Download as PDF, PPTX












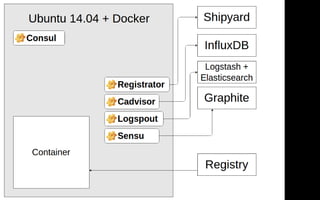









![Router
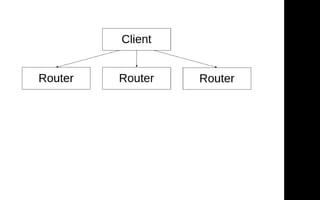
{
"route": "/api/1.0/some/method",
"chain": [
...
]
}
42](https://image.slidesharecdn.com/highload2015-2-151222064205/85/PHP-Scala-2-42-320.jpg)
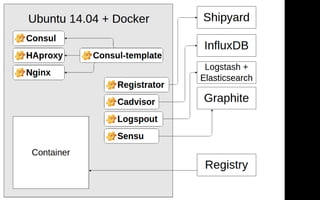
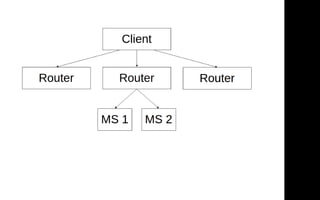
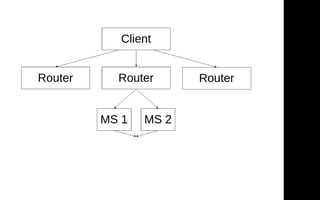
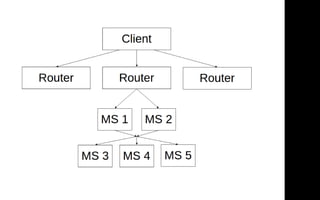
![Router chain
{ "key": "ms4",
"method": "/api/0.0.1/ms4",
"data": {},
"timeout": 2000,
"maxRetries": 0,
"isVital": true,
"waitFor": ["ms1", "ms2"] }
43](https://image.slidesharecdn.com/highload2015-2-151222064205/85/PHP-Scala-2-43-320.jpg)








![Spray
path("api" / "1.0" / "some" / "method") {
parameters('id.as[String]) { id =>
val response = DoSomeWork(id)
onSuccess(response) { content =>
complete(content)
}
}
}
01.
02.
03.
04.
05.
06.
07.
08.
60](https://image.slidesharecdn.com/highload2015-2-151222064205/85/PHP-Scala-2-60-320.jpg)
![Spray json
case class User(name: String, isOk: Boolean)
implicit val UserFormatter = jsonFormat2(User)
val json = """{"name": "Denis", "isOk": true}"""
val user = json.parseJson.convertTo[User]
01.
02.
03.
04.
05.
06.
07.
61](https://image.slidesharecdn.com/highload2015-2-151222064205/85/PHP-Scala-2-61-320.jpg)









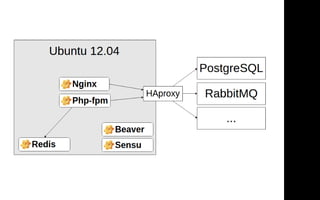
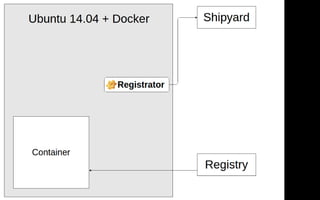
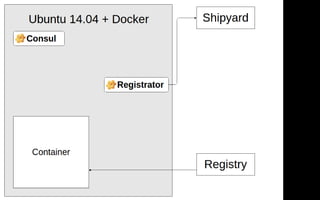
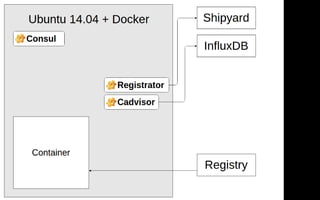
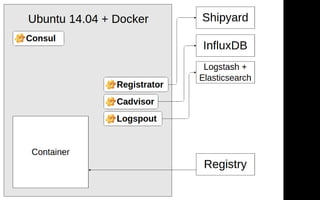
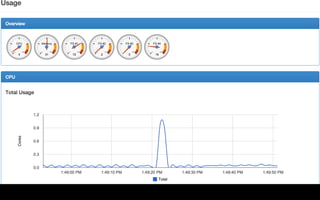
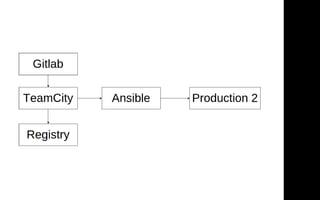
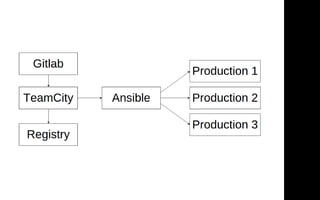
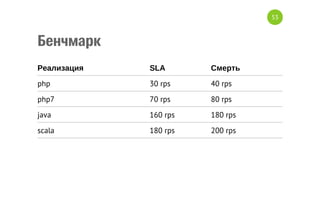
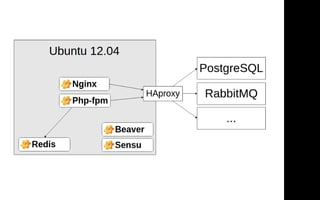
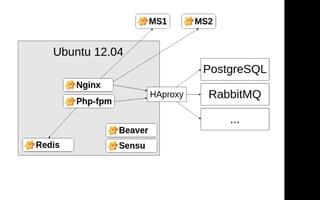
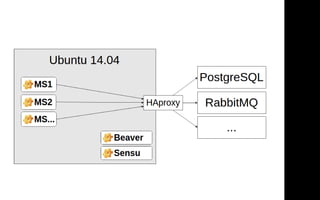
Документ описывает переход от монолитной архитектуры на PHP к микросервисам на Scala в компании 2GIS. В ходе анализа выделены проблемы текущего приложения, предложены решения и описаны методы разбиения системы на микросервисы, включая примеры технологий и инструментов. Уделяется внимание тестированию и оптимизации разработки с целью повышения производительности и уменьшения времени на развертывание.



































































