Downloaded 171 times







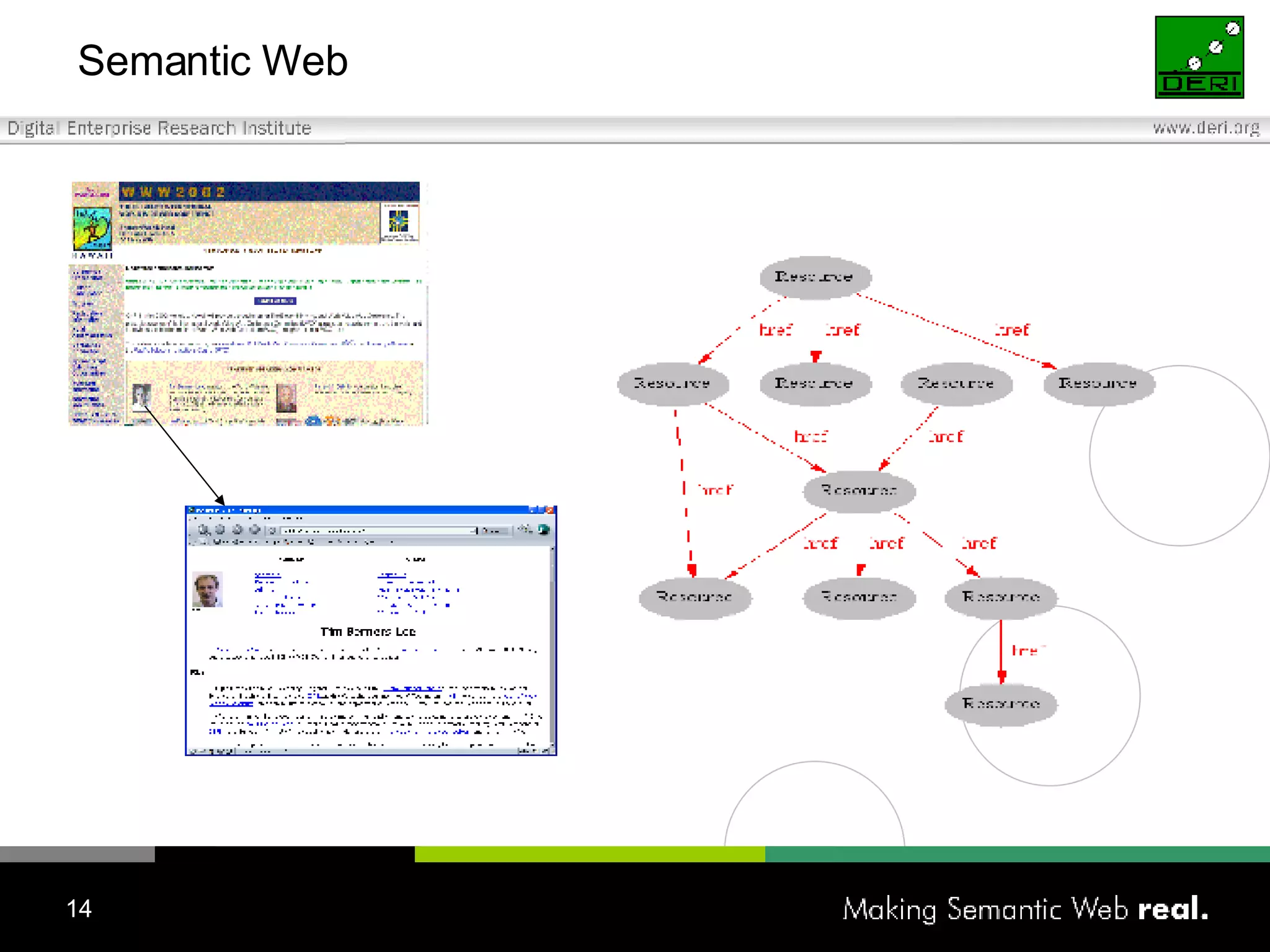
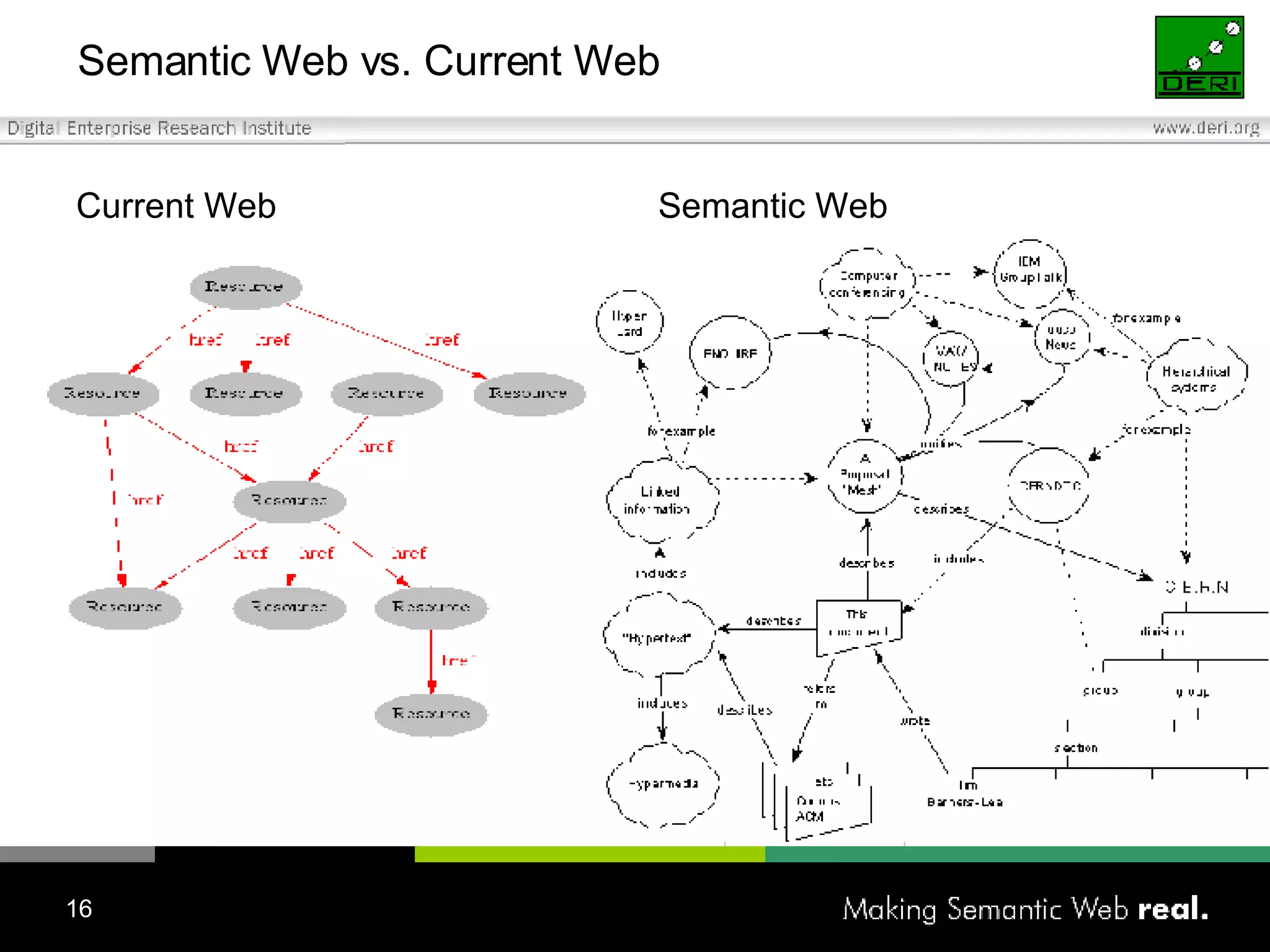
![The Semantic Web – A Brief Introduction Current Web vs. Semantic Web? An extension of the current Web in which information is given well-defined meaning, better enabling computers and people to work in cooperation. [Tim Berners-Lee] Current