Download as PDF, PPTX











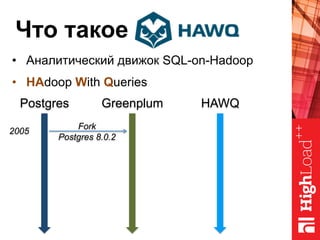
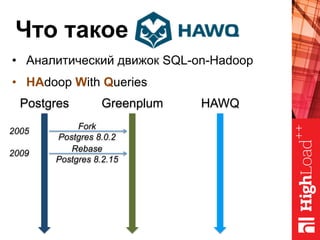
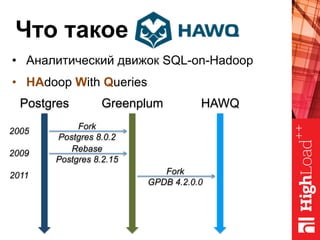
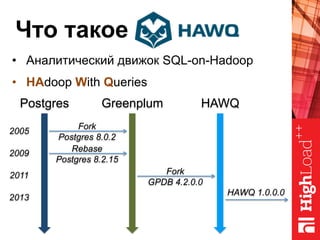
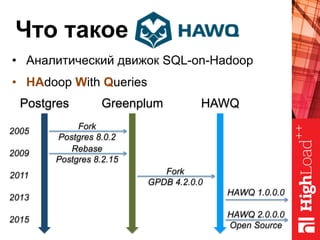
















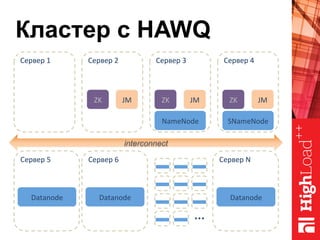
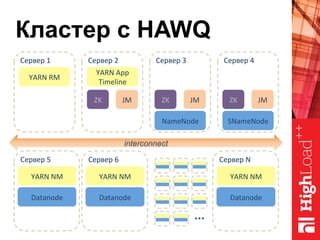
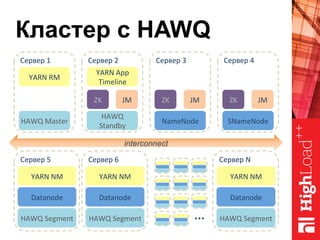
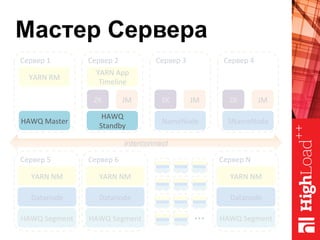
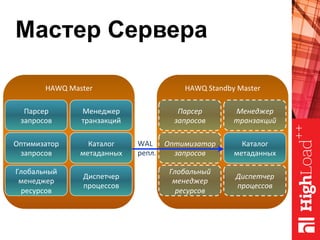
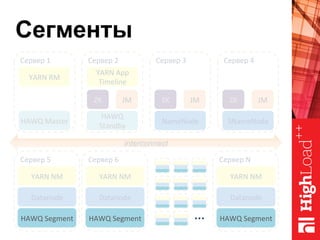
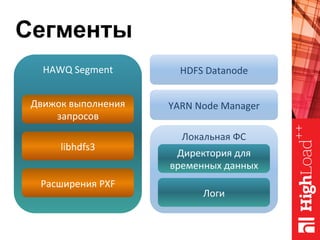
























































