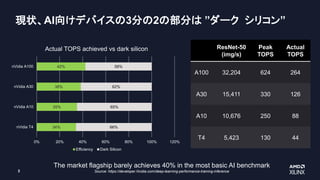
現状、AI向けデバイスの3分の2の部分は ”ダーク シリコン”
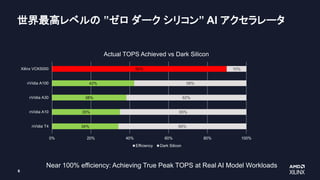
Themarket flagship barely achieves 40% in the most basic AI benchmark
Source: https://developer.Nvidia.com/deep-learning-performance-training-inference
34%
35%
38%
42%
66%
65%
62%
58%
0% 20% 40% 60% 80% 100% 120%
nVidia T4
nVidia A10
nVidia A30
nVidia A100
Actual TOPS achieved vs dark silicon
Efficiency Dark Silicon
ResNet-50
(img/s)
Peak
TOPS
Actual
TOPS
A100 32,204 624 264
A30 15,411 330 126
A10 10,676 250 88
T4 5,423 130 44
10
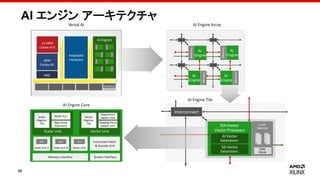
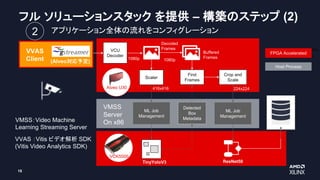
Adaptable
Hardware
AI Engines
ARM
Cortex-R5
2x ARM
Cortex-A72
PMC
VersalAI
AI Engine Core
Store Unit
Scalar Unit
Scalar
Register
File
Scalar ALU
Non-linear
Functions
Instruction Fetch
& Decode Unit
AGU
Vector Unit
Vector
Register
File
Fixed-Point
Vector Unit
Floating-Point
Vector Unit
Load Unit B
AGU
Load Unit A
AGU
Memory Interface Stream Interface
AI
Engine
Memory
AI
Engine
Memory
AI
Engine
Memory
AI Engine Array
AI
Engine
Memory
Interconnect
ISA-based
Vector Processor
Local
Memory
AI Vector
Extensions
5G Vector
Extensions
Data
Mover
AI Engine Tile
AI エンジン アーキテクチャ
11.
11
core
L0
core
L0
core
L0
Block 0
L1
core
L0
core
L0
core
L0
Block 1
L1
L2
DRAM
D0
D0
D0
D0
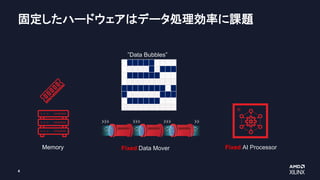
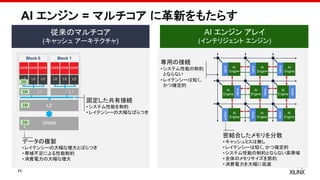
固定した共有接続
•システム性能を制約
• レイテンシーの大幅なばらつき
データの複製
• レイテンシーの大幅な増大とばらつき
• 帯域不足による性能制約
• 消費電力の大幅な増大
従来のマルチコア
(キャッシュ アーキテクチャ)
MEM
AI
Engine
MEM
AI
Engine
MEM
AI
Engine
AI
Engine
MEM
AI
Engine
AI
Engine
MEM
AI
Engine
MEM
MEM
AI エンジン アレイ
(インテリジェント エンジン)
専用の接続
• システム性能の制約
とならない
• レイテンシーは短く、
かつ確定的
密結合したメモリを分散
• キャッシュミスは無し
• レイテンシーは短く、かつ確定的
• システム性能の制約とならない高帯域
• 全体のメモリサイズを節約
• 消費電力を大幅に低減
AI
Engine
MEM
MEM
AI
Engine
AI エンジン = マルチコア に革新をもたらす
12.
12
Signal
Processing
AI Inference
optimized optimized
AIEAIE-ML
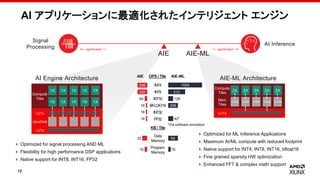
AI Engine Architecture
1X
1X
1X
1X
1X
1X
1X
1X
1X
1X
Compute
Tiles
UltraRAM
LUTs
LUTs
Optimized for signal processing AND ML
Flexibility for high performance DSP applications
Native support for INT8, INT16, FP32
INT4
INT8
INT16
BFLOAT16
INT32
FP32
AIE AIE-ML
OPS / Tile
1024
512
128
256
256
256
64
16
16
KB / Tile
64
Data
Memory
Program
Memory
16
16
32
16
42*
*Via software emulation
AIE-ML Architecture
2X 2X 2X 2X 2X
Compute
Tiles
LUTs
Mem
Tiles
Optimized for ML Inference Applications
Maximum AI/ML compute with reduced footprint
Native support for INT4, INT8, INT16, bfloat16
Fine grained sparsity HW optimization
Enhanced FFT & complex math support
512KB 512KB
512KB
512KB
512KB
AI アプリケーションに最適化されたインテリジェント エンジン
13.
13
Accelerator
Edge Aggregation &
AutonomousSystems
Intelligent Edge
Sensor & End Point
AI Compute (INT8x4)1
67 TOPS 479 TOPS
AI Compute (INT8)1
31 TOPS 228 TOPS
AIE-ML Tiles 34 304
Adaptable Engines 150K LUTs 521K LUTs
Processing Subsystem Dual-Core Arm® Cortex®-A72 Application Processing Unit / Dual-Core Arm Cortex-R5F Real-Time Processing Unit
Accelerator RAM (4MB) ✓ -
Total Memory 172Mb 575Mb
32G Transceivers 8 32
PCIe® ✓ ✓ (PCIe gen5 w/ DMA)
Video Decode Unit (VDU) - 4
Power 2
15-20W 75W
Engines
RAM
1: Total AI compute includes AI Engines, DSP Engines, and Adaptable Engines
2: Power Projections
VE2302 VE2802
AI/MLに向けた幅広い製品群

























![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)








![[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...](https://cdn.slidesharecdn.com/ss_thumbnails/jtf20182-180803022253-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Track2-5] CPUだけでAIをやり切った最近のお客様事例 と インテルの先進的な取り組み](https://cdn.slidesharecdn.com/ss_thumbnails/intel20200801dllabdeeplearningdigitalconferencefinalv1-200806120825-thumbnail.jpg?width=640&height=640&fit=bounds)





















