The document discusses the complexities of string representation in computing, focusing on character encoding and how it evolved from ASCII to Unicode and its various transformation formats like UTF-8, UTF-16, and UTF-32. It highlights the issues of interoperability and accuracy when handling multi-byte characters and the discrepancies in string methods across programming languages. Ultimately, it emphasizes the importance of understanding string lengths, graphemes, and code points in order to effectively manage text data.



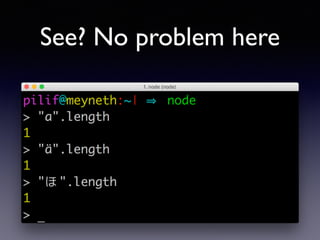
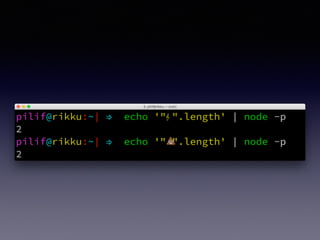







































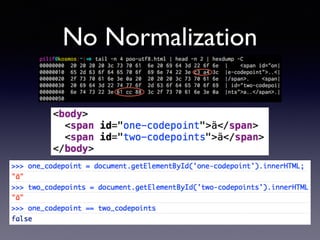
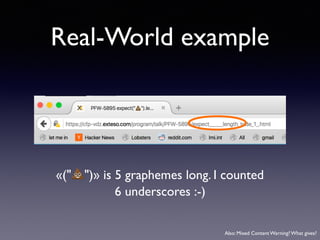

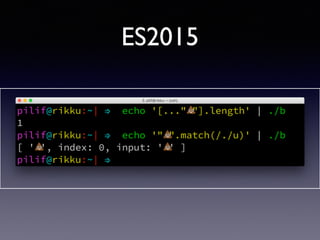




!["#".length
[…"#"].length](https://image.slidesharecdn.com/unicode2-160303133111/85/expect-length-toBe-1-52-320.jpg)





![Cross plataform development with mono [fonts]](https://cdn.slidesharecdn.com/ss_thumbnails/crossplataformdevelopmentwithmonofonts-110819063524-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












































