3.1 スーパスカラーの概念
• CPUコア内部にパイプラ
インを複数用意
•命令を同時実行するこ
とで高速化
• ソフトウェアからは並
列実行数不明
IF RF EX ME WR
パイプライン1段
パイプライン2段
IF RF EX ME WR
IF RF EX ME WR
RAM(Cache)
Register
RAM(Cache)
Register
47.
3.2 スーパースカラーの実際1
Inst Decoder
RFEX ME WR
Inst
Cache Inst Decoder
Inst Queue
Inst Inst Inst Inst
RF EX ME WR
Data
CacheRegister
Register
• スーパスカラーの実際のパイプライン
• 複数命令を同時に読み出してデコード
• 複数命令をキューに入れる
• 依存性が無い命令を同時実行
全部が複数あるわけではない
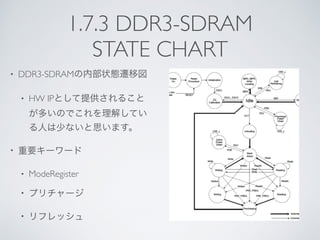
7.4 PRODUCER CONSUMER
THREADINGMODEL
• Producer : データ生成
• Consumer : データ使用
• 例:
• P : ファイル読み出し
• C : 動画デコード
P C
P C
P C
P C
P P
C C
P P
C C
Model 1
Model 2
time
Thread 1
Thread 2
Thread 1
Thread 2


















![1.8.1 CPUの待ち時間
• 今までのワーストケースで1wordを読み出す時間を計算
• tL1 = 1 Clock
• tL2 = 16 Clock (8 × 2CPUの半分のクロックで動作と過程)
• tDDR3 = 28 Clock (7 × 4 CPUバスの半分のクロックで動作と過程)
• tAllMiss = tL1 + tL2 + tDDR3 = 45 [Clock]
• CPUやシステムによって上記の値は全然違います。
• 実際の値を適用すると、もっとすごいことになります。
• http://www.7-cpu.com/cpu/Cortex-A9.html](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-20-320.jpg)
![1.8.2 キャッシュヒット率を
考慮
• キャッシュヒット率(仮定)
• L1、L2ともにhit率 = 90.0%と仮定。
• Avarage AccessTime = tL1×0.9 + tL2 × (1 - 0.9) + tDDR3 × (1 - 0.9) × 0.9
= 4.22[clock]
• バスクロックが遅いと?
• 同一クロックであっても外部バス速度が遅いCPUがあります。
• 例:Core2Duo 667MHz、Celeron 533MHz
• Avarage AccessTime = tL1×0.9 + (tL2 × (1 - 0.9) + tDDR3 × (1 - 0.9) ×
0.9) × 667/533 = 5.05[clock]
• ざっくり計算です。](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-21-320.jpg)



![1.9.1 通常のループ
• src[row] += dst[row][col]
• dstのサイズ>>キャッシュ
• キャッシュ1ラインの
ワード数ごとにキャッシュ
ミスヒット。
0
1
dst
9
row
0 0
1
src
65535
1 0
9 65534
9 65535
row col
キャッシュ
サイズ
for (unsigned long row = 0; row < ROW_SIZE; row++) {
for (unsigned long col = 0; col < COL_SIZE; col++) {
*(dst + row) += *(src + row * COL_SIZE + col);
}
}](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-25-320.jpg)



![1.9.5 行列計算
• 普通にアルゴリズムを書くと、先ほどの「普通のルー
プ」と「残念なループ」の組み合わせになる。
• 片方をわざと行列を入れ替えて定義する
int A[row][col];
int B[col]row];
int A[row][col];
int B[row][col];](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-29-320.jpg)

