Download to read offline





























![Working
• The string-to-tree model accepts a Hindi string as input and seeks across multiple
parsed English trees and finds the highest scoring tree.
• Input is a string- व्यक्तिगि जीवन
• Translation Rules-
• [SYM][X] personal [NN][X] [FRAG] ||| [SYM][X] व्यक्ततगत [NN][X] [X] |||
0.0326378 0.6 0.0652757 1 ||| 0-0 1-1 2-2 ||| 0.285714 0.142857 0.142857 |||
• [SYM][X] personal life [FRAG] ||| [SYM][X] व्यक्ततगत जीिन [X] ||| 0.0326378
0.385714 0.0652757 0.6 ||| 0-0 1-1 2-2 ||| 0.285714 0.142857 0.142857 |||
• [SYM][X] personal life [TOP] ||| [SYM][X] व्यक्ततगत जीिन [X] ||| 0.0326378
0.385714 0.0652757 0.6 ||| 0-0 1-1 2-2 ||| 0.285714 0.142857 0.142857 |||
• Decoding by Translation Rules-
• [0..3]: [3..3]=</s> [0..2]=S : S ->S -> S </s> :0-0 : c=0 core=(0,-1,1,0,0,0,0,0,0)
0core=(0,-4,6,-11.5445,-5.99562,-7.46699,-1.60944,1.99979,-16.0431)
• [0..1]: [1..1]= X [0..0]=S : S ->S -> S X :0-0 1-1 : c=0 core=(0,-
0,1,0,0,0,0,0.999896,0) 0core=(0,-2,3,-3.35156,-0.916291,-2.43527,0,0.999896,-
7.74303)
• [0..0]: [0..0]=<s> : S ->S -> <s> :: c=0 core=(0,-1,1,0,0,0,0,0,0) 0core=(0,-
