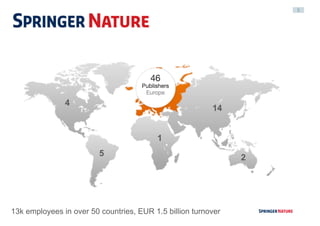
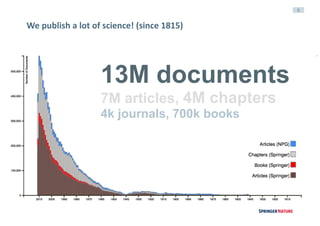
Downloaded 69 times





![6
[Pre-Merger] Springer Science + Business Media brands](https://image.slidesharecdn.com/leipzigv10-160914101421/85/Linked-Data-Experiences-at-Springer-Nature-6-320.jpg)
![7
[Pre-Merger] Macmillan Science & Education brands
Holtzbrinck
Publishing
Group](https://image.slidesharecdn.com/leipzigv10-160914101421/85/Linked-Data-Experiences-at-Springer-Nature-7-320.jpg)




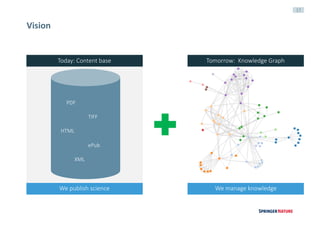




![30
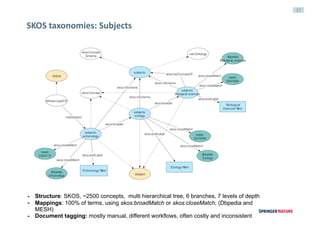
Scigraph Project (2016): main objectives
Data Integration
> Consolidation of existing LD efforts via a single domain mode
> Ingestion and normalisation of third party datasets
Discoverability
> Better end user applications [B2C]
> Metadata delivery & validation [B2B]
> Data publishing [B2developers]](https://image.slidesharecdn.com/leipzigv10-160914101421/85/Linked-Data-Experiences-at-Springer-Nature-30-320.jpg)



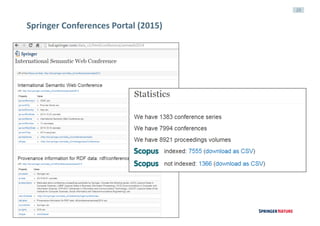
![42
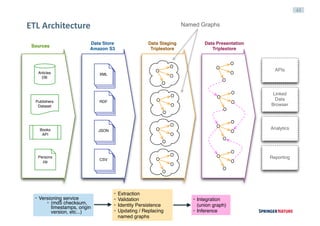
ETL Architecture: main features [in evolution]
Tech stack
> Airflow framework (Airbnb)
> Amazon S3 to make backups
> GraphDB triplestore (staging and presentation)
> Elastic search and APIs
Components & Principles
> Graph must be ‘ephemeral’
> Data sources versioning algorithm
> Identity Persistence service
> Validation via SHACL (TopBraid API)](https://image.slidesharecdn.com/leipzigv10-160914101421/85/Linked-Data-Experiences-at-Springer-Nature-42-320.jpg)
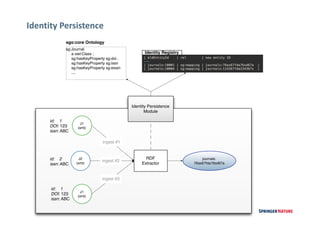




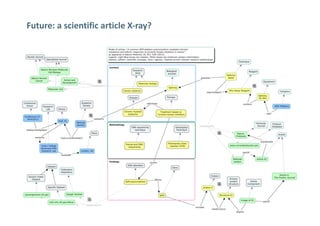



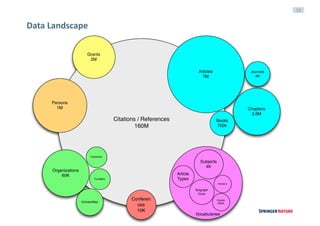
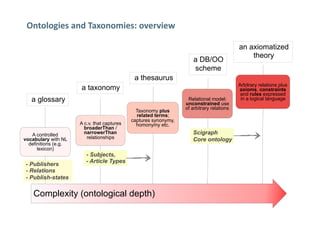
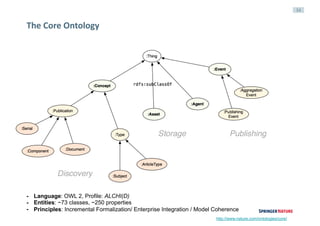
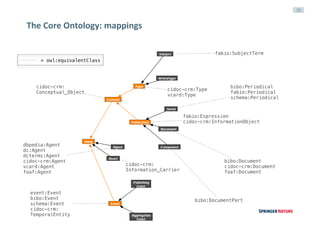
This document discusses linked data experiences at Springer Nature, focusing on their semantic technologies and the Scigraph project. It outlines the challenges of data fragmentation and the importance of a knowledge graph for better user experience in accessing scientific data. The presentation highlights their ongoing efforts in data integration, ontology development, and future collaborations in linked science data.
































































































