Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SU
Uploaded by
Seiichi Uchida
PPTX, PDF
3,680 views
データサイエンス概論第一=3-3 回帰分析
九州大学大学院システム情報科学研究院「データサイエンス実践特別講座」が贈る,数理・情報系『でない』学生さんのための「データサイエンス講義
Data & Analytics
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 239 times
1
/ 38
2
/ 38
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PPTX
データサイエンス概論第一=3-2 主成分分析と因子分析
by
Seiichi Uchida
PPTX
データサイエンス概論第一=1-1 データとは
by
Seiichi Uchida
PPTX
データサイエンス概論第一=2-2 クラスタリング
by
Seiichi Uchida
PPTX
データサイエンス概論第一=4-1 相関・頻度・ヒストグラム
by
Seiichi Uchida
PPTX
データサイエンス概論第一=1-2 データのベクトル表現と集合
by
Seiichi Uchida
PPTX
データサイエンス概論第一=3-1 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
PPTX
データサイエンス概論第一=1-3 平均と分散
by
Seiichi Uchida
PPTX
統計分析
by
大貴 末廣
データサイエンス概論第一=3-2 主成分分析と因子分析
by
Seiichi Uchida
データサイエンス概論第一=1-1 データとは
by
Seiichi Uchida
データサイエンス概論第一=2-2 クラスタリング
by
Seiichi Uchida
データサイエンス概論第一=4-1 相関・頻度・ヒストグラム
by
Seiichi Uchida
データサイエンス概論第一=1-2 データのベクトル表現と集合
by
Seiichi Uchida
データサイエンス概論第一=3-1 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
データサイエンス概論第一=1-3 平均と分散
by
Seiichi Uchida
統計分析
by
大貴 末廣
What's hot
PPTX
データサイエンス概論第一 6 異常検出
by
Seiichi Uchida
PDF
12 非構造化データ解析
by
Seiichi Uchida
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
PDF
13 分類とパターン認識
by
Seiichi Uchida
PDF
9 可視化
by
Seiichi Uchida
PPTX
主成分分析
by
大貴 末廣
PPTX
データサイエンス概論第一=4-2 確率と確率分布
by
Seiichi Uchida
PDF
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
PDF
2 データのベクトル表現と集合
by
Seiichi Uchida
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
PDF
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
PDF
20150414seminar
by
nlab_utokyo
PPTX
画像処理応用
by
大貴 末廣
PDF
もしその単語がなかったら
by
Hiroshi Nakagawa
PPTX
深層学習の非常に簡単な説明
by
Seiichi Uchida
PDF
傾向スコア:その概念とRによる実装
by
takehikoihayashi
PDF
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
質的変数の相関・因子分析
by
Mitsuo Shimohata
データサイエンス概論第一 6 異常検出
by
Seiichi Uchida
12 非構造化データ解析
by
Seiichi Uchida
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
13 分類とパターン認識
by
Seiichi Uchida
9 可視化
by
Seiichi Uchida
主成分分析
by
大貴 末廣
データサイエンス概論第一=4-2 確率と確率分布
by
Seiichi Uchida
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
2 データのベクトル表現と集合
by
Seiichi Uchida
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
20150414seminar
by
nlab_utokyo
画像処理応用
by
大貴 末廣
もしその単語がなかったら
by
Hiroshi Nakagawa
深層学習の非常に簡単な説明
by
Seiichi Uchida
傾向スコア:その概念とRによる実装
by
takehikoihayashi
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
質的変数の相関・因子分析
by
Mitsuo Shimohata
Similar to データサイエンス概論第一=3-3 回帰分析
PPTX
相関分析と回帰分析
by
大貴 末廣
PDF
データ解析6 重回帰分析
by
Hirotaka Hachiya
PPTX
データサイエンス概論第一=0 まえがき
by
Seiichi Uchida
PDF
九大_DS実践_相関分析と回帰分析
by
RyomaBise1
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
Introduction to statistics
by
Kohta Ishikawa
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PDF
カステラ本勉強会 第三回
by
ke beck
PDF
Stat r 9_principal
by
fusion2011
PDF
第5回スキル養成講座 講義スライド
by
keiodig
PDF
第6回スキル養成講座 講義スライド
by
keiodig
PDF
第4回スキル養成講座 講義スライド
by
keiodig
PDF
PRML セミナー
by
sakaguchi050403
PPTX
