The document addresses the challenge of handling rare and unknown words in natural language processing (NLP) systems, proposing a novel solution using neural networks and attention mechanisms. The model features two softmax layers to predict outputs from a predefined shortlist of the most frequent words, while unknown words are represented by a special token. The authors highlight fundamental issues with the shortlist approach and discuss the architecture of the proposed neural machine translation model.



![•
•
•
• V
a man yesterday . [eos]!
killed a man yesterday .!t
+ bhp) (16)
(17)
Whp
bhp) (16)
(17)
(18)
(19)
!
man
a
a
man !
6
RNN t
pt
pt = softmax(W
ht =
−−−→
RNNt′≺t(
softmax(s)i =
exp(si
sj∈s exp
→
t′≺t(xwt′ ) (17)
p(si)
s exp(sj)
(18)
(19)
s i
Whp ∈ RV ×N
V
bhp(w)
Whp bhp
t = softmax(Whpht + bhp) (16)
t =
−−−→
RNNt′≺t(xwt′ ) (17)
i =
exp(si)
sj∈s exp(sj)
(18)
(19)
s i
Whp ∈ RV ×N
V
Whp(w) bhp(w)
(18)
(19)
i
Whp ∈ RV ×N
V
)
t wt
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
6
RNN t wt
pt
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
softmax(s)i N s
exp 3](https://image.slidesharecdn.com/pointingtheunknownwords-160906225848/85/Pointing-the-Unknown-Words-3-320.jpg)
![•
•
•
• V
a man yesterday . [eos]!
killed a man yesterday .!t
+ bhp) (16)
(17)
Whp
bhp) (16)
(17)
(18)
(19)
!
man
a
a
man !
6
RNN t
pt
pt = softmax(W
ht =
−−−→
RNNt′≺t(
softmax(s)i =
exp(si
sj∈s exp
→
t′≺t(xwt′ ) (17)
p(si)
s exp(sj)
(18)
(19)
s i
Whp ∈ RV ×N
V
bhp(w)
Whp bhp
t = softmax(Whpht + bhp) (16)
t =
−−−→
RNNt′≺t(xwt′ ) (17)
i =
exp(si)
sj∈s exp(sj)
(18)
(19)
s i
Whp ∈ RV ×N
V
Whp(w) bhp(w)
(18)
(19)
i
Whp ∈ RV ×N
V
)
t wt
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
• V T
•
•
•
Pointer Softmax
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
i N s
exp
w Whp ∈ RV ×N
Whp(w) bhp(w)
T
6
RNN t wt
pt
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
softmax(s)i N s
exp
6
RNN t wt
pt
pt = softmax(Whpht +
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
softmax(s)i N s
exp
・
4](https://image.slidesharecdn.com/pointingtheunknownwords-160906225848/85/Pointing-the-Unknown-Words-4-320.jpg)
![•
5
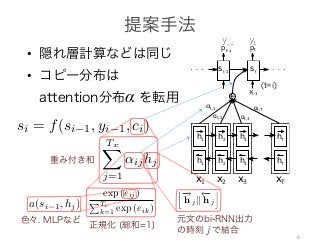
rce sentence during decoding a translation (Sec. 3.1).
ER: GENERAL DESCRIPTION
x1 x2 x3 xT
+
αt,1
αt,2 αt,3
αt,T
h1 h2 h3 hT
h1 h2 h3 hT
st-1 st
Figure 1: The graphical illus-
tration of the proposed model
trying to generate the t-th tar-
get word yt given a source
sentence (x , x , . . . , x ).
el architecture, we define each conditional probability
p(yi|y1, . . . , yi 1, x) = g(yi 1, si, ci), (4)
RNN hidden state for time i, computed by
si = f(si 1, yi 1, ci).
noted that unlike the existing encoder–decoder ap-
q. (2)), here the probability is conditioned on a distinct
ci for each target word yi.
