Downloaded 19 times












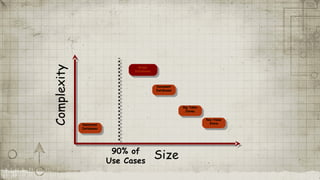






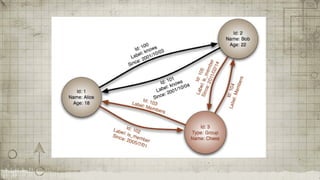






This document provides an overview of graph databases and Neo4j. It discusses how graph databases are better suited than relational databases for interconnected data and have simpler data models. Neo4j is highlighted as a graph database that uses nodes, edges and properties to represent data and uses the Cypher query language. It is fully ACID compliant, open source, and has a large active community.










































