1,1,0,0,0,0,0,0)
• [1..1]: [1..1]=personel : X ->X -> व्यक्ततगत :: c=0 core=(0,-1,1,-3.35156,-
0.916291,-2.43527,0,0,0) 0core=(0,-1,1,-3.35156,-0.916291,-2.43527,0,0,-
9.44562)](https://image.slidesharecdn.com/7d71da47-7e6b-430d-bd46-99db29ee791d-160511174636/75/project-present-35-2048.jpg)










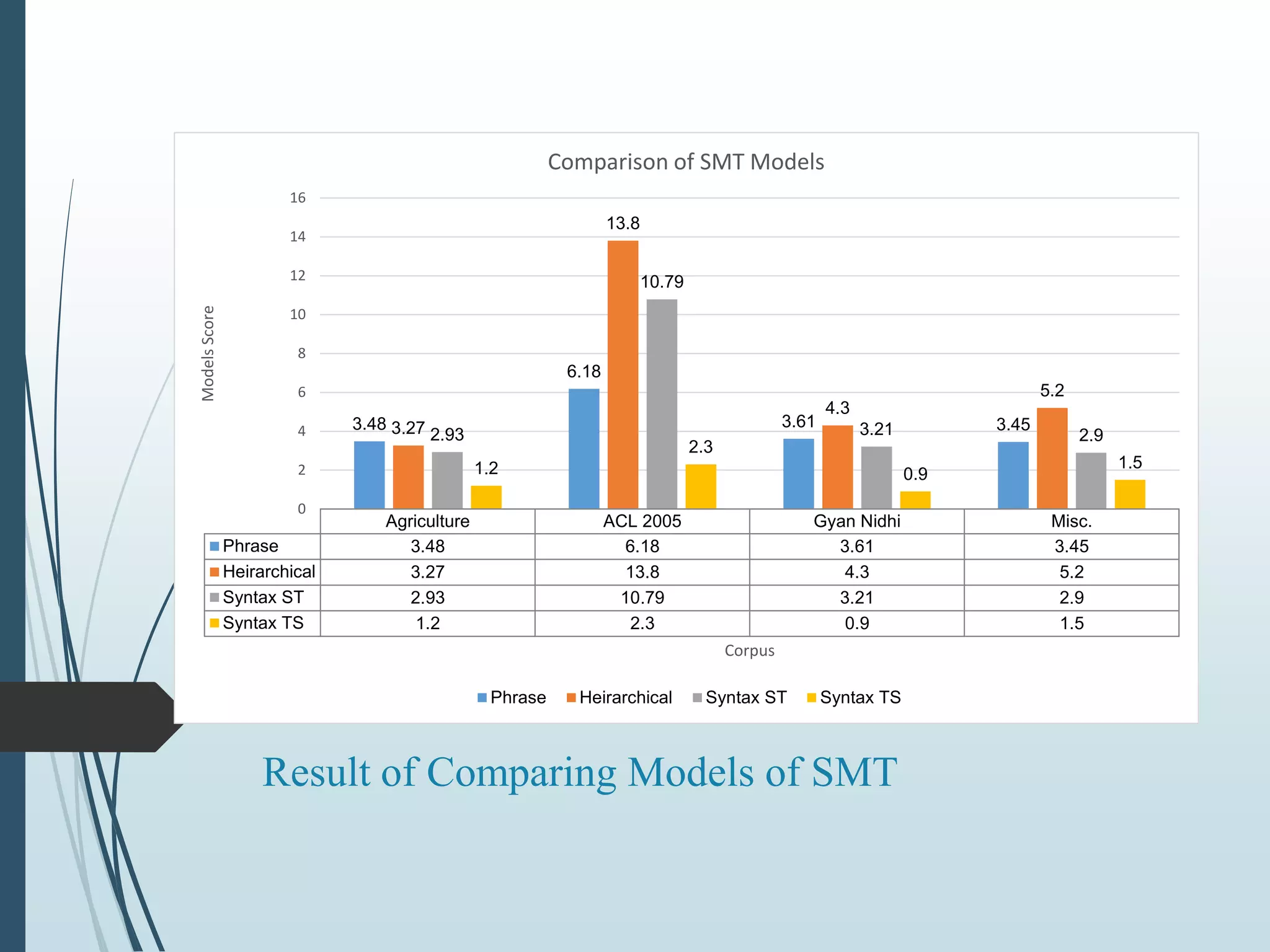





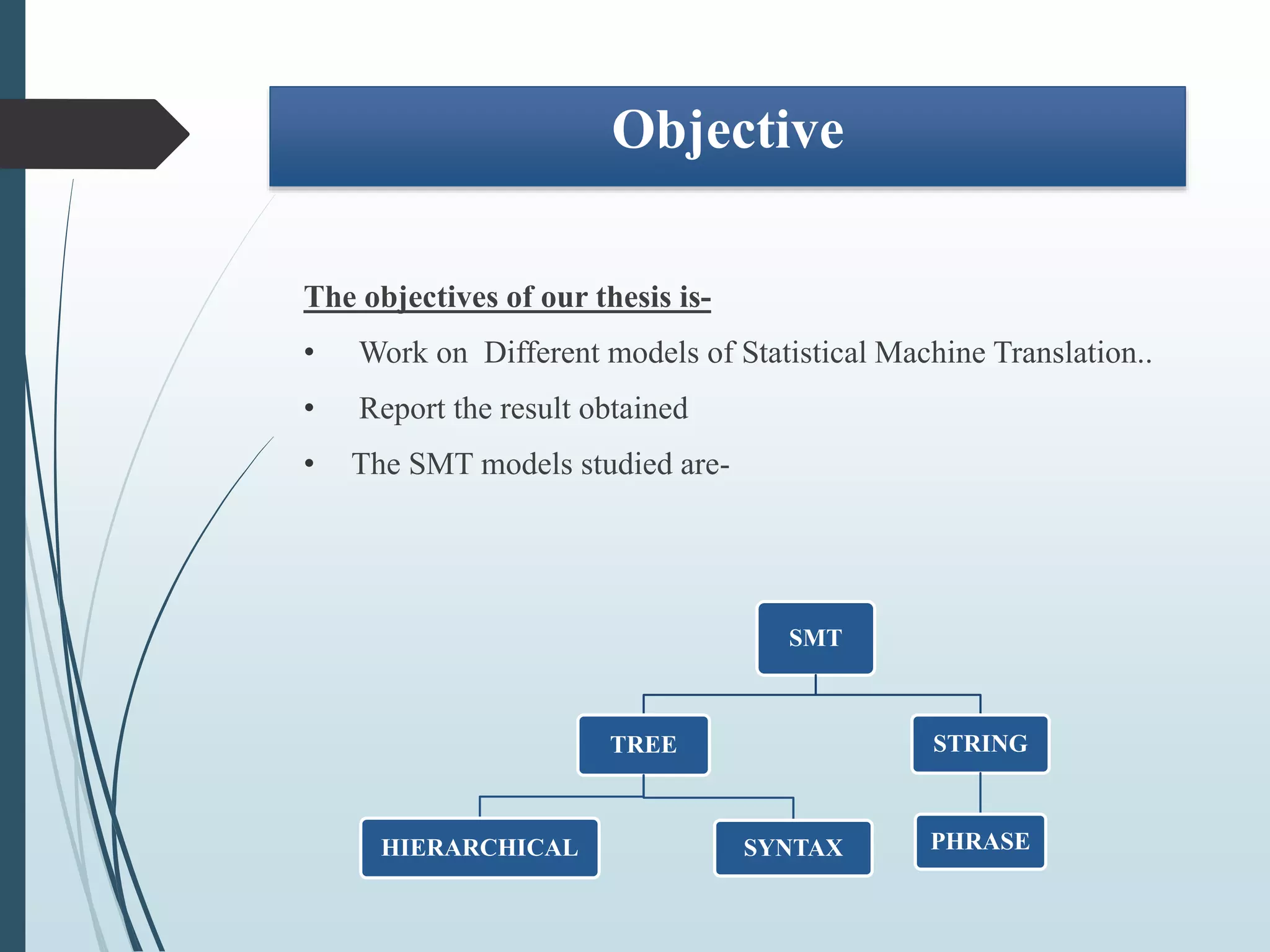
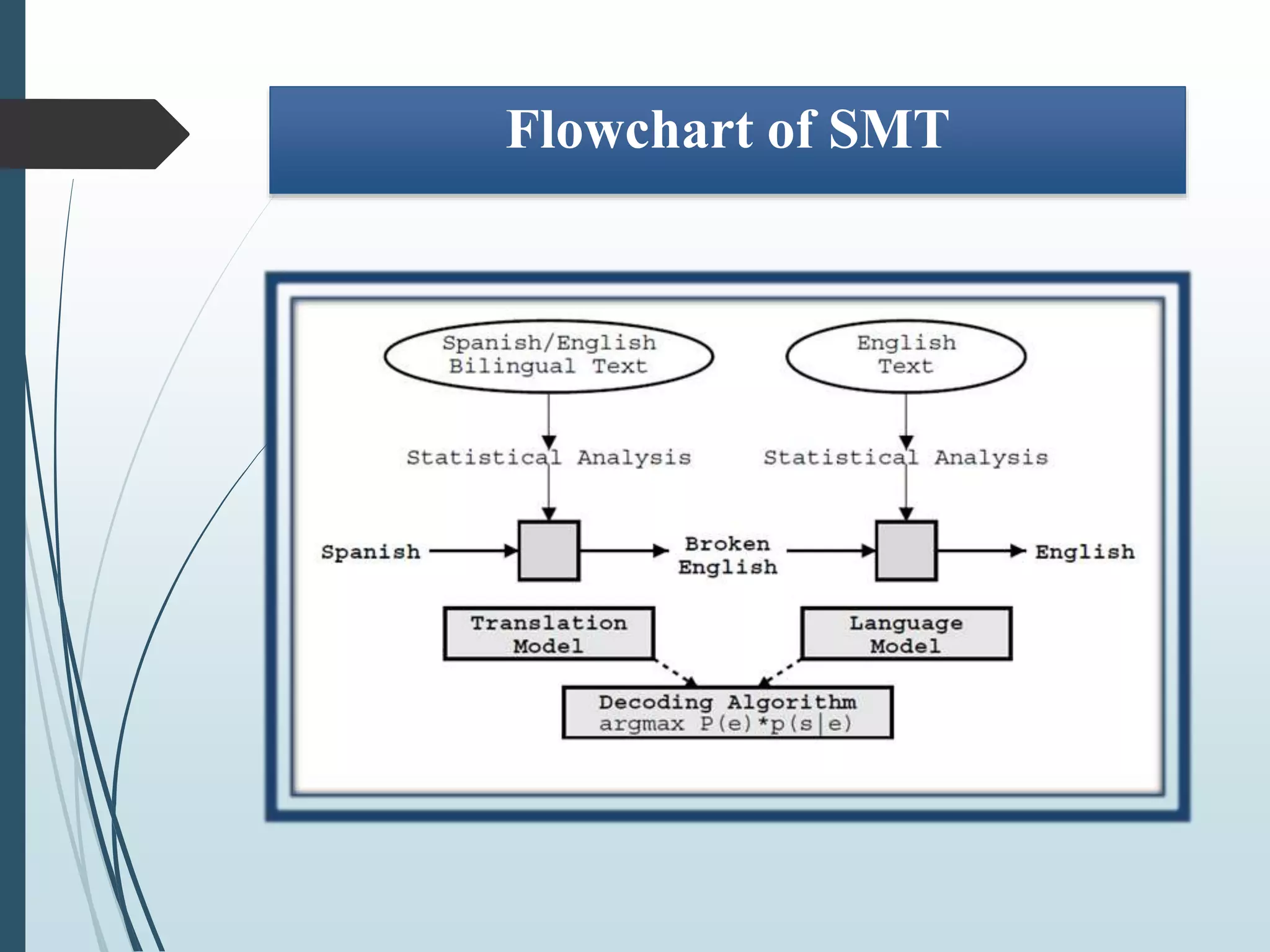
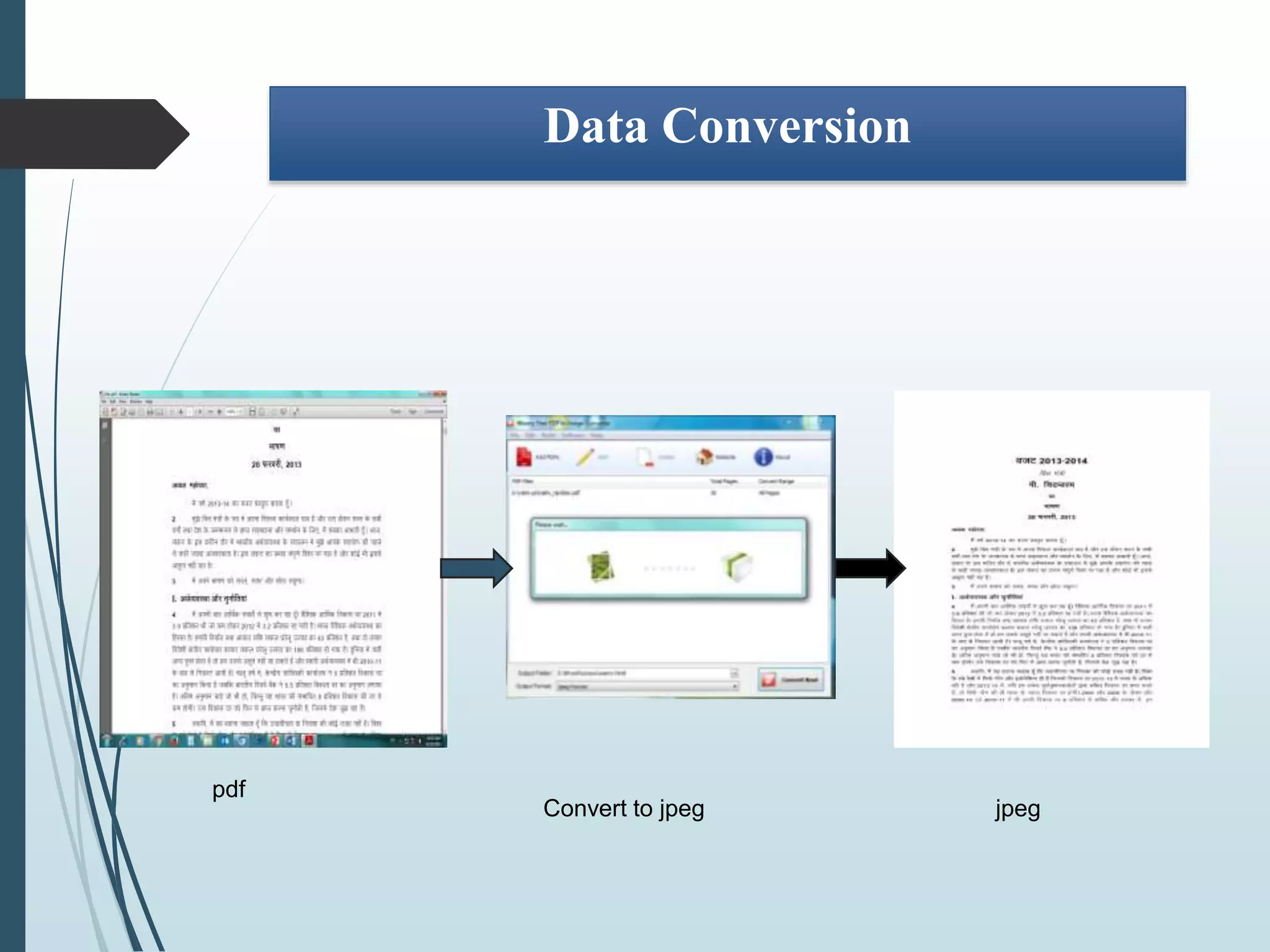
The document summarizes work done on experimenting with different models of statistical machine translation (SMT). It discusses various SMT models studied including phrase-based, hierarchical, syntax-based, and hybrid translation models. The document outlines the process of data preparation, training, tuning and evaluation of models on a Hindi-English language pair. Results showed that the hierarchical and syntax-based models performed better than phrase-based in terms of reordering words and producing grammatically correct sentences for the given language pair.










