Web was designed for humans, and there is little information usable for machines Was the Web meant to be more? Objects with well defined attributes as opposed to untyped hyperlinks between Internet resources A network of relationships amongst named objects, yielding unified information management tasks What do you mean by “Semantic”? the semantics of something is the meaning of something Semantic Web is able to describe things in a way that computers can understand](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-15-2048.jpg)




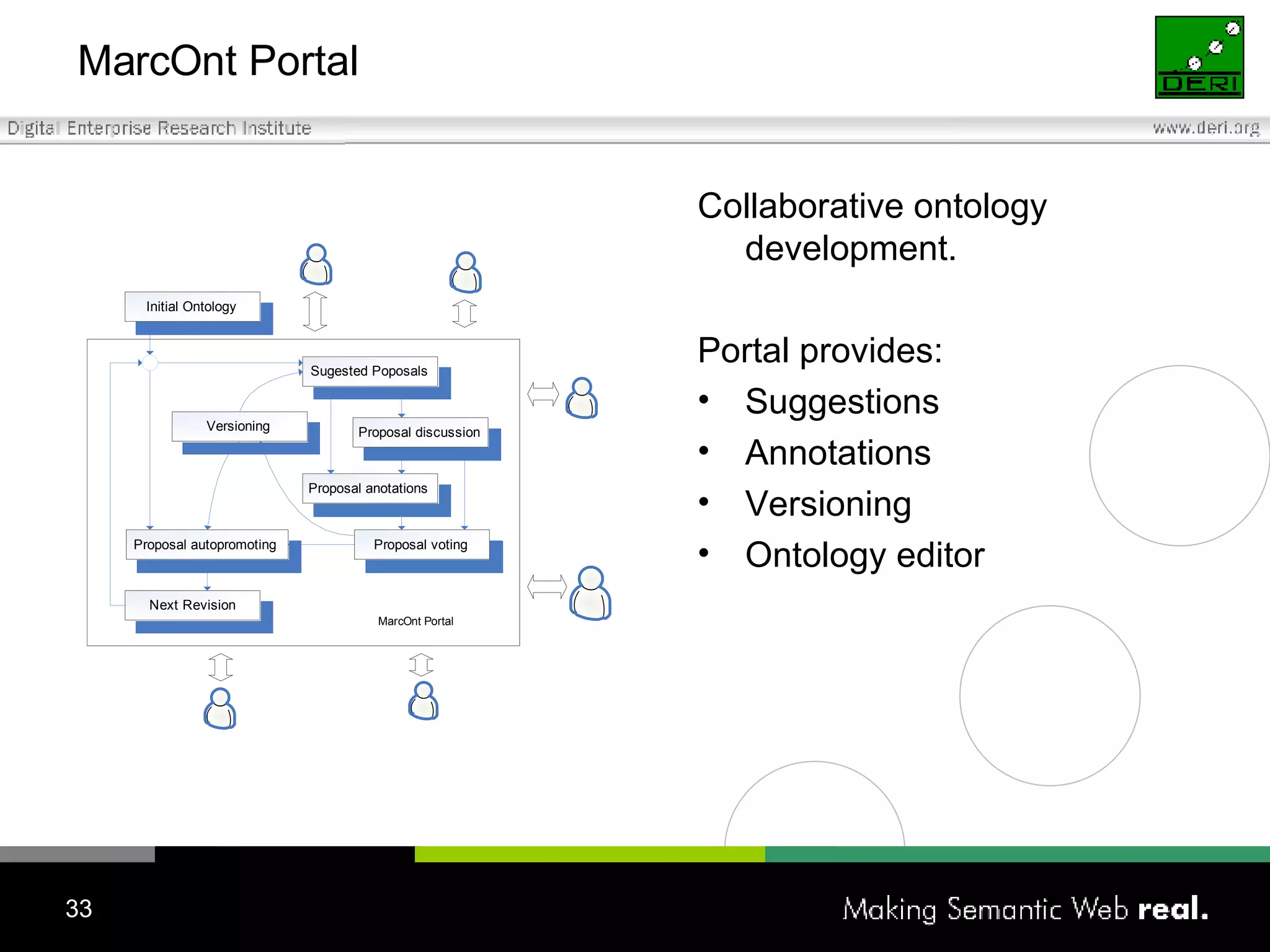
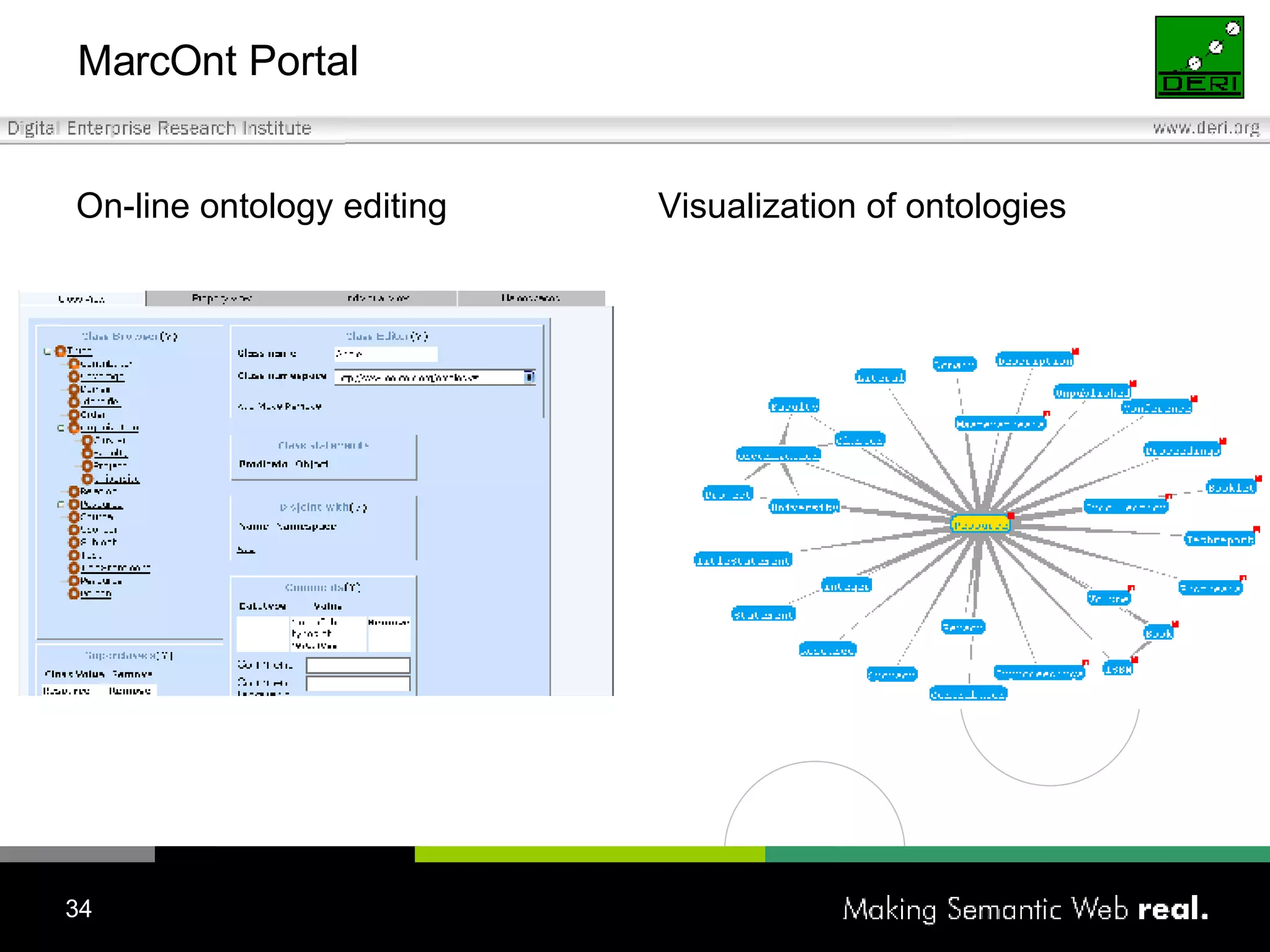

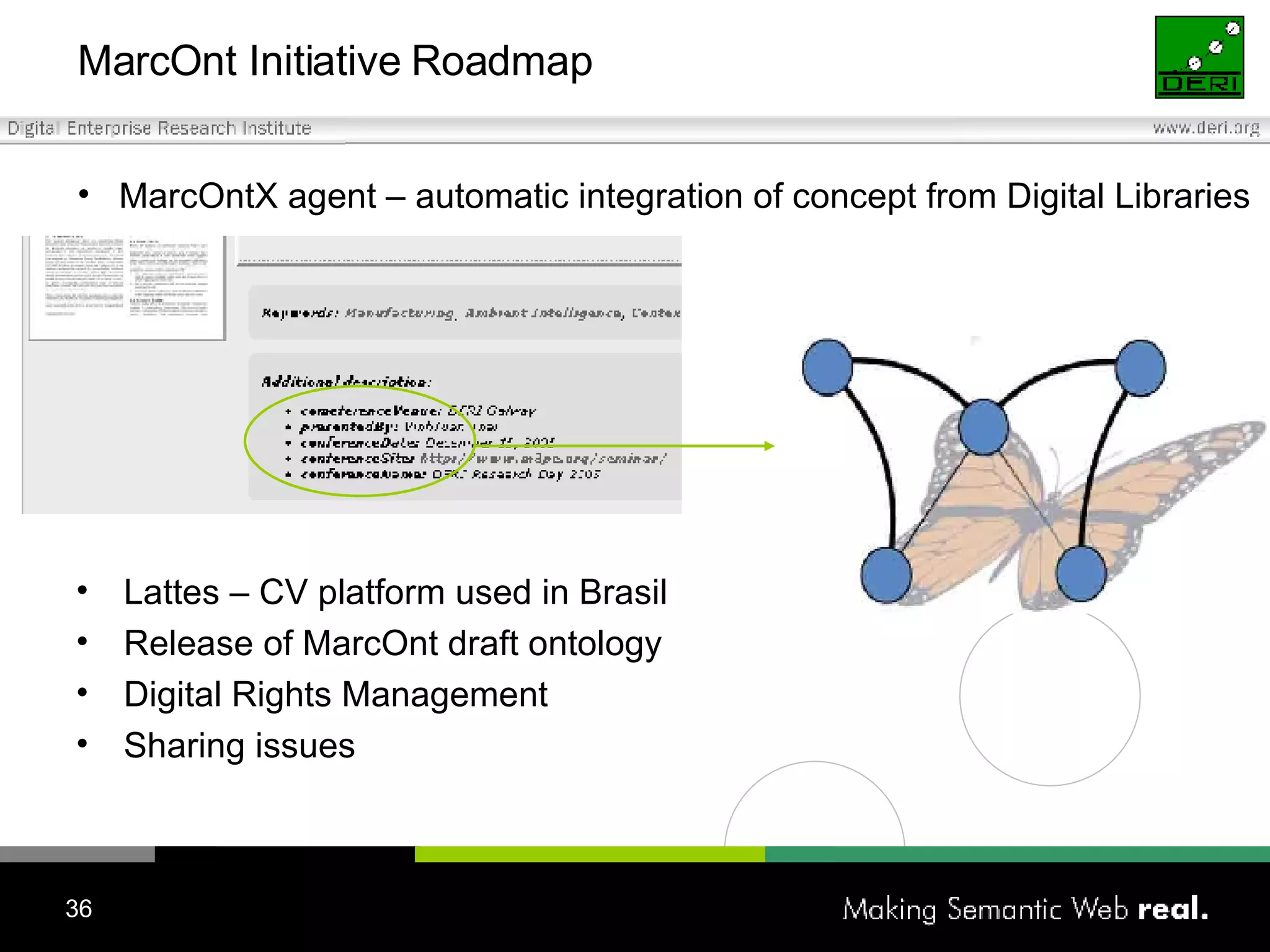

