The document covers a machine learning module focused on reinforcement learning, detailing its principles, including how agents learn through feedback to maximize rewards. Key concepts such as positive and negative reinforcement, Q-learning, and the credit assignment problem are discussed, alongside algorithms used in AI applications. Additionally, the document includes examples and mathematical formulations for Q-value updates and explores the interplay between exploration and exploitation in reinforcement learning.



![Cont…
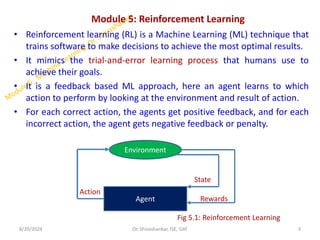
• The agent can take any path to reach to the final point, but he needs to make
it in possible fewer steps. Suppose the agent considers the path S9-S5-S1-S2-
S3, so he will get the +1-reward point.
• Action performed by the agent is referred to as "a"
• State occurred by performing the action is "s."
• The reward/feedback obtained for each good and bad action is "R."
• A discount factor is Gamma "γ."
V(s) = max [R(s,a) + γV(s`)]
8/20/2024 5
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-5-320.jpg)
![Cont…
• V(s)= value calculated at a particular point.
• R(s,a) = Reward at a particular state s by performing an action.
• γ = Discount factor
• V(s`) = The value at the previous state.
How to represent the agent state?
• We can represent the agent state using the Markov State that contains all
the required information from the history. The State St is Markov state if it
follows the given condition:
P[St+1 | St ] = P[St +1 | S1,......, St]
• tuple of four elements (S, A, Pa, Ra):
• A set of finite States S
• A set of finite Actions A
• Rewards received after transitioning from state S to state S', due to action
a.
• Probability Pa.
8/20/2024 6
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-6-320.jpg)




![Q-learning
2. Q-value Update Rule:
The Q-values are updated using the formula:
𝑄(𝑠,𝑎)←𝑄(𝑠,𝑎)+𝛼[𝑟+𝛾max (𝑄(𝑠′,𝑎′)−𝑄(𝑠,𝑎))]
Q(s,a) = r(s,a) + 𝛼*max (𝑄(𝛿(s,a), ƴ
𝑎))
Where :
𝑠 is the current state,
𝑎 is the action taken,
r is the reward received after taking action 𝑎 in state 𝑠,
𝑠′ is the new state after action,
𝑎′ is any possible action from the new state 𝑠′,
𝛼 is the learning rate (0 < α ≤ 1),
𝛾 is the discount factor (0 ≤ γ < 1).
8/20/2024 13
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-13-320.jpg)



![Cont…
Q(state, action)= R(state, action) + Alpha * Max[Q(next state, all action)]
Q(s,a) = r(s,a) + 𝛼*max [𝑄(𝛿(s,a), ƴ
𝑎)]
At state 3: Q(2,3) = R(2,3) + 0.9 * max [Q(3,3)]
= 100 + 0.9 * max [0]
= 100 + 0 = 100
Q(6,3) = R(6,3) + 0.9 * max [Q(3,3)]
= 100 + 0.9 * max [0]
= 100 + 0 = 100
At state 2: Q(1,2) = R(1,2) + 0.9 * max [Q(2,3), Q(2,5)]
= 0 + 0.9 * max [100,0]
= 0.9*100 = 90
At state 1: Q(2,1) = R(2,1) + 0.9 * max [Q(1,2), Q(1,4)]
= 0 + 0.9 * max [90,0]
= 0.9*90 = 81
Q(4,1) = R(4,1) + 0.9 * max [Q(1,2), Q(1,4)]
= 0 + 0.9 * max [90,0]
= 0.9*90=81
8/20/2024 17
Dr. Shivashankar, ISE, GAT
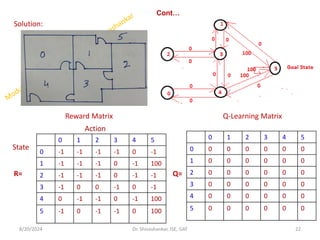
Sate transition diagram](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-17-320.jpg)
![Cont…
At state 4: Q(1,4) = R(1,4) + 0.9 * max [Q(4,1), Q(4,5)]
= 0 + 0.9 * max [81,0]
= 0.9*81 = 72
At state 2: Q(5,2) = R(5,2) + 0.9 * max [Q(2,1), Q(2,3), Q(2,5)]
= 0 + 0.9 * max [81,100,0]
= 0.9*100 = 90
At state 4: Q(5,4) = R(5,4) + 0.9 * max [Q(4,1), Q(4,5)]
= 0 + 0.9 * max [81,0]
= 0.9*81 = 72
At state 5: Q(2,5) = R(2,5) + 0.9 * max [Q(5,2), Q(5,4), Q(5,6)]
= 0 + 0.9 * max [90, 72, 0]
= 0.9*90 = 81
Q(4,5) = R(4,5) + 0.9 * max [Q(5,2), Q(5,4), Q(5,6)]
= 0 + 0.9 * max [90, 72, 0]
= 0.9*90 = 81
8/20/2024 18
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-18-320.jpg)
![Cont…
At state 5: Q(6,5) = R(6,5) + 0.9 * max [Q(5,2), Q(5,4), Q(5,6)]
= 0 + 0.9 * max [90, 72, 0]
= 0.9*90 = 81
At state 6: Q(5,6) = R(5,6) + 0.9 * max [Q(6,3), Q(6,5)]
= 0 + 0.9 * max [100,81]
= 0.9*100 = 90
8/20/2024 19
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-19-320.jpg)
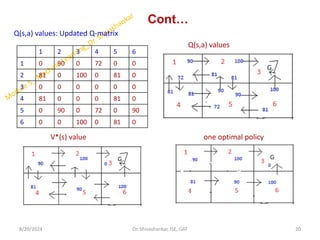

