Download as PDF, PPTX








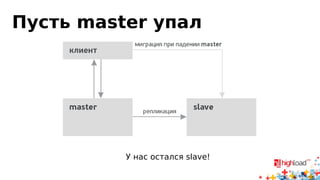
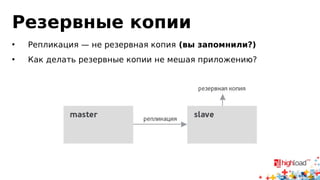
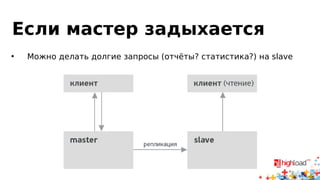
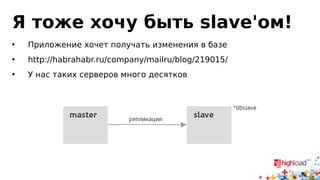
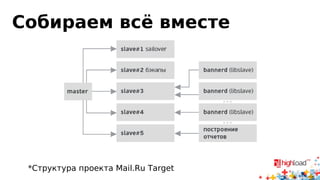


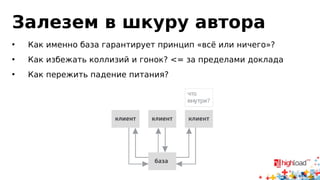


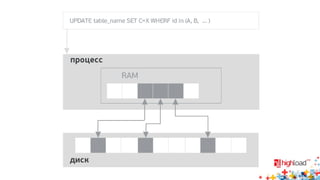

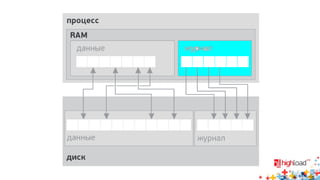

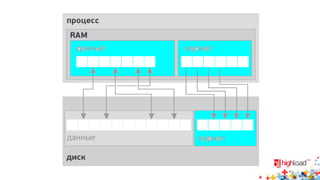



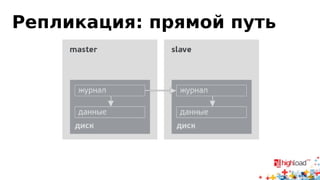
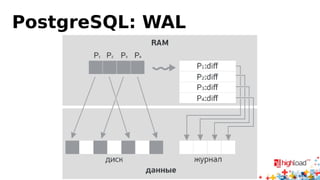

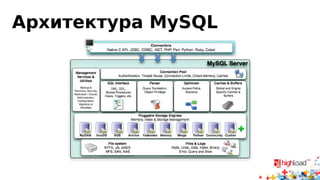






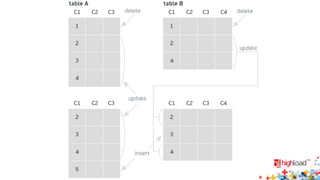


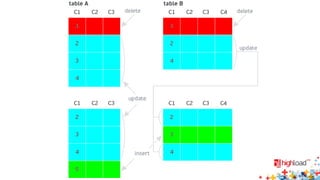

































Документ посвящен асинхронной репликации в MySQL и сопоставлению с PostgreSQL, обсуждая плюсы и минусы различных подходов и архитектурные проблемы. Рассматриваются ключевые аспекты, такие как целостность данных, различия в логировании и производительность репликации, а также вопросы резервного копирования. Автор делится опытом эксплуатации MySQL в крупных проектах и делится рекомендациями по настройке репликации для достижения высокой производительности.
















































