vector ci depends on a sequence of annotations
) to which an encoder maps the input sentence. Each
contains information about the whole input sequence
focus on the parts surrounding the i-th word of the
e. We explain in detail how the annotations are com-
ext section.
ector ci is, then, computed as a weighted sum of these
i:
TxX
F
t
t
g
s
t vector ci depends on a sequence of annotations
x
) to which an encoder maps the input sentence. Each
hi contains information about the whole input sequence
g focus on the parts surrounding the i-th word of the
nce. We explain in detail how the annotations are com-
next section.
vector ci is, then, computed as a weighted sum of these
hi:
ci =
TxX
j=1
↵ijhj. (5)
↵ij of each annotation hj is computed by
↵ij =
exp (eij)
P ,
GENERAL DESCRIPTION
hitecture, we define each conditional probability
y1, . . . , yi 1, x) = g(yi 1, si, ci), (4)
N hidden state for time i, computed by
si = f(si 1, yi 1, ci).
d that unlike the existing encoder–decoder ap-
), here the probability is conditioned on a distinct
or each target word yi.
or ci depends on a sequence of annotations
which an encoder maps the input sentence. Each
Figure 1: The graphical illus-
tration of the proposed model
trying to generate the t-th tar-
get word yt given a source
sentence (x1, x2, . . . , xT ).
ere the probability is conditioned on a distinct
ach target word yi.
ci depends on a sequence of annotations
ch an encoder maps the input sentence. Each
s information about the whole input sequence
n the parts surrounding the i-th word of the
xplain in detail how the annotations are com-
on.
is, then, computed as a weighted sum of these
ci =
TxX
j=1
↵ijhj. (5)
h annotation hj is computed by
↵ij =
exp (eij)
PTx
k=1 exp (eik)
, (6)
e = a(s , h )
Figure 1: The graphical illus-
tration of the proposed model
trying to generate the t-th tar-
get word yt given a source
sentence (x1, x2, . . . , xT ).
t the whole input sequence
nding the i-th word of the
w the annotations are com-
as a weighted sum of these
. (5)
computed by
j =
exp (eij)
PTx
k=1 exp (eik)
, (6)
eij = a(si 1, hj)
well the inputs around position j and the output at position
hidden state si 1 (just before emitting yi, Eq. (4)) and the
3 Neural Machine Translation Model
with Attention
As the baseline neural machine translation sys-
tem, we use the model proposed by (Bahdanau et
al., 2014) that learns to (soft-)align and translate
jointly. We refer this model as NMT.
The encoder of the NMT is a bidirectional
RNN (Schuster and Paliwal, 1997). The forward
RNN reads input sequence x = (x1, . . . , xT )
in left-to-right direction, resulting in a sequence
of hidden states (
!
h 1, . . . ,
!
h T ). The backward
RNN reads x in the reversed direction and outputs
( h 1, . . . , h T ). We then concatenate the hidden
states of forward and backward RNNs at each time
step and obtain a sequence of annotation vectors
(h1, . . . , hT ) where hj =
h!
h j|| h j
i
. Here, ||
denotes the concatenation operator. Thus, each an-
notation vector hj encodes information about the
j-th word with respect to all the other surrounding
where fr is G
We use a
2013) to com
words:
p(yt
ex
where W is
bias of the o
forward neu
that perform
And the sup
umn vector o
The whol
and the deco
(conditional
p(yi|y1, . . . , yi 1, x) = g(yi 1, si, ci),
is an RNN hidden state for time i, computed by
si = f(si 1, yi 1, ci).
be noted that unlike the existing encoder–decoder
ee Eq. (2)), here the probability is conditioned on a dis
ector ci for each target word yi.
ext vector ci depends on a sequence of annotat
hTx
) to which an encoder maps the input sentence. E
n hi contains information about the whole input sequ
ong focus on the parts surrounding the i-th word of
uence. We explain in detail how the annotations are c
(t=i)
[Bahdanau+15]
ncepaperatICLR2015
trainedtopredictthenextwordyt0giventhecontextvectorcandallthe
ords{y1,···,yt01}.Inotherwords,thedecoderdefinesaprobabilityover
composingthejointprobabilityintotheorderedconditionals:
p(y)=
TY
t=1
p(yt|{y1,···,yt1},c),(2)
Ty
.WithanRNN,eachconditionalprobabilityismodeledas
p(yt|{y1,···,yt1},c)=g(yt1,st,c),(3)
potentiallymulti-layered,functionthatoutputstheprobabilityofyt,andstis
RNN.ItshouldbenotedthatotherarchitecturessuchasahybridofanRNN
lneuralnetworkcanbeused(KalchbrennerandBlunsom,2013).