![Cont…
• Now let’s imagine what would happen if our agent were in state 5 (next state)
• Look at the 6th row of the reward matrix R(i.e. state 5)
• It has 3 possible actions: go to state 1,4, or 5.
Q(s,a) = r(s,a) + 𝛼*max [𝑄(𝛿(s,a), ƴ
𝑎)]
Q(state, action)= R(state, action) + Alpha * max[Q(next state, all action)]
At state 5:
Q(1,5) = R(1,5) + 0.8 * max [Q(5,1), Q(5,4)]
= 100 + 0.8 * max [Q(0,0)]
= 100 + 0.8*0 = 100
Q(4,5) = R(4,5) + 0.8 * max [Q(5,1), Q(5,4)]
= 100 + 0.8 * max [0,0]= 100
At state 1:
Now we imagine that we are in state 1(next state).
It has 2 possible actions: go to state 3 or state 5.
Then, we complete the Q value:
Q(3,1) = R(3,1) +0.8*Max(Q[1,3), Q(1,5)]
= 0 + 0.8 * max [0,100]
= 0 + 0.8*max(0,100) = 80
8/20/2024 23
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-23-320.jpg)
![Cont…
Q(5,1) = R(5,1) + 0.8*max (Q(1,3), Q(1,5)]
= 0 + 0.8* max(64,100)]
0.8*100 = 80
At state 3:
Q(1,3) = R(1,3) + 0.8 * max [Q(3,1), Q(3,2), Q(3,4)]
= 0 + 0.8 * max [80, 0, 0]
= 0+ 0.8*80 = 64
Q(4,3) = R(4,3) + 0.8 * max [Q(3,4), Q(3,2), Q(3,1)]
= 0 + 0.8 * max [0, 0, 80]
= 0+ 0.8*80 = 64
Q(2,3) = R(2,3) + 0.8 * max [Q(3,2), Q(3,1), Q(3,4)]
= 0 + 0.8 * max [0, 80, 0]
= 0+ 0.8*80 = 64
At state 4:
Q(5, 4) = R(5, 4) + 0.8 * max [Q(4,5), Q(4,3), Q(4, 0)]
= 0 + 0.8 * max [100, 64, 0]
= 80
8/20/2024 24
Dr. Shivashankar, ISE, GAT](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-24-320.jpg)
![Cont…
Q(3, 4) = R(3, 4) + 0.8 * max [Q(4,3), Q(4,5), Q(4, 0)]
= 0 + 0.8 * max [64,100, 0]= 80
Q(0, 4) = R(0, 4) + 0.8 * max [Q(4,0), Q(4,3), Q(4,5)]
= 0 + 0.8 * max [0, 0, 100] = 80
At state 2:
Q(3,2) = R(3,2) + 0.8*max[ Q(2,3)]
= 0 + 0.8*max[64] = 51
At state 0:
Q(4, 0) = R(4,0) + 0.8*max[Q(0,4)]
= 0 + 0.8 * 80 = 64
8/20/2024 25
Dr. Shivashankar, ISE, GAT
0 1 2 3 4 5
0 0 0 0 0 80 0
1 0 0 0 64 0 100
2 0 0 0 64 0 0
3 0 80 51 0 80 0
4 64 0 0 64 0 100
5 0 80 0 0 80 100
Updated state diagram
Final Updated Q-Learning Matrix](https://image.slidesharecdn.com/5thmodulemachinelearning-240820085428-b53c18df/85/5th-Module_Machine-Learning_Reinforc-pdf-25-320.jpg)
























































