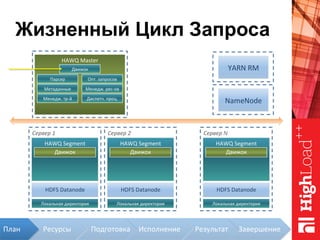
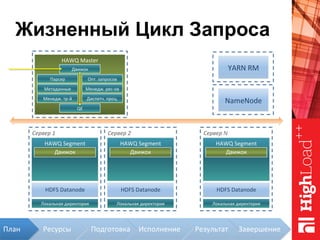
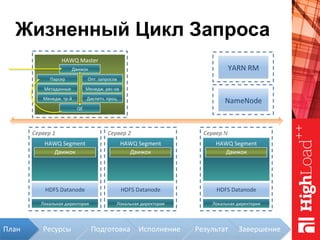
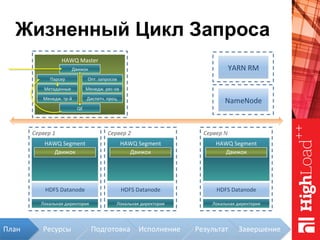
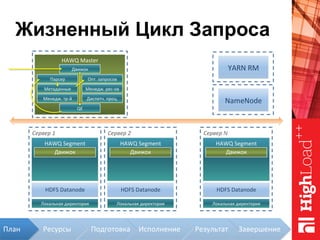
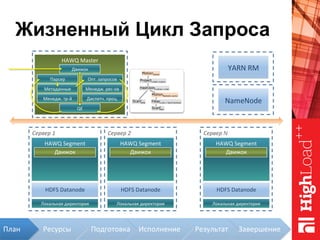
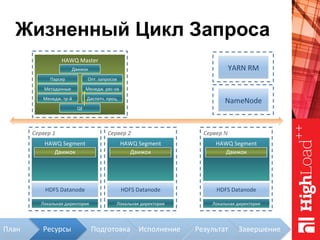
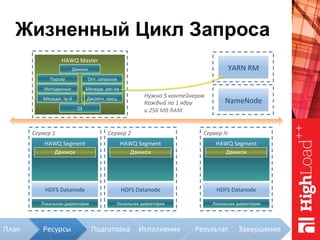
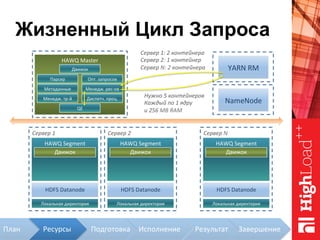
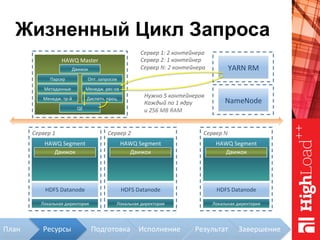
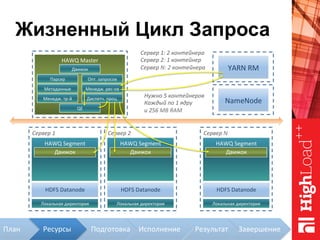
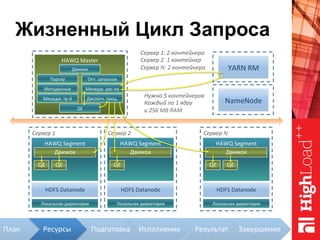
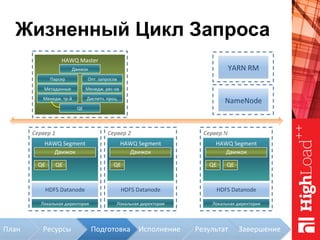
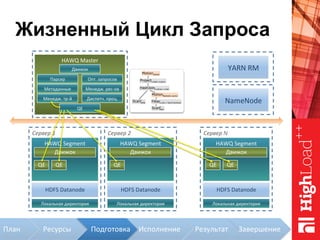
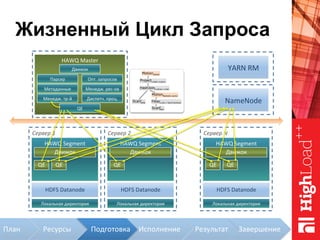
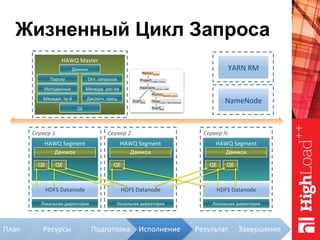
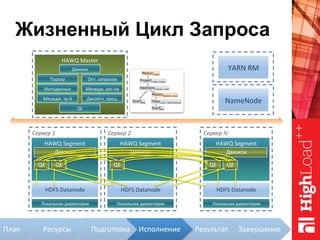
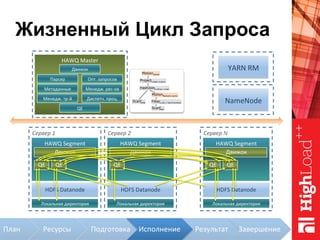
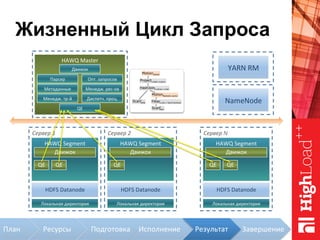
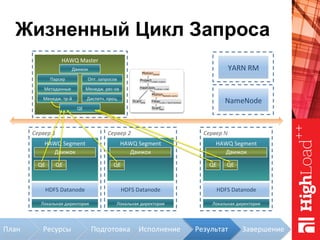