ALIGNANDTRANSLATE
poseanovelarchitectureforneuralmachinetranslation.Thenewarchitecture
onalRNNasanencoder(Sec.3.2)andadecoderthatemulatessearching
nceduringdecodingatranslation(Sec.3.1).
ERALDESCRIPTION
st
cture,wedefineeachconditionalprobability
...,yi1,x)=g(yi1,si,ci),(4)
iddenstatefortimei,computedby
si=f(si1,yi1,ci).
atunliketheexistingencoder–decoderap-
eretheprobabilityisconditionedonadistinct
achtargetwordyi.
idependsonasequenceofannotations
nedtopredictthenextwordyt0giventhecontextvectorcandallthe
s{y1,···,yt01}.Inotherwords,thedecoderdefinesaprobabilityover
posingthejointprobabilityintotheorderedconditionals:
p(y)=
TY
t=1
p(yt|{y1,···,yt1},c),(2)
.WithanRNN,eachconditionalprobabilityismodeledas
p(yt|{y1,···,yt1},c)=g(yt1,st,c),(3)
entiallymulti-layered,functionthatoutputstheprobabilityofyt,andstis
N.ItshouldbenotedthatotherarchitecturessuchasahybridofanRNN
uralnetworkcanbeused(KalchbrennerandBlunsom,2013).
LIGNANDTRANSLATE
anovelarchitectureforneuralmachinetranslation.Thenewarchitecture
lRNNasanencoder(Sec.3.2)andadecoderthatemulatessearching
duringdecodingatranslation(Sec.3.1).
ALDESCRIPTION
st
e,wedefineeachconditionalprobability
,yi1,x)=g(yi1,si,ci),(4)
nstatefortimei,computedby
f(si1,yi1,ci).
nliketheexistingencoder–decoderap-
heprobabilityisconditionedonadistinct
targetwordyi.
ependsonasequenceofannotations
encodermapstheinputsentence.Each
ormationaboutthewholeinputsequence
epartssurroundingthei-thwordofthe
inindetailhowtheannotationsarecom-
atICLR2015
predictthenextwordyt0giventhecontextvectorcandallthe
···,yt01}.Inotherwords,thedecoderdefinesaprobabilityover
thejointprobabilityintotheorderedconditionals:
y)=
TY
t=1
p(yt|{y1,···,yt1},c),(2)
anRNN,eachconditionalprobabilityismodeledas
|{y1,···,yt1},c)=g(yt1,st,c),(3)
multi-layered,functionthatoutputstheprobabilityofyt,andstis
ouldbenotedthatotherarchitecturessuchasahybridofanRNN
tworkcanbeused(KalchbrennerandBlunsom,2013).
ANDTRANSLATE
larchitectureforneuralmachinetranslation.Thenewarchitecture
asanencoder(Sec.3.2)andadecoderthatemulatessearching
decodingatranslation(Sec.3.1).
SCRIPTION
st
efineeachconditionalprobability
x)=g(yi1,si,ci),(4)
fortimei,computedby
1,yi1,ci).
theexistingencoder–decoderap-
abilityisconditionedonadistinct
ordyi.
onasequenceofannotations
dictthenextwordyt0giventhecontextvectorcandallthe
,yt01}.Inotherwords,thedecoderdefinesaprobabilityover
ejointprobabilityintotheorderedconditionals:
=
TY
t=1
p(yt|{y1,···,yt1},c),(2)
NN,eachconditionalprobabilityismodeledas
y1,···,yt1},c)=g(yt1,st,c),(3)
ulti-layered,functionthatoutputstheprobabilityofyt,andstis
ldbenotedthatotherarchitecturessuchasahybridofanRNN
rkcanbeused(KalchbrennerandBlunsom,2013).
