Downloaded 25 times












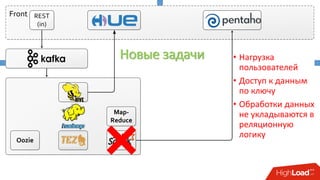






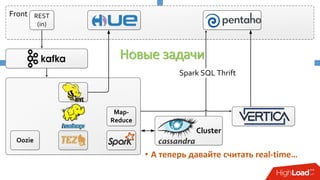

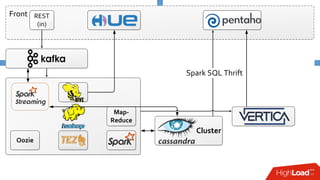











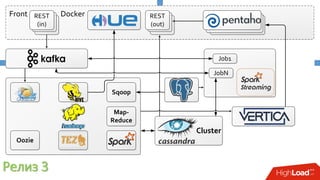





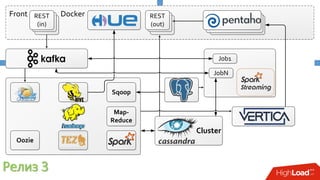







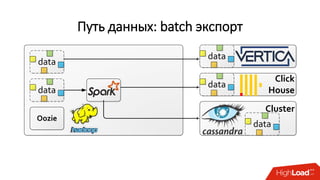


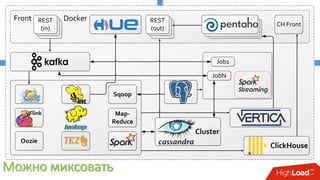
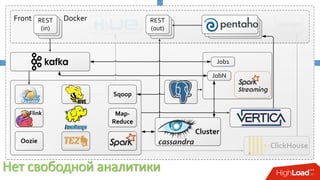
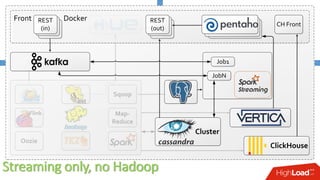








Документ описывает опыт внедрения современных технологий в логистическую инфраструктуру компании BigПочта, включая обработку данных и построение отказоустойчивой системы. Основное внимание уделяется использованию различных инструментов, таких как Spark, Kafka, и ClickHouse для обработки и аналитики данных, а также критическим вопросам масштабируемости и доступности. Также рассматриваются проблемы и решения, связанные с потоковой переработкой данных и поддержкой высокой нагрузки пользователей.



































