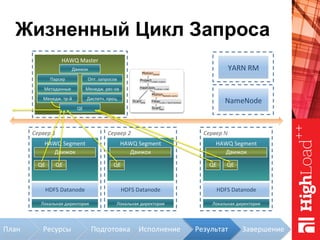
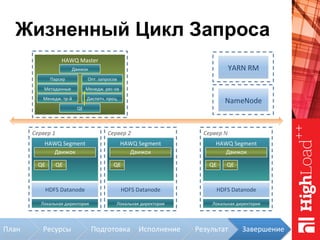
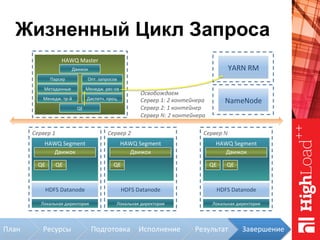
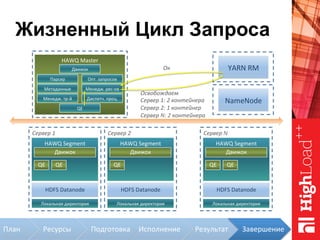
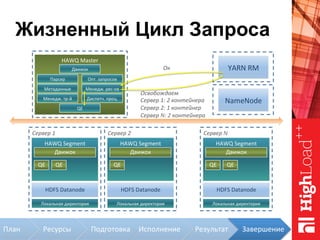
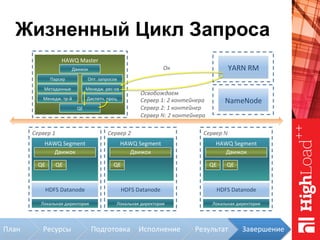
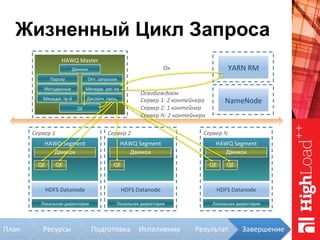
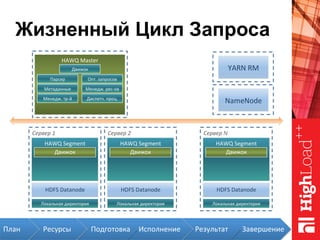













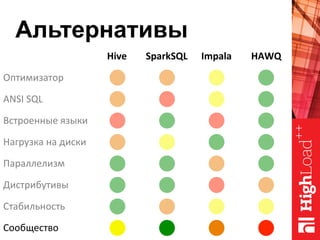








Документ описывает архитектуру HAWQ, системы обработки данных на базе Hadoop, и ее компоненты, включая разъяснение работы, полезность и примеры использования. Также представлена информация о развитии HAWQ, ее кодовой базе и продуктивности. Внимание уделяется аналитическим возможностям и SQL-интерфейсу для бизнес-аналитики с различными примерами применения.























































