第7回 KAIM 金沢人工知能勉強会 回帰分析と使う上での注意事項
by
tomitomi3 tomitomi3
PPT
ma92007id395
by
matsushimalab
PDF
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
PDF
DS Exercise Course 6
by
大貴 末廣
PPTX
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
PDF
回帰
by
Shin Asakawa
PDF
C05
by
anonymousouj
相関分析と回帰分析
by
大貴 末廣
データ解析6 重回帰分析
by
Hirotaka Hachiya
データサイエンス概論第一=0 まえがき
by
Seiichi Uchida
九大_DS実践_相関分析と回帰分析
by
RyomaBise1
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
Introduction to statistics
by
Kohta Ishikawa
パターン認識02 k平均法ver2.0
by
sleipnir002
カステラ本勉強会 第三回
by
ke beck
Stat r 9_principal
by
fusion2011
第5回スキル養成講座 講義スライド
by
keiodig
第6回スキル養成講座 講義スライド
by
keiodig
第4回スキル養成講座 講義スライド
by
keiodig
PRML セミナー
by
sakaguchi050403
第7回 KAIM 金沢人工知能勉強会 回帰分析と使う上での注意事項
by
tomitomi3 tomitomi3
ma92007id395
by
matsushimalab
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
DS Exercise Course 6
by
大貴 末廣
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
回帰
by
Shin Asakawa
C05
by
anonymousouj
More from Seiichi Uchida
PDF
10 確率と確率分布
by
Seiichi Uchida
PDF
6 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
PPTX
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
PDF
15 人工知能入門
by
Seiichi Uchida
PDF
3 平均・分散・相関
by
Seiichi Uchida
PDF
8 予測と回帰分析
by
Seiichi Uchida
PDF
5 クラスタリングと異常検出
by
Seiichi Uchida
PDF
データサイエンス概論第一=7 画像処理
by
Seiichi Uchida
PDF
7 主成分分析
by
Seiichi Uchida
PDF
1 データとデータ分析
by
Seiichi Uchida
PDF
0 データサイエンス概論まえがき
by
Seiichi Uchida
PDF
4 データ間の距離と類似度
by
Seiichi Uchida
PDF
14 データ収集とバイアス
by
Seiichi Uchida
PDF
「あなたがいま読んでいるものは文字です」~画像情報学から見た文字研究のこれから
by
Seiichi Uchida
PDF
Machine learning for document analysis and understanding
by
Seiichi Uchida
PPTX
An opening talk at ICDAR2017 Future Workshop - Beyond 100%
by
Seiichi Uchida
10 確率と確率分布
by
Seiichi Uchida
6 線形代数に基づくデータ解析の基礎
by
Seiichi Uchida
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
15 人工知能入門
by
Seiichi Uchida
3 平均・分散・相関
by
Seiichi Uchida
8 予測と回帰分析
by
Seiichi Uchida
5 クラスタリングと異常検出
by
Seiichi Uchida
データサイエンス概論第一=7 画像処理
by
Seiichi Uchida
7 主成分分析
by
Seiichi Uchida
1 データとデータ分析
by
Seiichi Uchida
0 データサイエンス概論まえがき
by
Seiichi Uchida
4 データ間の距離と類似度
by
Seiichi Uchida
14 データ収集とバイアス
by
Seiichi Uchida
「あなたがいま読んでいるものは文字です」~画像情報学から見た文字研究のこれから
by
Seiichi Uchida
Machine learning for document analysis and understanding
by
Seiichi Uchida
An opening talk at ICDAR2017 Future Workshop - Beyond 100%
by
Seiichi Uchida
データサイエンス概論第一=3-3 回帰分析
1.
1 九州大学大学院システム情報科学研究院 データサイエンス実践特別講座 データサイエンス概論第一 第3回 主成分分析と回帰分析: 3-3 回帰分析 システム情報科学研究院情報知能工学部門 内田誠一
2.
2 データサイエンス概論第一の内容 データとは データのベクトル表現と集合
平均と分散 データ間の距離 データ間の類似度 データのクラスタリング (グルーピング) 線形代数に基づくデータ解析の基礎 主成分分析と因子分析 回帰分析 相関・頻度・ヒストグラム 確率と確率分布 信頼区間と統計的検定 時系列データの解析 異常検出
3.
3 データ集合に関する回帰 主成分分析とちょっと似てますが,分布解析ではありません! 回帰とは,予測手法です.
4.
4 データ集合に関する回帰① 「回帰による予測」の基本的考え方
5.
55 予測とは? 「入力に対する結果を推定する」手法 例 予測器 入力 (原因) 結果 入力(原因) 結果 勉強時間 試験の点数 食事量
糖尿病になる確率 (身長,体重) バスケットボールの得点 画像 その画像がリンゴの写真である確率
6.
6 回帰による予測(ステップ1/3): データ収集 結果 入力
7.
7 回帰による予測(ステップ1/3): データ収集の例 試験の点数 勉強時間 A君の データ B君の データ E君 C君 D君
8.