DTRANSLATE
rchitectureforneuralmachinetranslation.Thenewarchitecture
anencoder(Sec.3.2)andadecoderthatemulatessearching
codingatranslation(Sec.3.1).
IPTION
st
neeachconditionalprobability
g(yi1,si,ci),(4)
timei,computedby
i1,ci).
existingencoder–decoderap-
ilityisconditionedonadistinct
dyi.
nasequenceofannotations
mapstheinputsentence.Each
boutthewholeinputsequence
rroundingthei-thwordofthe
lhowtheannotationsarecom-
p(yt | {y1, · · · , yt 1} , c) = g(yt 1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt, and st is
the hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNN
and a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architecture
consists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searching
through a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
yt-1
Figure 1: The graphical illus-
tration of the proposed model
trying to generate the t-th tar-
get word yt given a source
sentence (x1, x2, . . . , xT ).
In a new model architecture, we define each conditional probability
in Eq. (2) as:
p(yi|y1, . . . , yi 1, x) = g(yi 1, si, ci), (4)
where si is an RNN hidden state for time i, computed by
si = f(si 1, yi 1, ci).
It should be noted that unlike the existing encoder–decoder ap-
proach (see Eq. (2)), here the probability is conditioned on a distinct
context vector ci for each target word yi.
The context vector ci depends on a sequence of annotations
(h1, · · · , hTx
) to which an encoder maps the input sentence. Each
annotation hi contains information about the whole input sequence
with a strong focus on the parts surrounding the i-th word of the
input sequence. We explain in detail how the annotations are com-
puted in the next section.
The context vector ci is, then, computed as a weighted sum of these
annotations hi:
ci =
TxX
j=1
↵ijhj. (5)
The weight ↵ij of each annotation hj is computed by
↵ij =
exp (eij)
PTx
exp (eik)
, (6)
ptpt-1
c.f. http://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention](https://image.slidesharecdn.com/pointingtheunknownwords-160906225848/85/Pointing-the-Unknown-Words-5-320.jpg)
![•
•
•
• V
a man yesterday . [eos]!
killed a man yesterday .!t
+ bhp) (16)
(17)
Whp
bhp) (16)
(17)
(18)
(19)
!
man
a
a
man !
6
RNN t
pt
pt = softmax(W
ht =
−−−→
RNNt′≺t(
softmax(s)i =
exp(si
sj∈s exp
→
t′≺t(xwt′ ) (17)
p(si)
s exp(sj)
(18)
(19)
s i
Whp ∈ RV ×N
V
bhp(w)
Whp bhp
t = softmax(Whpht + bhp) (16)
t =
−−−→
RNNt′≺t(xwt′ ) (17)
i =
exp(si)
sj∈s exp(sj)
(18)
(19)
s i
Whp ∈ RV ×N
V
Whp(w) bhp(w)
(18)
(19)
i
Whp ∈ RV ×N
V
)
t wt
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
• V T
•
•
•
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
i N s
exp
w Whp ∈ RV ×N
Whp(w) bhp(w)
T
6
RNN t wt
pt
pt = softmax(Whpht + bhp)
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
softmax(s)i N s
exp
6
RNN t wt
pt
pt = softmax(Whpht +
ht =
−−−→
RNNt′≺t(xwt′ )
softmax(s)i =
exp(si)
sj∈s exp(sj)
softmax(s)i N s
exp
・
7](https://image.slidesharecdn.com/pointingtheunknownwords-160906225848/85/Pointing-the-Unknown-Words-7-320.jpg)




![Ø
Ø
Ø
Ø
Ø
Ø
17
improved the convergence speed of the model as
well. For French to English machine translation
on Europarl corpora, we observe that using the
pointer softmax can also improve the training con-
vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, Kyunghyun
Cho, and Yoshua Bengio. 2014. Neural machine
translation by jointly learning to align and translate.