![1.9.7 フォールスシェアリング
解決策
• 複数のスレッドで共有する必要の無いデータはアドレス
が64バイト以上離れるようにする。
Core1 Core2
Cache Line Cache Line
DRAM
void worker_thread1(void) {
for (int i = 0; i < MAX; i++)
dstArea[0] += srcArea[i];
}
void worker_thread2(void) {
for (int i = 0; i < MAX; i++)
dstArea[1] += srcArea[i];
}
void worker_thread3(void) {
for (int i = 0; i < MAX; i++)
dstArea[64] += srcArea[i];
}
thread1と2はフォールスシェアリング
thread1と3は無し](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-31-320.jpg)
![1.9.8 実験結果:ループ
• 「残念なループ」はキャッシュヒッ
ト率が低く、DRAMアクセスが多
い。
• 「ブロッキング」はDRAMアクセス
が少ない。
• 簡単なプログラムのため差が出
にくかったかも。
• テストプログラム以外のプロセ
スのカウント値も含まれている
と思われます。
時間[S] L1 HIT
DRAM
READ
普通 1.68 99.82 5542MB
残念 14.09 89.54 41100MB
ブロッキ
ング
1.63 99.95 283MB
アンロー
リング
1.62 99.91 5460MB](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-32-320.jpg)
![1.9.9 実験結果:行列計算/シェ
アリング
• 行列を入れ替えるとキャッシュ
ヒット率が向上しDRAMアクセス
が減る。
• フォールスシェアリングを回避
することによりDRAMアクセスが
半分になっている。
• 「ループ」、「行列計算」、
「シェアリング」はそれぞれ
異なるテストプログラムを実
行しています。
時間[S] L1 HIT
DRAM
READ
通常 13.33 92.30 49.8GB
行列
入れ替
2.06 99.75 10.7GB
時間[S] L1 HIT
DRAM
READ
FALSE
SHARE
10.54 95.42 926MB
NONE
SHARED
4.62 98.77 421MB](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-33-320.jpg)


![2.2 処理時間
• 入力してから出力が得られる
までの時間を処理時間と定義
します。
• CPUの場合、メモリから命
令を読み出し、結果を書き
込むまでの時間をクロック
数で表現します。
• これをCPI(Clock Per
Instruction)と呼びます。
メモリ
CPU
t[clocks]](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-36-320.jpg)






![2.9 パイプラインの限界
• パイプラインとキャッシュにより、理論上は
最速で1クロックあたり1命令実行。=1.0[IPC]
• IPC = Instruction Per Clock
• どんなに工夫してもIPCは1.0の壁を超えるこ
とは不可能。](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-43-320.jpg)




















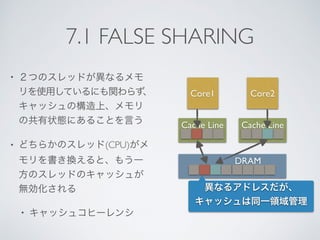

![7.3 FALSE SHARING実験
• 実験
• 2つのスレッドが異なるアドレスにデータを書き続ける
• 隣り合ったアドレス、64バイトずらしたアドレスへの書き込みの違い
• 異なる物理コア、同一物理コア内の異なる論理コア
アドレスオフセット/コア 同一物理コア 異なる物理コア
1バイト 2.5[s] 3.7[s]
64バイト 2.5[s] 1.6[s]](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-66-320.jpg)

![7.5 PRODUCER CONSUMER
実験
• Model1とModel2の比較
• Model1はキャッシュが同一
• Model2はキャッシュが異なるため、コヒーレンシ制御が多発
MODEL/コア 同一論理
同物理
異論理
異物理
MODEL1
3.6[s] 2.4[s] 1.9[s]
99.9[%] 99.9[%] 99.9[%]
MODEL2
3.3[s] 2.4[s] 2.1[s]
99.9[%] 99.9[%] 98.9[%]](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-68-320.jpg)
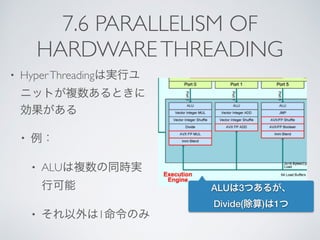
![7.7 HARDWARETHREADINGと
SUPERSCALER実験
• 実験1
• 加算だけを行うスレッドを2つ実行
• 実験2
• 除算だけを行うスレッドを2つ実行
スレッド/コア
同一
論理
同一物理
異論理
異物理
加算 3.4[s] 1.8[s] 1.9[s]
除算 4.2[s] 3.4[s] 2.2[s]](https://image.slidesharecdn.com/codejp2015cpu-150813144631-lva1-app6892/85/Code-jp2015-cpu-70-320.jpg)



































