8 回帰による予測(ステップ2/3): モデルあてはめ 結果 入力 モデル=「条件 or 入力」と「結果」間に成り立つと予想される関係. 上記は「線形モデル」 これ大事
9.
9 回帰による予測(ステップ3/3): 予測 結果 入力 この入力に対する予測値がほしい (ex. 勉強3時間だと何点取れそう?)
10.
10 回帰による予測(ステップ3/3): 予測 結果 入力 この入力に対する予測値がほしい (ex. 勉強3時間だと何点取れそう?) 予測値 (65点)
11.
1111 回帰分析とは いくつかの(入力,結果 )の事例に基づいて, それらの関係をモデル化することで, 新たな入力に対して,その結果を予測する方法. 専門的な用語としては 入力→説明変数 結果→外的変数 とか言ったりしますが,まぁ,気にしない...
12.
12 データ集合に関する回帰② 「モデルあてはめ」の方法 最小二乗法で解く!
13.
13 どういう「あてはめ結果」が望ましい?(1/3) 13 結果 入力
14.
14 どういう「あてはめ結果」が望ましい?(2/3) 14 結果 入力 あてはめ誤差 これが小さいほうがよい 𝑖 第𝑖データのあてはめ誤差 →最小化
15.
15 どういう「あてはめ結果」が望ましい?(3/3) 15 結果 𝑦 入力 𝑥 𝑎と𝑏をいじって 𝑖 𝑦𝑖
− 𝑎𝑥𝑖 + 𝑏 2 を最小化 𝑦 = 𝑎𝑥 + 𝑏 𝑥𝑖, 𝑦𝑖𝑦𝑖 − 𝑎𝑥𝑖 + 𝑏 2 二乗誤差で「あてはめ誤差」を定義
16.
16 これを「最小二乗法」と呼ぶ 16 𝑎と𝑏をいじって 𝑖 𝑦𝑖 − 𝑎𝑥𝑖
+ 𝑏 2 を最小化 二乗誤差を最小にしたいから 最小二乗法 どうやって??
17.
17 参考:最小二乗法,どう解く? まず問題をよく見る(1/2) 17 𝑖 𝑦𝑖 − 𝑎𝑥𝑖
+ 𝑏 2 = 𝑖 𝑦𝑖 − 𝑎𝑥𝑖 + 𝑏 𝑦𝑖 − 𝑎𝑥𝑖 + 𝑏 = 𝑖 𝑥𝑖 2 𝑎2 − 𝑦𝑖 − 𝑏 2𝑎 + 𝑦𝑖 − 𝑏 2 = 𝑖 𝑥𝑖 2 𝑎2 − 2 𝑖 𝑦𝑖 − 𝑏 𝑎 + 𝑖 𝑦𝑖 − 𝑏 2 落ち着いて考えれば 𝑎に関する2次関数 最小化したいもの
18.
18 参考:最小二乗法,どう解く? まず問題をよく見る(2/2) 18 𝑖 𝑦𝑖 − 𝑎𝑥𝑖
+ 𝑏 2 = 𝑖 𝑦𝑖 − 𝑎𝑥𝑖 − 𝑏 𝑦𝑖 − 𝑎𝑥𝑖 − 𝑏 = 𝑖 𝑏2 − 𝑦𝑖 − 𝑎𝑥𝑖 2𝑏 + 𝑦𝑖 − 𝑎𝑥𝑖 2 = 𝑖 1 𝑏2 − 2 𝑖 𝑦𝑖 − 𝑎𝑥𝑖 𝑏 + 𝑖 𝑦𝑖 − 𝑎𝑥𝑖 2 落ち着いて考えれば 𝑏に関しても2次関数 最小化したいもの
19.
19 ここはイマイチ ここがベスト 参考:最小二乗法,どう解く? 要するにこんな形になっています 19 𝑏 𝑎 𝑖 𝑦𝑖 − 𝑎𝑥𝑖
+ 𝑏 2 ベストは1か所→ベストな「モデルあてはめ」は一つ! (by 一か所だけ出っ張った二次関数の美しい特性) 誤差大 誤差最小 誤差
20.
20 参考:最小二乗法,どう解く? 解き方の細かいところ 20 𝜕 𝑖 𝑦𝑖
− 𝑎𝑥𝑖 + 𝑏 2 𝜕𝑎 = 0 𝜕 𝑖 𝑦𝑖 − 𝑎𝑥𝑖 + 𝑏 2 𝜕𝑏 = 0 解き方(要は「極値なら微分してゼロ」という条件) 高校時代 二次関数の 極値問題を 解かされたな... 𝑎と𝑏をいじって 𝑖 𝑦𝑖 − 𝑎𝑥𝑖 + 𝑏 2 を最小化
21.