CoRR, abs/1409.0473.
[Bengio and Sen´ecal2008] Yoshua Bengio and Jean-
S´ebastien Sen´ecal. 2008. Adaptive importance
sampling to accelerate training of a neural proba-
bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,
Sumit Chopra, and Jason Weston. 2015. Large-
scale simple question answering with memory net-
works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and Mirella
Lapata. 2016. Neural summarization by ex-
plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-
qing Ren, and Jian Sun. 2015. Deep resid-
ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, Tomas
Kocisky, Edward Grefenstette, Lasse Espeholt, Will
Kay, Mustafa Suleyman, and Phil Blunsom. 2015.
Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,
pages 1684–1692.
[Jean et al.2014] S´ebastien Jean, Kyunghyun Cho,
Roland Memisevic, and Yoshua Bengio. 2014. On
using very large target vocabulary for neural ma-
chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma and
Jimmy Ba Adam. 2015. A method for stochastic
optimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,
Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.
2015. Addressing the rare word problem in neural
machine translation. In Proceedings of ACL.
148
[Schuster and Paliwal1997] Mike Schuster and
Kuldip K Paliwal. 1997. Bidirectional recur-
rent neural networks. Signal Processing, IEEE
Transactions on, 45(11):2673–2681.
[Sennrich et al.2015] Rico Sennrich, Barry Haddow,
and Alexandra Birch. 2015. Neural machine trans-
lation of rare words with subword units. arXiv
preprint arXiv:1508.07909.
[Theano Development Team2016] Theano Develop-
ment Team. 2016. Theano: A Python framework
for fast computation of mathematical expressions.
arXiv e-prints, abs/1605.02688, May.
[Tomasello et al.2007] Michael Tomasello, Malinda
Carpenter, and Ulf Liszkowski. 2007. A new look at
infant pointing. Child development, 78(3):705–722.
[Vinyals et al.2015] Oriol Vinyals, Meire Fortunato,
and Navdeep Jaitly. 2015. Pointer networks. In Ad-
vances in Neural Information Processing Systems,
pages 2674–2682.
[Zeiler2012] Matthew D Zeiler. 2012. Adadelta:
an adaptive learning rate method. arXiv preprint
arXiv:1212.5701.
7 Acknowledgments
We would also like to thank the developers of
Theano 5, for developing such a powerful tool
5
http://deeplearning.net/software/
theano/
149
able to improve the results even when it is used
together with the large-vocabulary trick. In the
case of neural machine translation, we observed
that the training with the pointer softmax is also
improved the convergence speed of the model as
well. For French to English machine translation
on Europarl corpora, we observe that using the
pointer softmax can also improve the training con-
vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, Kyunghyun
Cho, and Yoshua Bengio. 2014. Neural machine
translation by jointly learning to align and translate.
CoRR, abs/1409.0473.
[Bengio and Sen´ecal2008] Yoshua Bengio and Jean-
S´ebastien Sen´ecal. 2008. Adaptive importance
sampling to accelerate training of a neural proba-
bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,
Sumit Chopra, and Jason Weston. 2015. Large-
scale simple question answering with memory net-
works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and Mirella
Lapata. 2016. Neural summarization by ex-
2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyv¨arinen2012] Michael U Gutmann
and Aapo Hyv¨arinen. 2012. Noise-contrastive esti-
mation of unnormalized statistical models, with ap-
plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-
qing Ren, and Jian Sun. 2015. Deep resid-
ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, Tomas
Kocisky, Edward Grefenstette, Lasse Espeholt, Will
Kay, Mustafa Suleyman, and Phil Blunsom. 2015.
Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,
pages 1684–1692.
