Downloaded 17 times

















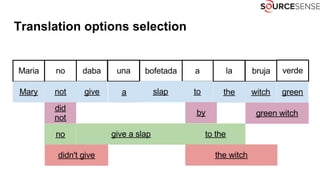

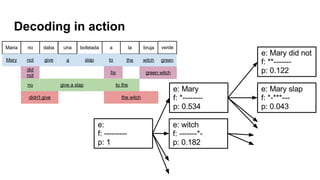

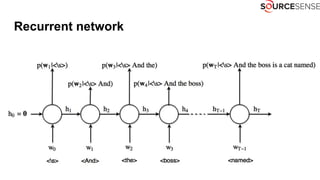

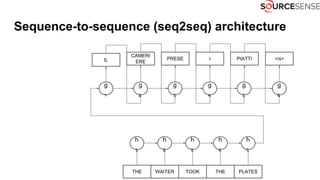

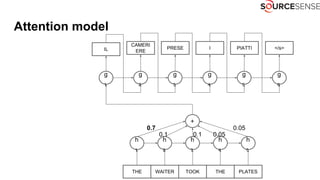
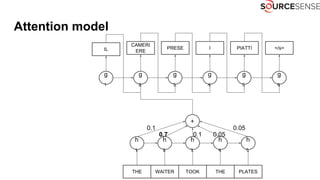
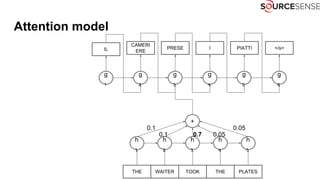

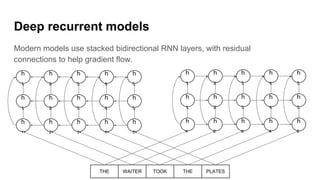



The document discusses deep learning's impact on machine translation, detailing the evolution from statistical to neural machine translation, and introduces concepts like language models, translation models, and the attention mechanism. It explains how probabilistic methods and architectures, such as encoder-decoder and attention models, facilitate improved translation through advanced training techniques. Additionally, it mentions future directions for machine translation, including online adaptation and zero-shot translation.











![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[Sponsored] C3.ai description](https://cdn.slidesharecdn.com/ss_thumbnails/c3deckmeetupnovember252019v2-191128092146-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)






