![Tomasz Woroniecki [email_address] JeromeDL Building a Semantic Digital Library](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-39-2048.jpg)






























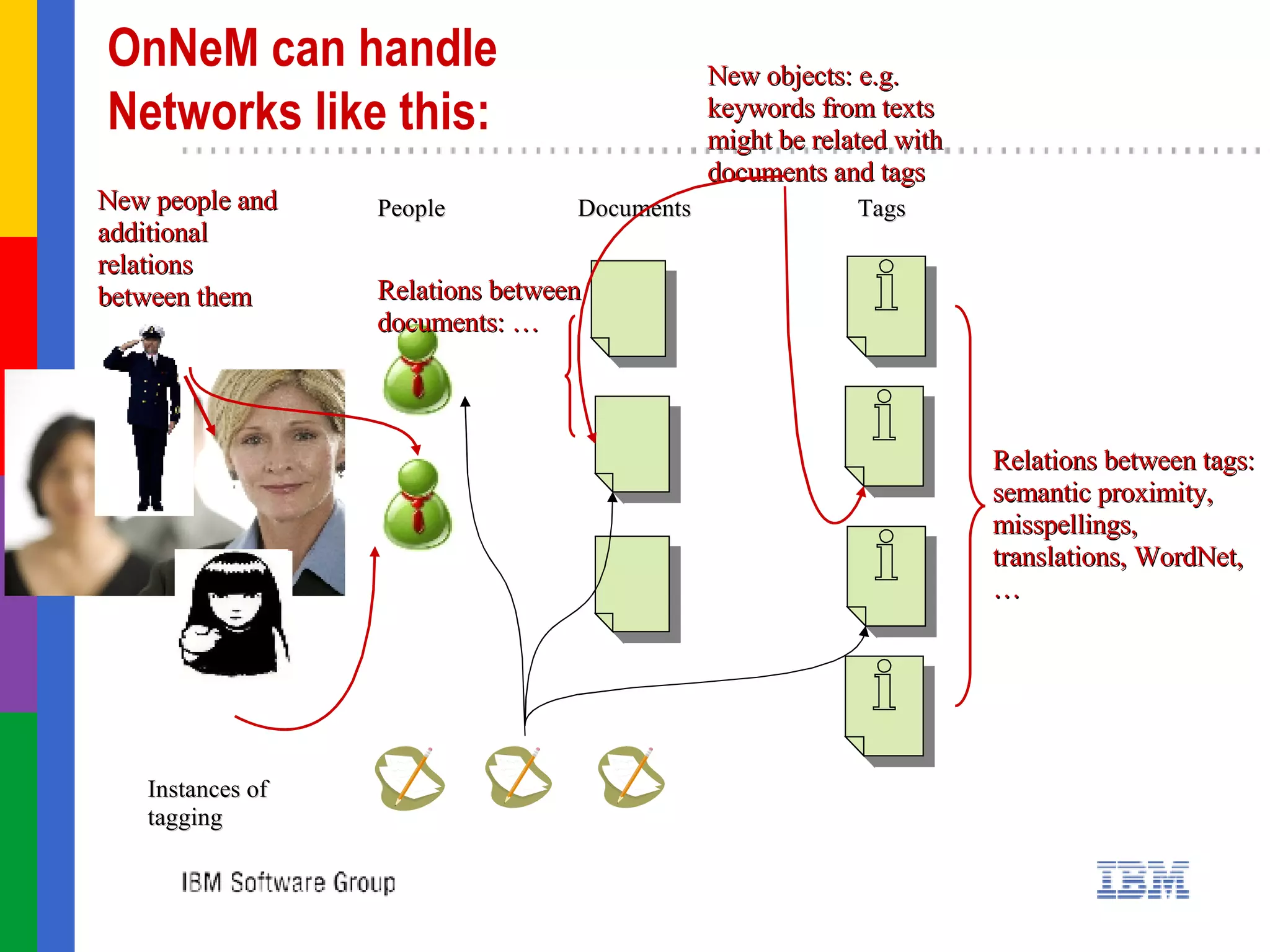




![Research collaborationation Create semantic social networks of your interest … in the format which can be used by Galaxy simple XML format