Download to read offline


![Gray hat
ACM
CTF, freelance
Senior
Team lead
Chef Technical Officer
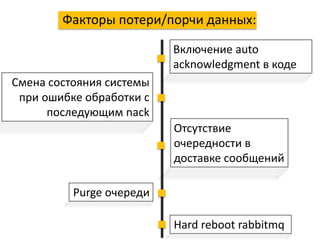
Автор журнала ][akep](https://image.slidesharecdn.com/a11-50menshikov-171018185250/85/10-highload-2-320.jpg)










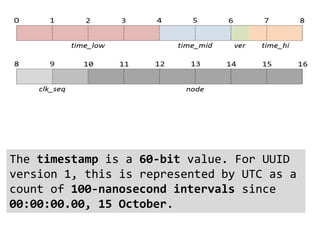

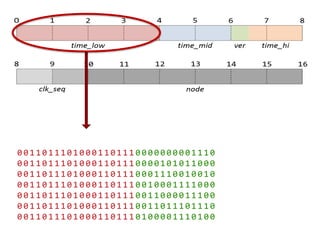






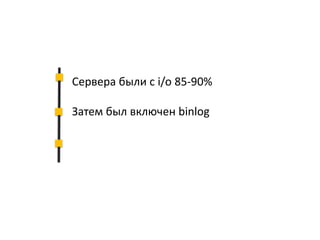













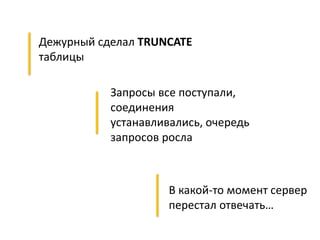


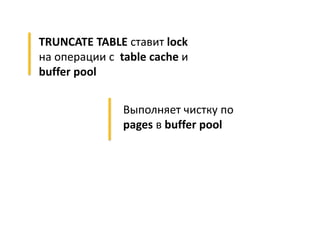
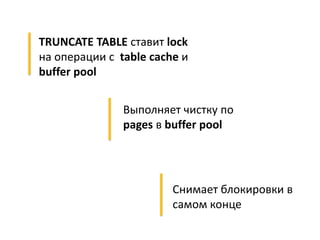










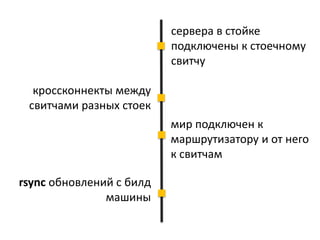






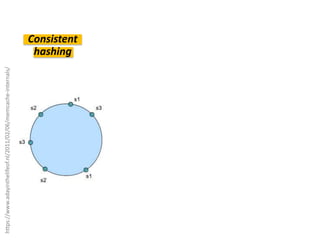
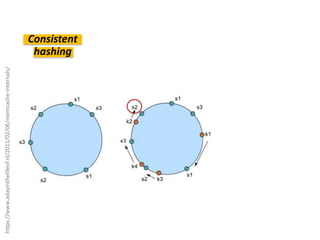
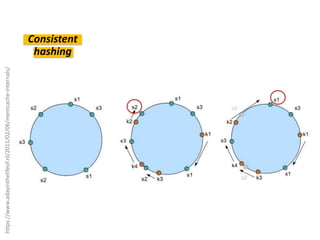
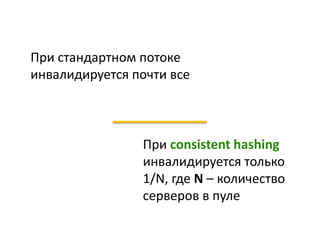

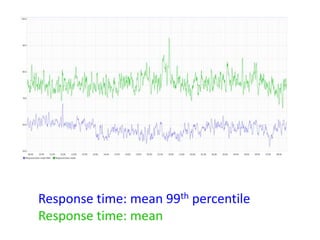
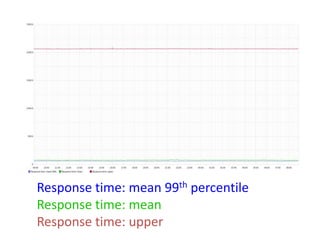

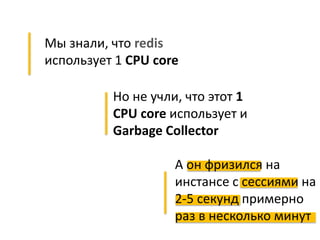







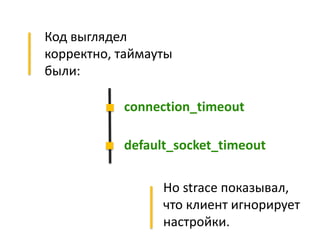





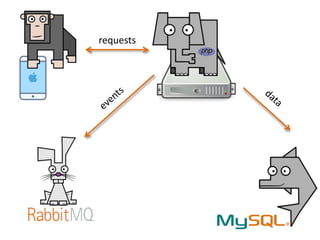
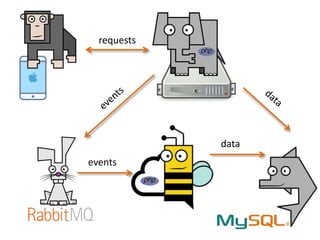





Документ описывает опыт и проблемы, возникшие в процессе разработки и эксплуатации высоконагруженного проекта, включая ошибки в выборе идентификаторов пользователя, сложности с MySQL и Redis, а также последствия неправильной архитектуры системы. Приводятся примеры сбоев, таких как зависание серверов и потеря данных, а также предлагаются решения и рекомендации по управлению нагрузкой. Автор подчеркивает важность тщательной проверки внедряемых решений и мониторинга метрик для успешного управления высоконагруженными системами.



































































