Download to read offline


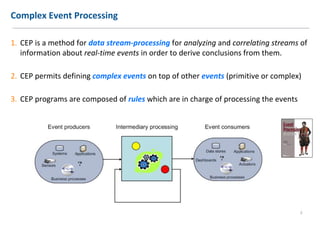
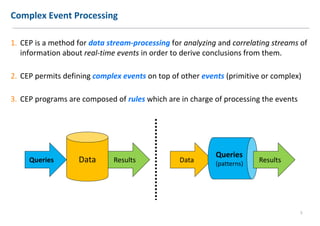
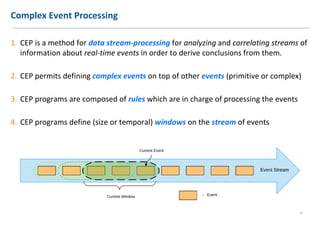




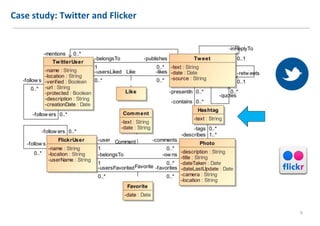
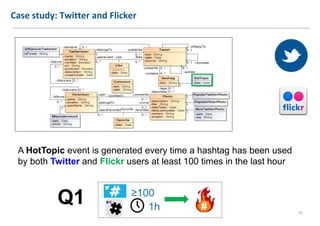




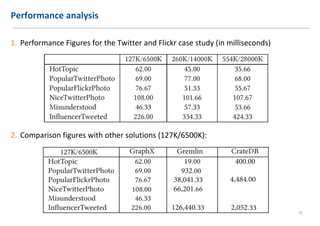

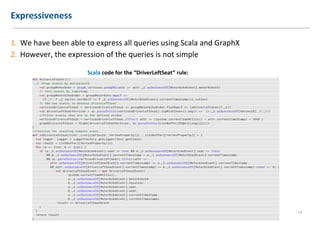



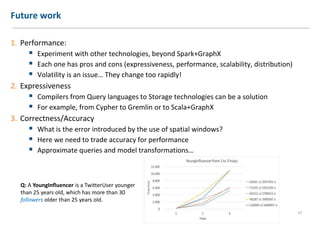


The document discusses extending Complex Event Processing (CEP) to handle graph-structured information, allowing for both time-ordered events and persistent data graphs. It highlights the need for CEP systems to evolve in performance and scalability to address complex data structures, using examples such as Twitter and Flickr data. The authors propose utilizing graph-parallel computational technologies and offer insights into future work involving performance, expressiveness, and correctness.


![[ICDE 2014] Incremental Cluster Evolution Tracking from Highly Dynamic Networ...](https://cdn.slidesharecdn.com/ss_thumbnails/icde2014-140416141240-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































