[Jean et al.2014] S´ebastien Jean, Kyunghyun Cho,
Roland Memisevic, and Yoshua Bengio. 2014. On
using very large target vocabulary for neural ma-
chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma and
Jimmy Ba Adam. 2015. A method for stochastic
optimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,
Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.
2015. Addressing the rare word problem in neural
machine translation. In Proceedings of ACL.
148
lidation learning-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, Bart
Van Merri¨enboer, Caglar Gulcehre, Dzmitry
Bahdanau, Fethi Bougares, Holger Schwenk,
and Yoshua Bengio. 2014. Learning phrase
representations using rnn encoder-decoder for
statistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, C¸ aglar G¨ulc¸ehre,
KyungHyun Cho, and Yoshua Bengio. 2014. Em-
pirical evaluation of gated recurrent neural networks
on sequence modeling. CoRR, abs/1412.3555.
n learning-
ined with
layer. As
el trained
an the reg-
or pointer
tion func-
ble to gen-
with rare-
marization
ftmax was
it is used
k. In the
observed
ax is also
model as
ranslation
using the
ining con-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, Bart
Van Merri¨enboer, Caglar Gulcehre, Dzmitry
Bahdanau, Fethi Bougares, Holger Schwenk,
and Yoshua Bengio. 2014. Learning phrase
representations using rnn encoder-decoder for
statistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, C¸ aglar G¨ulc¸ehre,
KyungHyun Cho, and Yoshua Bengio. 2014. Em-
pirical evaluation of gated recurrent neural networks
on sequence modeling. CoRR, abs/1412.3555.
[Gillick et al.2015] Dan Gillick, Cliff Brunk, Oriol
Vinyals, and Amarnag Subramanya. 2015. Mul-
tilingual language processing from bytes. arXiv
preprint arXiv:1512.00103.
[Graves2013] Alex Graves. 2013. Generating se-
quences with recurrent neural networks. arXiv
preprint arXiv:1308.0850.
[Gu et al.2016] Jiatao Gu, Zhengdong Lu, Hang Li,
and Victor OK Li. 2016. Incorporating copying
mechanism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
[Gulcehre et al.2016] Caglar Gulcehre, Marcin
Moczulski, Misha Denil, and Yoshua Bengio.
2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyv¨arinen2012] Michael U Gutmann
and Aapo Hyv¨arinen. 2012. Noise-contrastive esti-
mation of unnormalized statistical models, with ap-
plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-
qing Ren, and Jian Sun. 2015. Deep resid-
ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, Tomas
Kocisky, Edward Grefenstette, Lasse Espeholt, Will
[Morin and Bengio2005] Frederic Morin and Yoshua
Bengio. 2005. Hierarchical probabilistic neural net-
work language model. In Aistats, volume 5, pages
246–252. Citeseer.
[Pascanu et al.2012] Razvan Pascanu, Tomas Mikolov,
and Yoshua Bengio. 2012. On the difficulty of
training recurrent neural networks. arXiv preprint
arXiv:1211.5063.
[Pascanu et al.2013] Razvan Pascanu, Caglar Gulcehre,
Kyunghyun Cho, and Yoshua Bengio. 2013. How
to construct deep recurrent neural networks. arXiv
preprint arXiv:1312.6026.
[Rush et al.2015] Alexander M. Rush, Sumit Chopra,
and Jason Weston. 2015. A neural attention model
for abstractive sentence summarization. CoRR,
abs/1509.00685.
[Schuster and Paliwal1997] Mike Schuster and
Kuldip K Paliwal. 1997. Bidirectional recur-
rent neural networks. Signal Processing, IEEE
Transactions on, 45(11):2673–2681.
[Sennrich et al.2015] Rico Sennrich, Barry Haddow,
and Alexandra Birch. 2015. Neural machine trans-
lation of rare words with subword units. arXiv
preprint arXiv:1508.07909.
[Theano Development Team2016] Theano Develop-
ment Team. 2016. Theano: A Python framework
for fast computation of mathematical expressions.
arXiv e-prints, abs/1605.02688, May.
