Download as PDF, PPTX








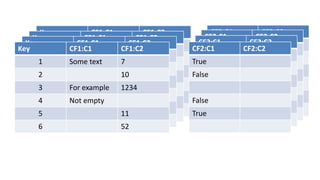


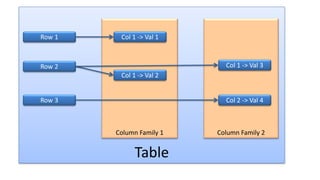


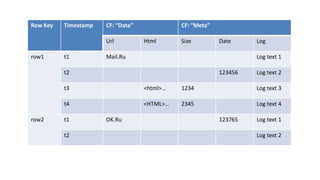

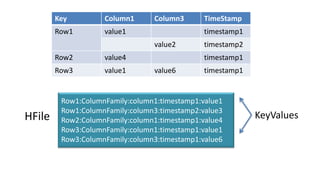

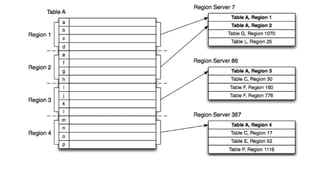
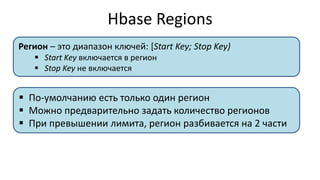

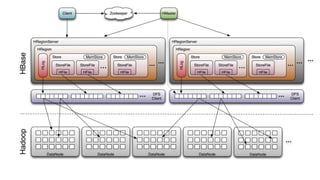

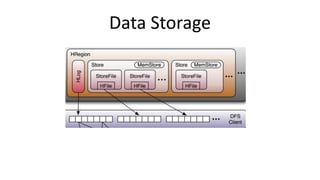









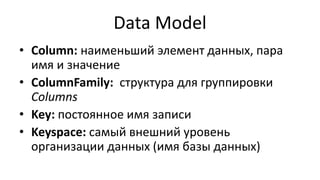
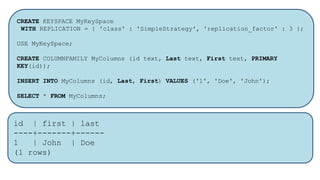
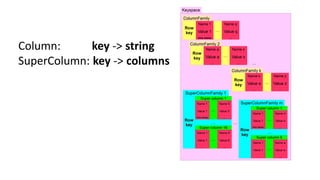




HBase - это распределенная NoSQL база данных, оптимизированная для работы с большими объемами данных и разработанная на базе идей Google Bigtable. Она поддерживает произвольные операции чтения и записи, свободную схему данных и масштабируемость, достигаемую с помощью шардирования и автоматического восстановления. HBase также использует семейства колонок для управления свойствами данных и позволяет хранить версии данных с временными метками.



































