Design scenario and work with us on tuning parameters of Galaxy for the tasks in your scenario … Contacts Alexander Troussov, CAS Chief Scientist, [email_address] Marie Wallace, LanguageWare manager, [email_address] Brian O’Donovan, CAS Program Director, [email_address] IBM CAS Dublin https://www.ibm.com/ibm/cas/sites/dublin/ LanguageWare http://www.ibm.com/software/globalization/topics/languageware/index.jsp NEPOMUK http://nepomuk.semanticdesktop.org/](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-83-2048.jpg)

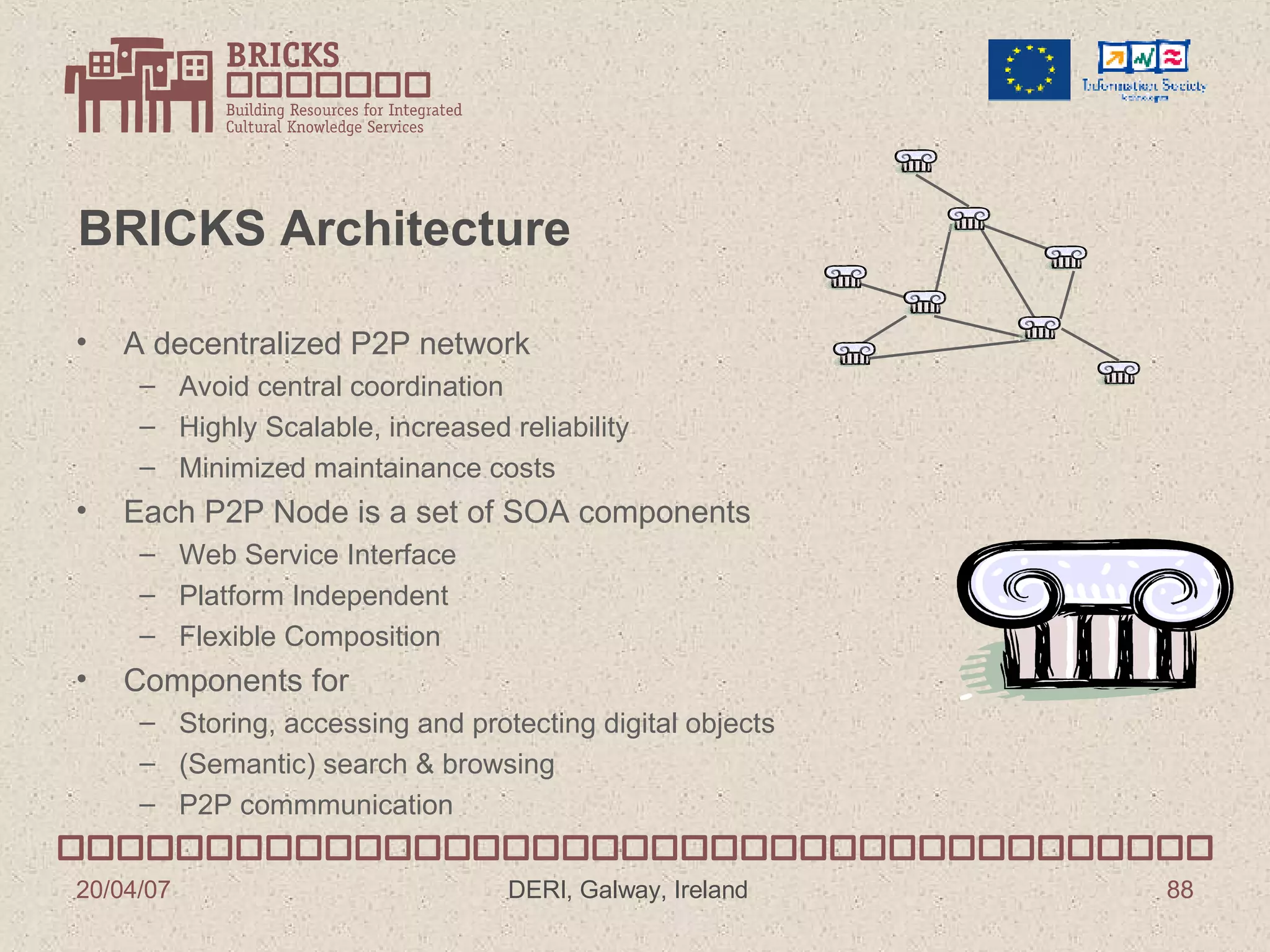
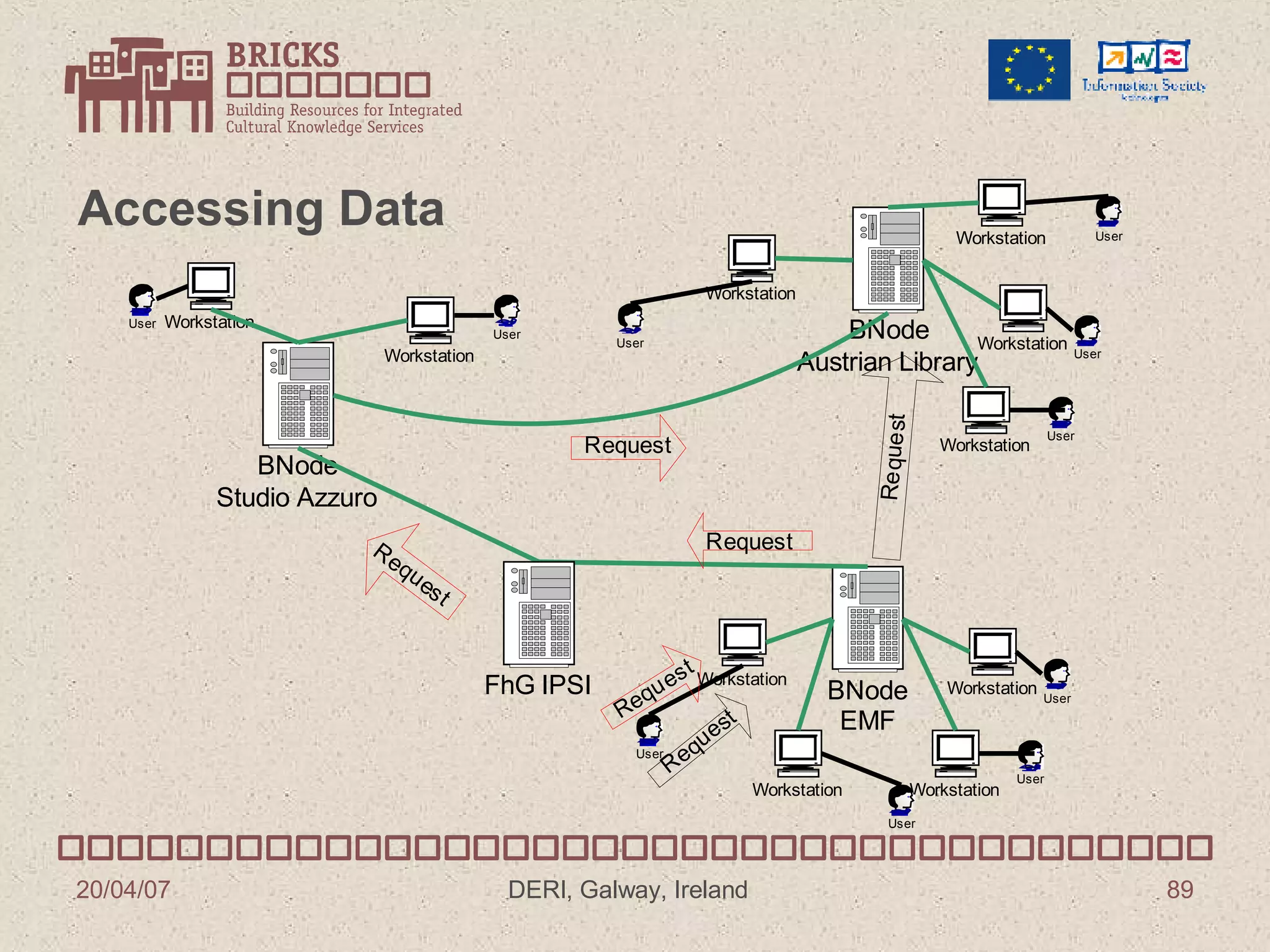
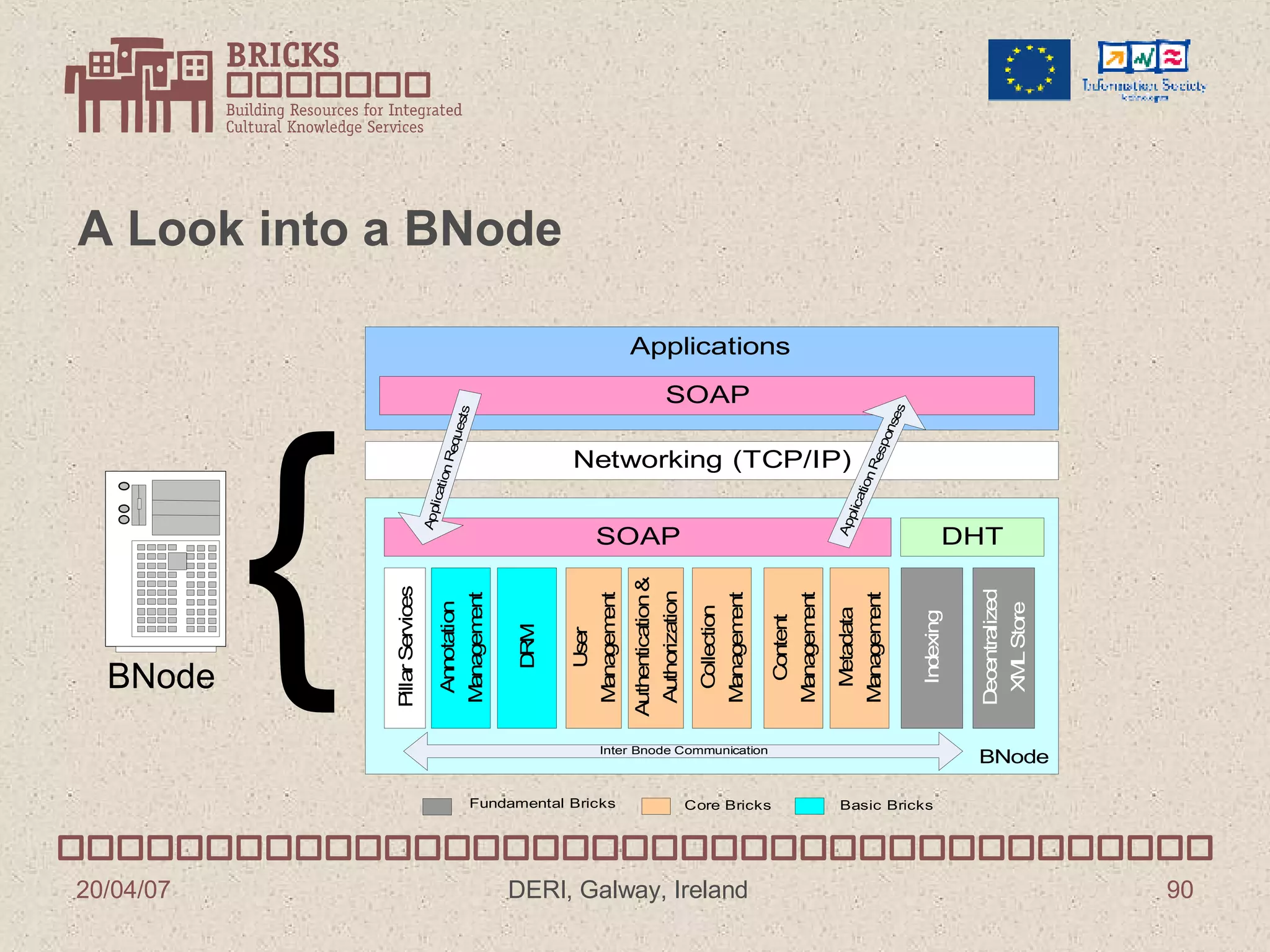
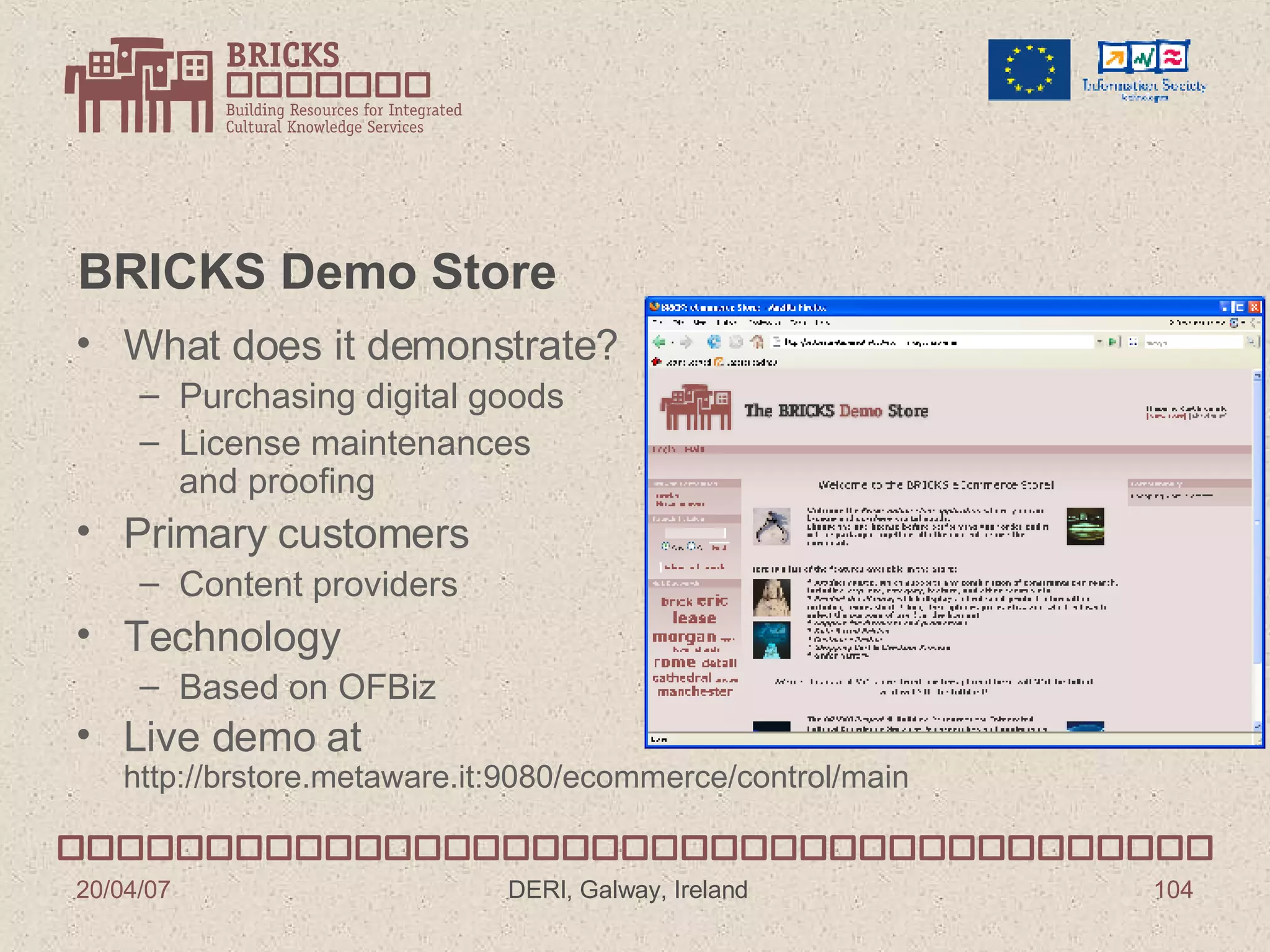
