Download as PDF, PPTX




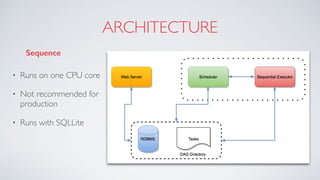
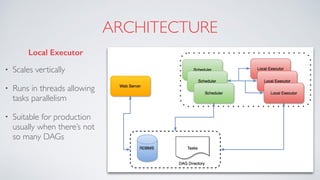
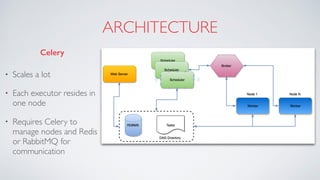
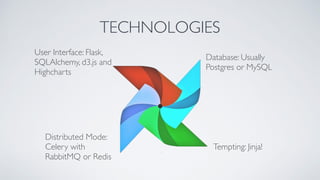

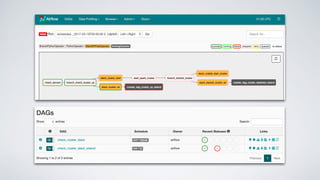
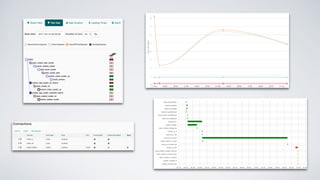

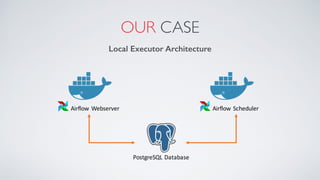






Airflow is an open-source platform for authoring and monitoring data pipelines, allowing configuration as code and dynamic generation. It provides flexibility, efficient parallel task execution, and a rich user interface while running on single or multiple nodes, primarily leveraging technologies like Flask and PostgreSQL. However, it faces challenges such as a lack of extensive documentation, missing operators for certain databases, and synchronization issues for Directed Acyclic Graphs (DAGs).









































![Bootstrapping a ML platform at Bluevine [Airflow Summit 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/airflowsummit20201-200716055944-thumbnail.jpg?width=640&height=640&fit=bounds)























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