[Tomasello et al.2007] Michael Tomasello, Malinda
Carpenter, and Ulf Liszkowski. 2007. A new look at
infant pointing. Child development, 78(3):705–722.
[Vinyals et al.2015] Oriol Vinyals, Meire Fortunato,
and Navdeep Jaitly. 2015. Pointer networks. In Ad-
vances in Neural Information Processing Systems,
pages 2674–2682.
[Zeiler2012] Matthew D Zeiler. 2012. Adadelta:
an adaptive learning rate method. arXiv preprint
arXiv:1212.5701.
7 Acknowledgments
We would also like to thank the developers of
5
ranslation
using the
ining con-
Kyunghyun
al machine
d translate.
and Jean-
importance
ural proba-
orks, IEEE
as Usunier,
5. Large-
emory net-
nd Mirella
on by ex-
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-
qing Ren, and Jian Sun. 2015. Deep resid-
ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, Tomas
Kocisky, Edward Grefenstette, Lasse Espeholt, Will
Kay, Mustafa Suleyman, and Phil Blunsom. 2015.
Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,
pages 1684–1692.
[Jean et al.2014] S´ebastien Jean, Kyunghyun Cho,
Roland Memisevic, and Yoshua Bengio. 2014. On
using very large target vocabulary for neural ma-
chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma and
Jimmy Ba Adam. 2015. A method for stochastic
optimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,
Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.
2015. Addressing the rare word problem in neural
machine translation. In Proceedings of ACL.
148
Management of Data (SIGMOD). pages 1247–
1250.
S. Bowman, G. Angeli, C. Potts, and C. D. Man-
ning. 2015. A large annotated corpus for learn-
ing natural language inference. In Empiri-
cal Methods in Natural Language Processing
(EMNLP).
D. L. Chen and R. J. Mooney. 2008. Learning to
sportscast: A test of grounded language acqui-
sition. In International Conference on Machine
Learning (ICML). pages 128–135.
F. Chevalier, R. Vuillemot, and G. Gali. 2013. Us-
ing concrete scales: A practical framework for
effective visual depiction of complex measures.
IEEE Transactions on Visualization and Com-
puter Graphics 19:2426–2435.
G. Chiacchieri. 2013. Dictionary of numbers.
http://www.dictionaryofnumbers.
com/.
A. Fader, S. Soderland, and O. Etzioni. 2011.
Identifying relations for open information ex-
traction. In Empirical Methods in Natural Lan-
guage Processing (EMNLP).
R. Jia and P. Liang. 2016. Data recombination
for neural semantic parsing. In Association for
Computational Linguistics (ACL).
M. G. Jones and A. R. Taylor. 2009. Developing
a sense of scale: Looking backward. Journal of
Research in Science Teaching 46:460–475.
Y. Kim, J. Hullman, and M. Agarwala. 2016. Gen-
erating personalized spatial analogies for dis-
tances and areas. In Conference on Human Fac-
tors in Computing Systems (CHI).
C. Seife. 2010. Proofine
fooled by the numbers. P
I. Sutskever, O. Vinyals, a
quence to sequence lea
works. In Advances in N
cessing Systems (NIPS).
K. H. Teigen. 2015. Fram
ties. The Wiley Blackw
ment and Decision Maki
T. R. Tretter, M. G. Jones,
Accuracy of scale conce
tal maneuverings acros
tial magnitude. Journal
Teaching 43:1061–1085
Y. Wang, J. Berant, and P.
a semantic parser overni
Computational Linguisti
Y. W. Wong and R. J. Moo
by inverting a semantic
cal machine translation.
Technology and North
for Computational Ling
pages 172–179.](https://image.slidesharecdn.com/pointingtheunknownwords-160906225848/85/Pointing-the-Unknown-Words-17-320.jpg)




![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...](https://cdn.slidesharecdn.com/ss_thumbnails/paclingpresen-191012011632-thumbnail.jpg?width=640&height=640&fit=bounds)





