![BRICKS Project Predrag Knežević Fraunhofer IPSI Institute Darmstadt, Germany [email_address]](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-85-2048.jpg)



























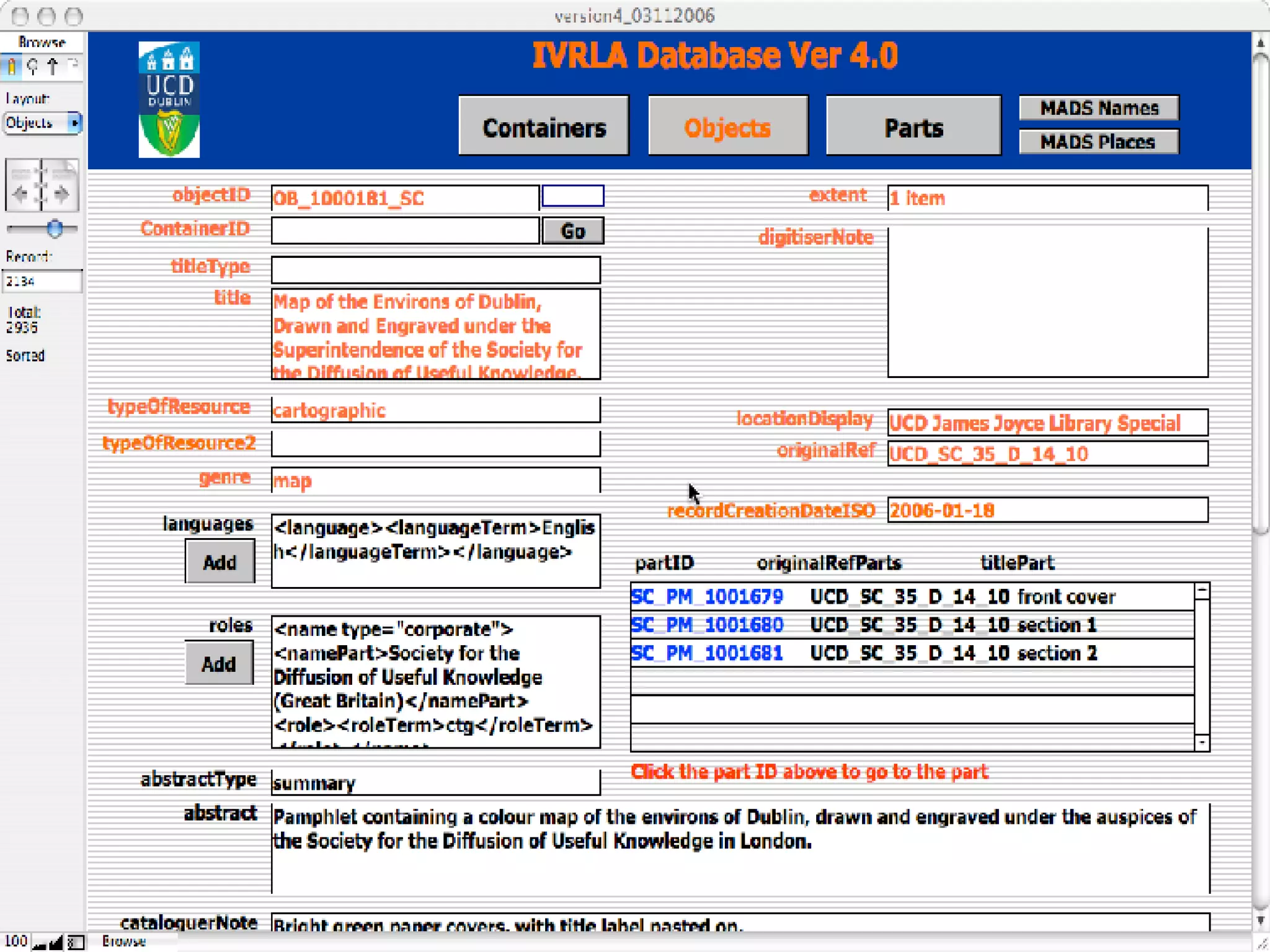
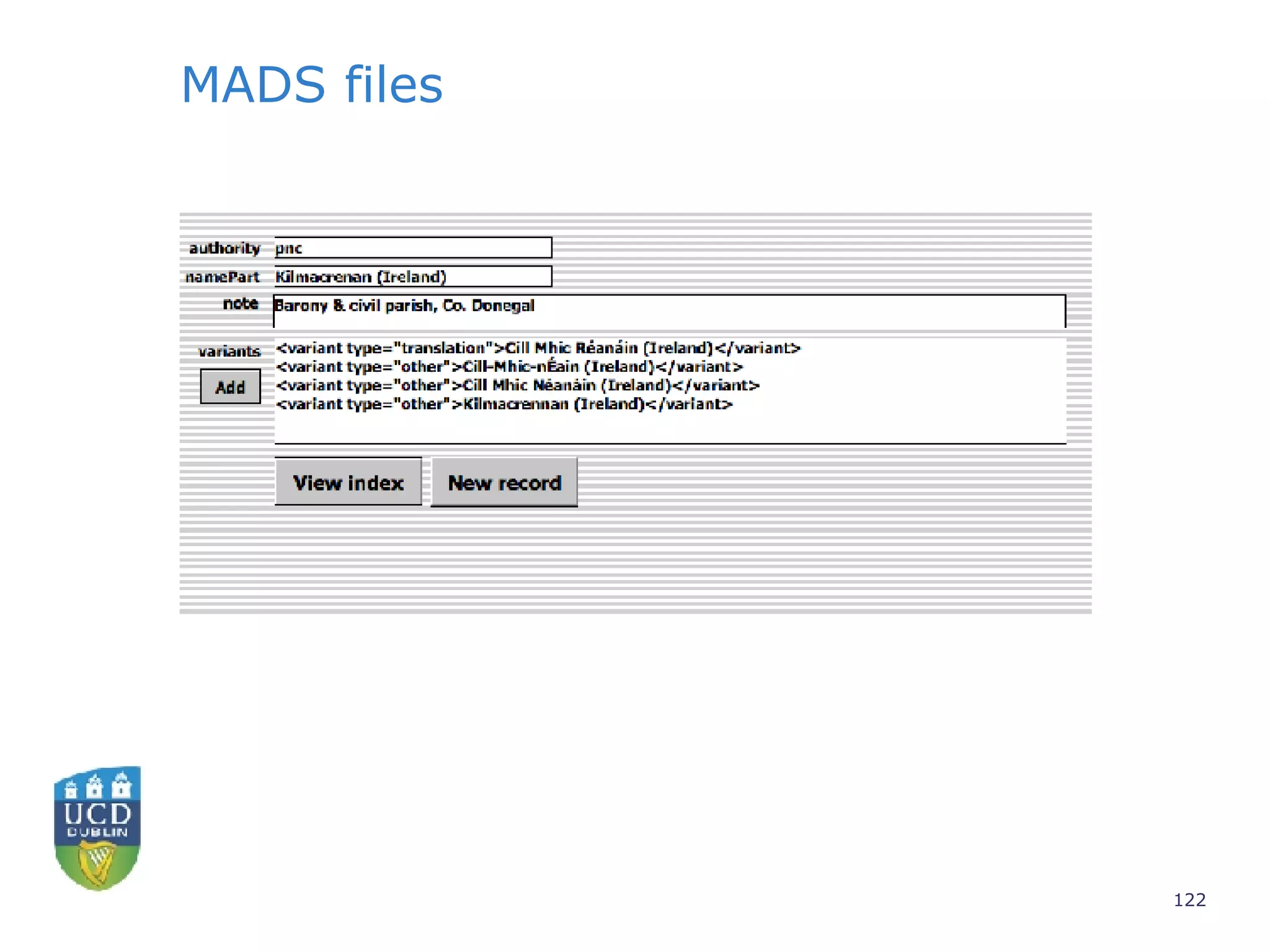





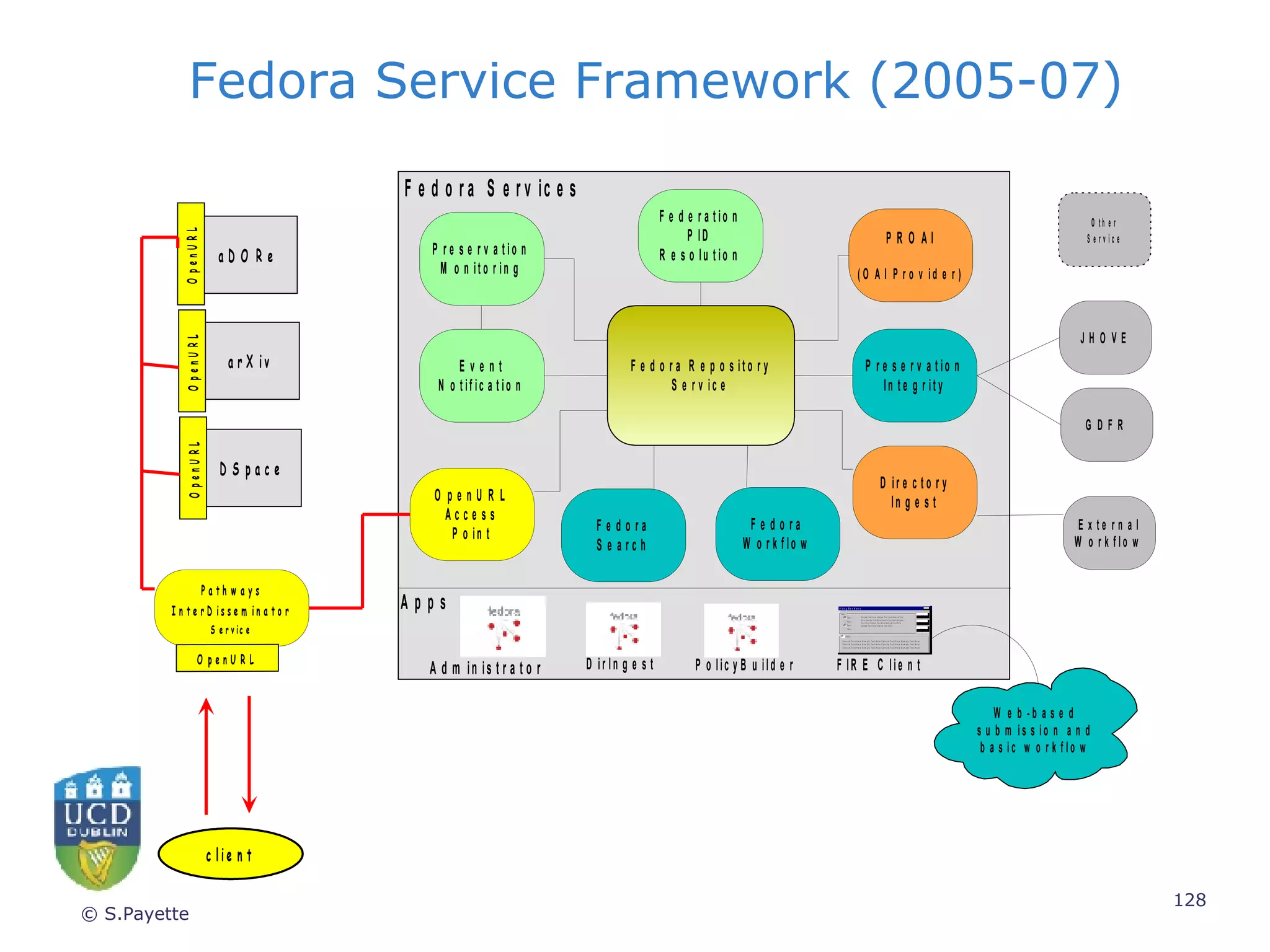