21 主成分分析と回帰分析の違い: どちらがいい・悪いというものではなく,目的からして全く違う 21 要素 𝑥2 要素 𝑥1 第1主成分= 分布の近似方向 主成分分析 結果
𝑦 入力(原因)𝑥 回帰直線= 入力と結果の関係 (線形)回帰分析 要素 𝑥1, 𝑥2を交換しても同じ 入力 𝑥と結果𝑦を交換すると違う直線
22.
22 データ集合に関する回帰③ 重回帰分析 入力=複数の変数 結果=単一の値
23.
23 重回帰による予測(ステップ1/3): データ収集 バスケット ボールの得点 身長𝑥1 A君の データ B君の データ E君 体重𝑥2 入力が 二次元に
24.
24 重回帰による予測(ステップ2/3): モデルあてはめ バスケット ボールの得点 A君の データ B君の データ E君 → やはり最小二乗法になります 身長𝑥1 体重𝑥2
25.
25 重回帰による予測(ステップ3/3): 予測 バスケット ボールの得点 12点 身長𝑥1 体重𝑥2
26.
2626 余談:なんで「重」回帰? 何か重たいのか? 英語では Multiple
regression analysis このmultipleを「重」と訳した Regression analysis = 回帰分析 Multiple=「複数のものを(同時に)」という意味合いか というわけで「何かが重たい」わけではない
27.
27 データ集合に関する回帰④ より複雑なモデルの利用 多項式モデル
28.
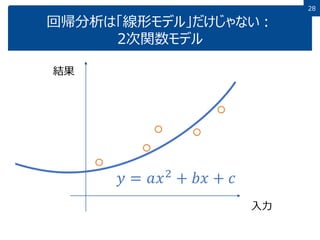
28 回帰分析は「線形モデル」だけじゃない: 2次関数モデル 結果 入力 𝑦 = 𝑎𝑥2 +
𝑏𝑥 + 𝑐
29.
29 回帰分析は「線形モデル」だけじゃない: 𝑁次多項式モデル 結果 入力 𝑦 = 𝑎
𝑛 𝑥 𝑛 + 𝑎 𝑛−1 𝑥 𝑛−1 + ⋯ + 𝑎1 𝑥 + 𝑎0 全データを通過 →誤差ゼロ でも...これOK? (この点,後述)
30.
30 データ集合に関する回帰⑤ 回帰分析で注意したい点 アウトライヤとオーバーフィット
31.
31 アウトライヤ(はずれ値)の悪影響(1/4) 31 結果 𝑦 入力 𝑥 アウトライヤ •
センサの異常 • 測定ミス • イイカゲンな返答
32.
32 アウトライヤ(はずれ値)の悪影響(2/4) 32 結果 𝑦 入力 𝑥 こちらのほうが よさそうだが... アウトライヤも 等しく扱うために こうなる アウトライヤ
33.
3333 アウトライヤ(はずれ値)の悪影響(3/4) 対策:「ロバスト最小二乗法」 結果 𝑦 入力 𝑥 第一回目の あてはめ結果 依然として 誤差大
34.
3434 アウトライヤ(はずれ値)の悪影響(4/4) 対策:「ロバスト最小二乗法」 結果 𝑦 入力 𝑥 第2回目の あてはめ結果 このデータに ついては 誤差があっても 小さめに評価
35.
35 オーバーフィッテイングと汎化能力(1/3) 結果 入力 予測値 (いいの?) 事前に与えられたデータにとってはハッピーだが 未知データにとっては使い物にならない(オーバーフィット)
36.
3636 オーバーフィッテイングと汎化能力(2/3) 汎化能力(generalization)とは? 回帰曲線を求めるときには使わなかったデータについても, ちゃんと妥当な予測結果が得られるか? だから下の例は「汎化能力」がない例
37.
37 オーバーフィッティングと汎化能力(3/3) 37 (良)事前に与えられたデータに 対する誤差小さい (悪)大量に事前データがないと 回帰結果に汎化能力がない恐れ (悪)事前に与えられたデータに 対する誤差大 (良) 事前データ数が少なくても ひどいオーバーフィッティングは少ない 高次多項式モデル 線形モデル
38.
3838 オーバーフィッティングやアウトライヤの影響を 見つける方法:バリデーション(validation) 事前に収集されたデータ集合をランダムにA, Bに分ける 集合Aの中のデータを使って,モデルフィッティングを行う 求まったモデルを使い,集合Bのデータがどれぐらいきちんと 予測できるかを評価する ※集合Bのデータも正解値はわかっている
Download