![Further Information www.ucd.ie/ivrla [email_address]](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-141-2048.jpg)



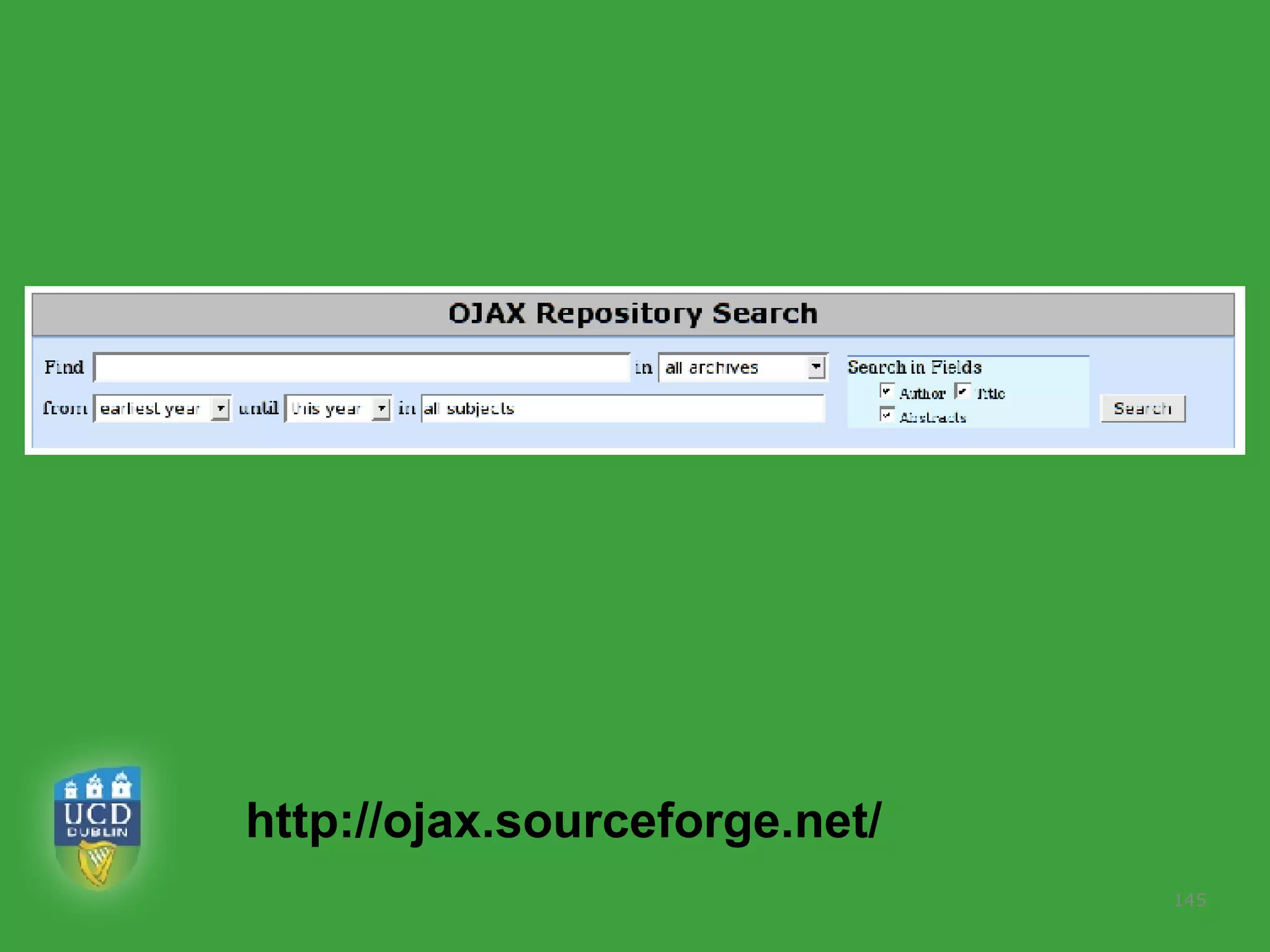
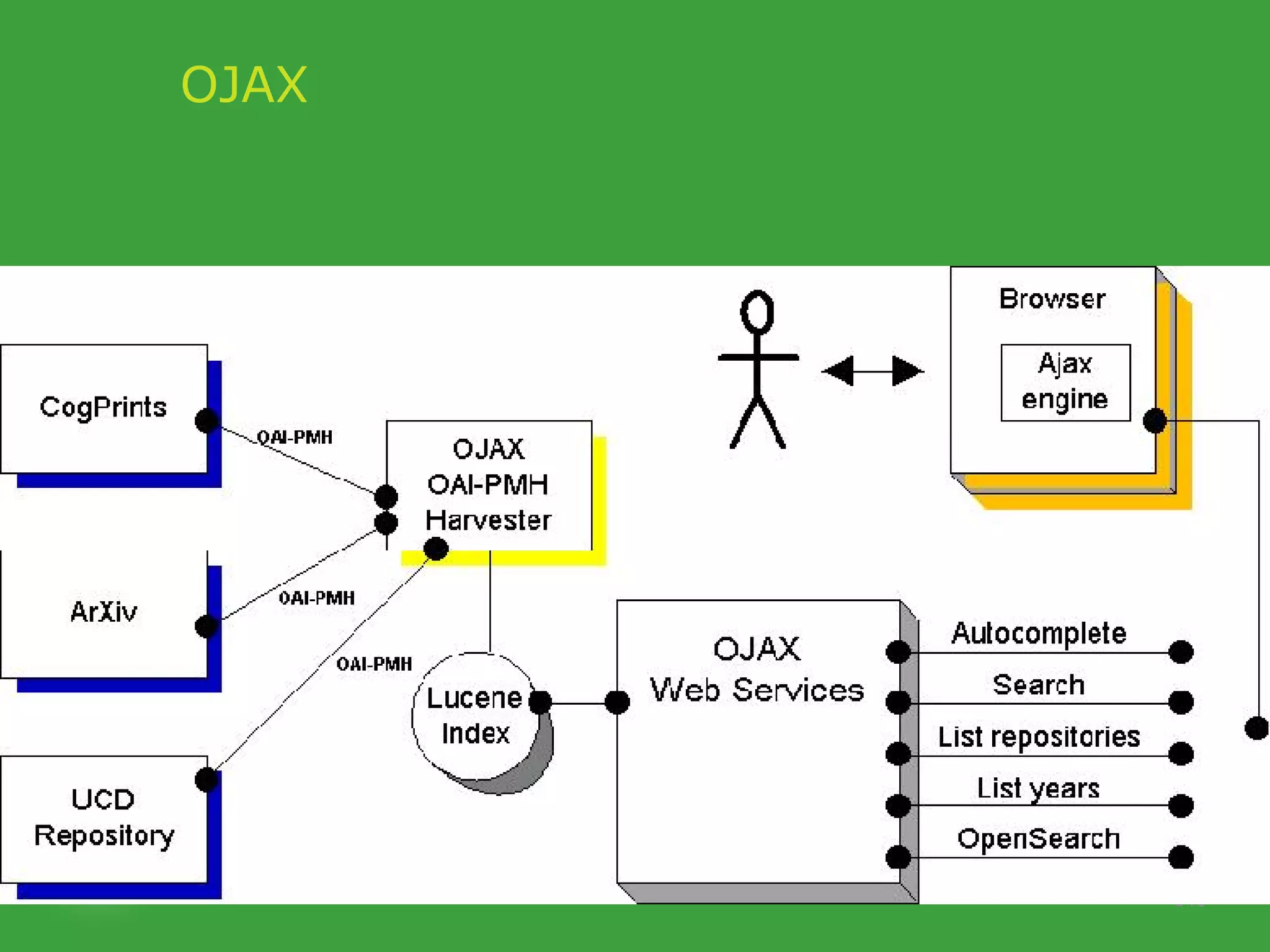

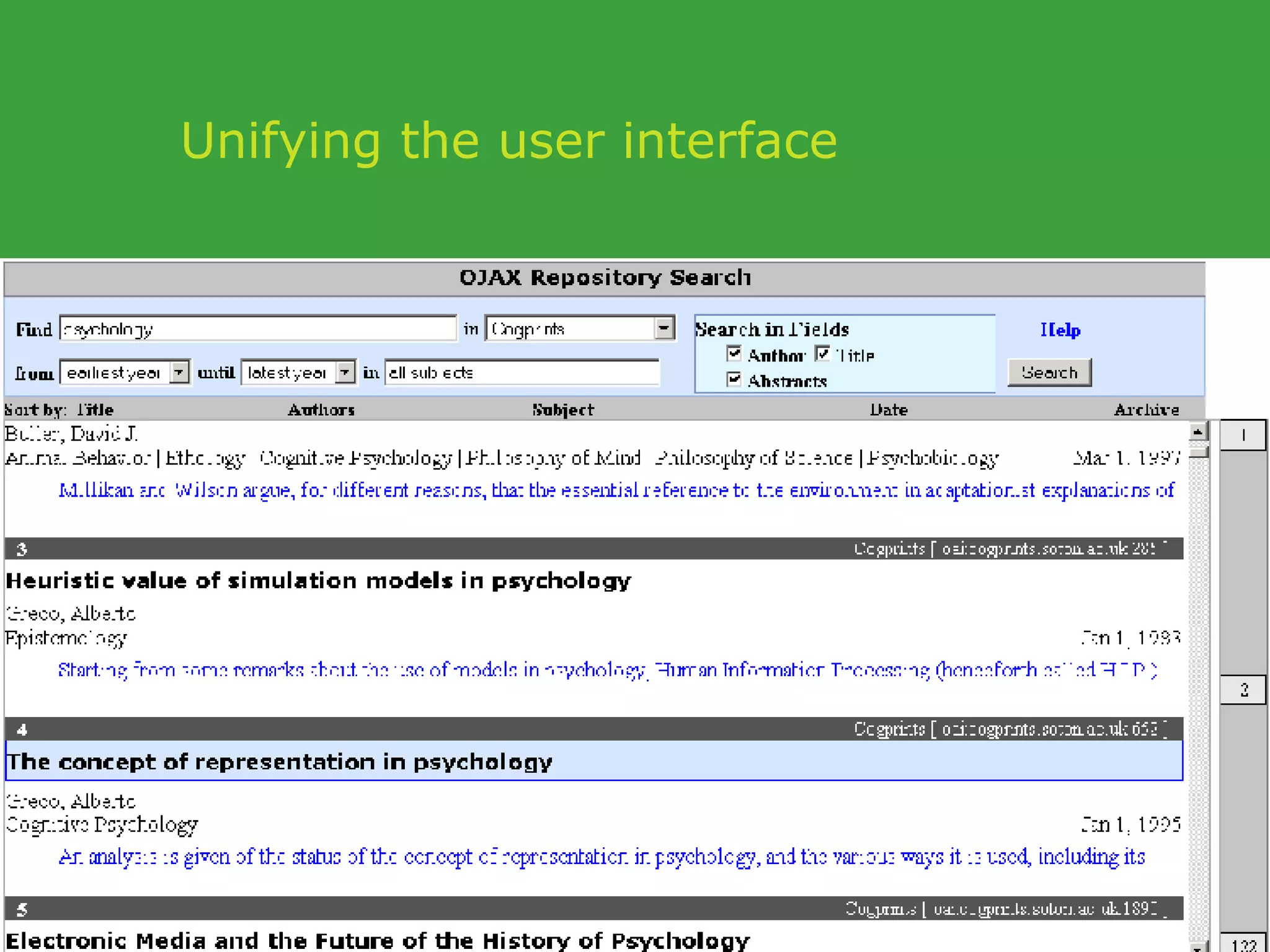
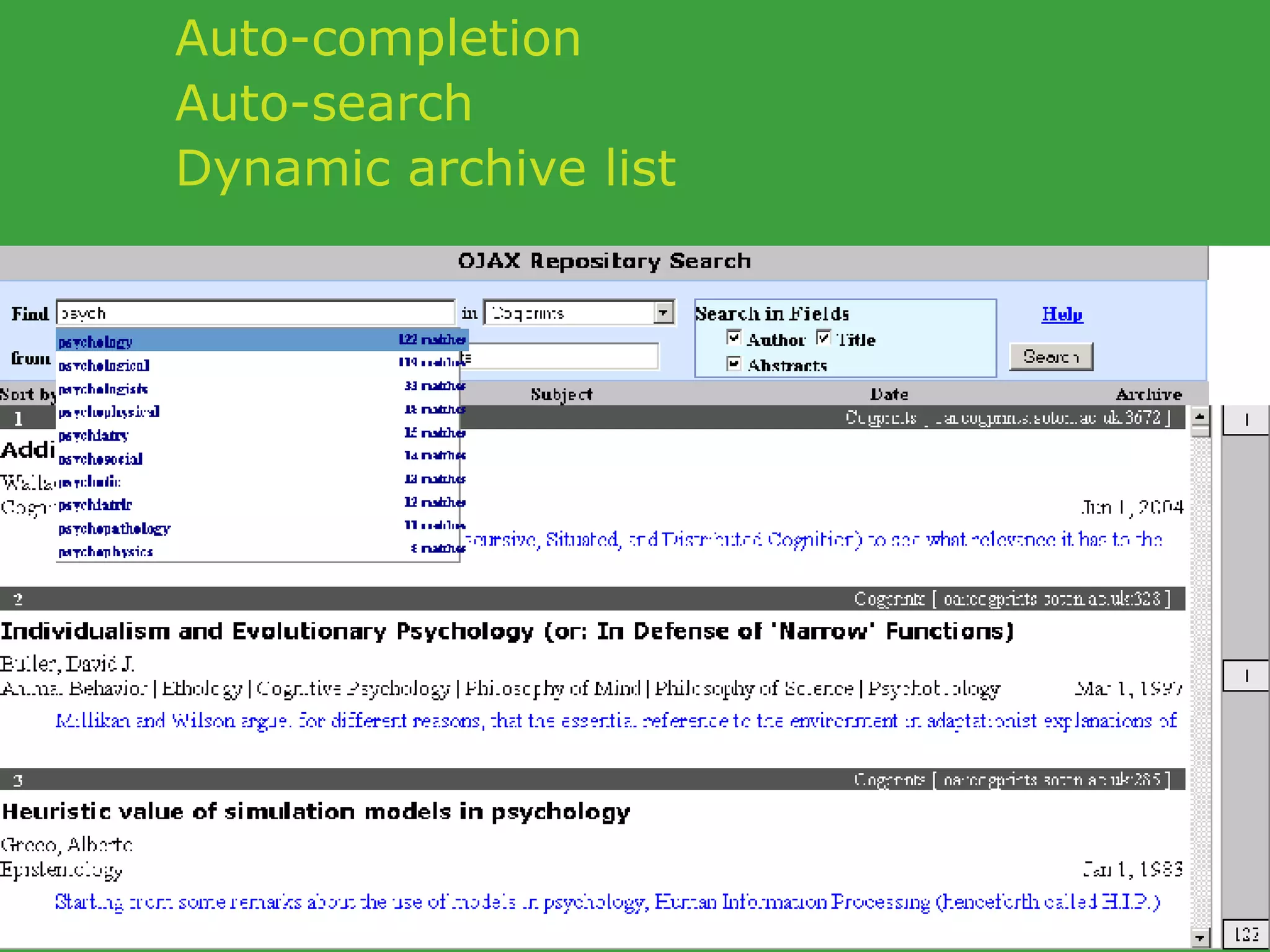
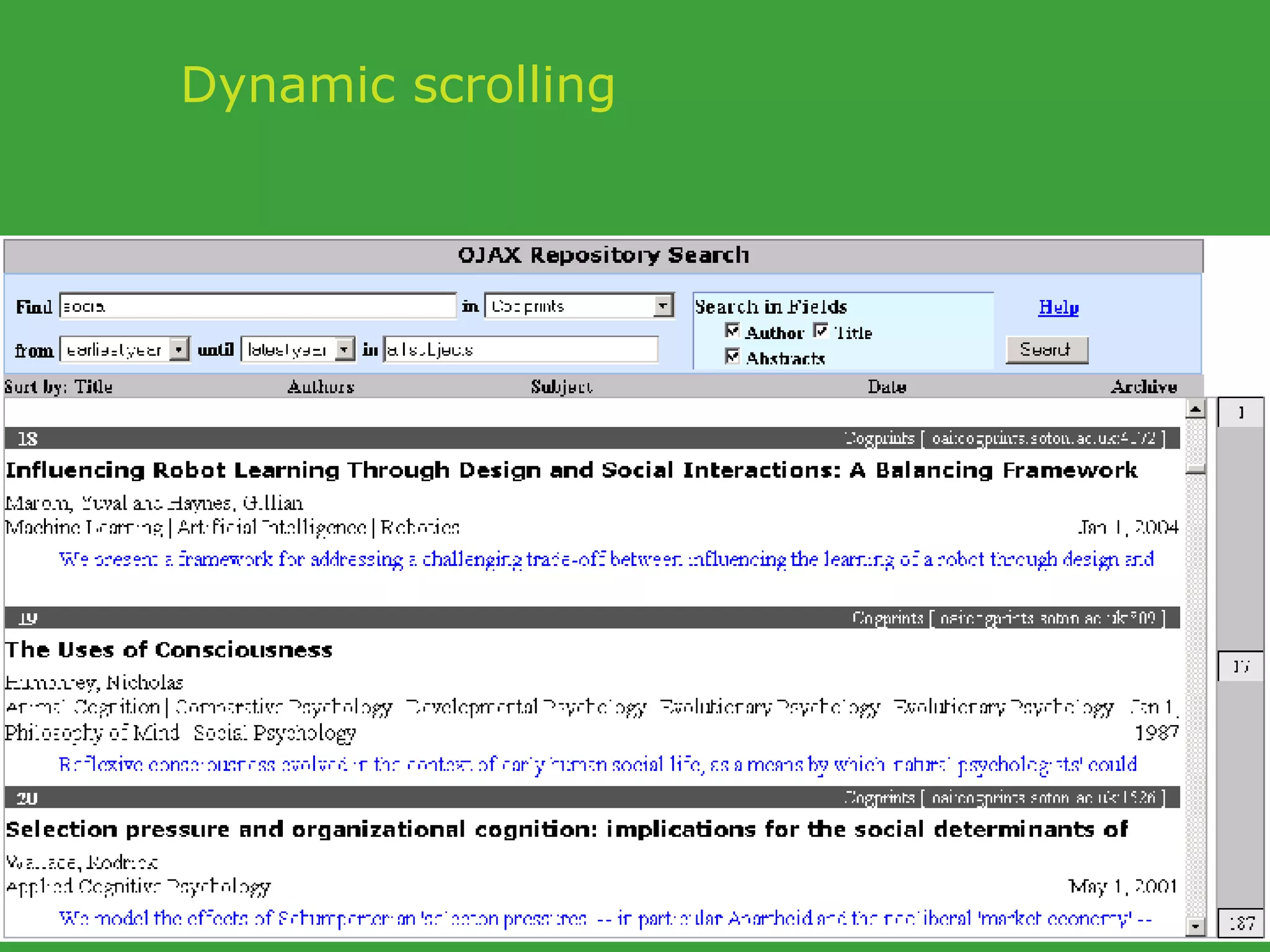
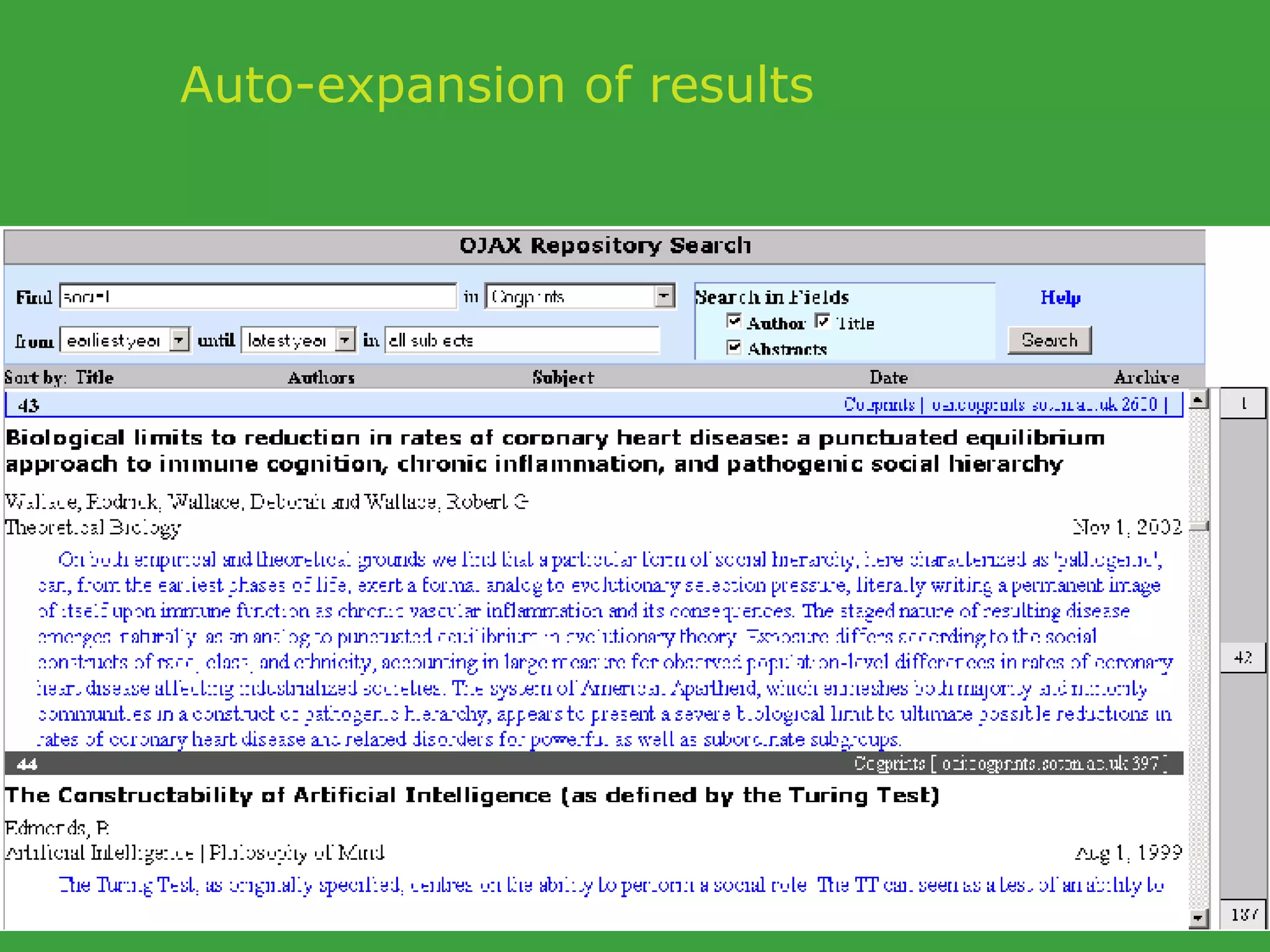
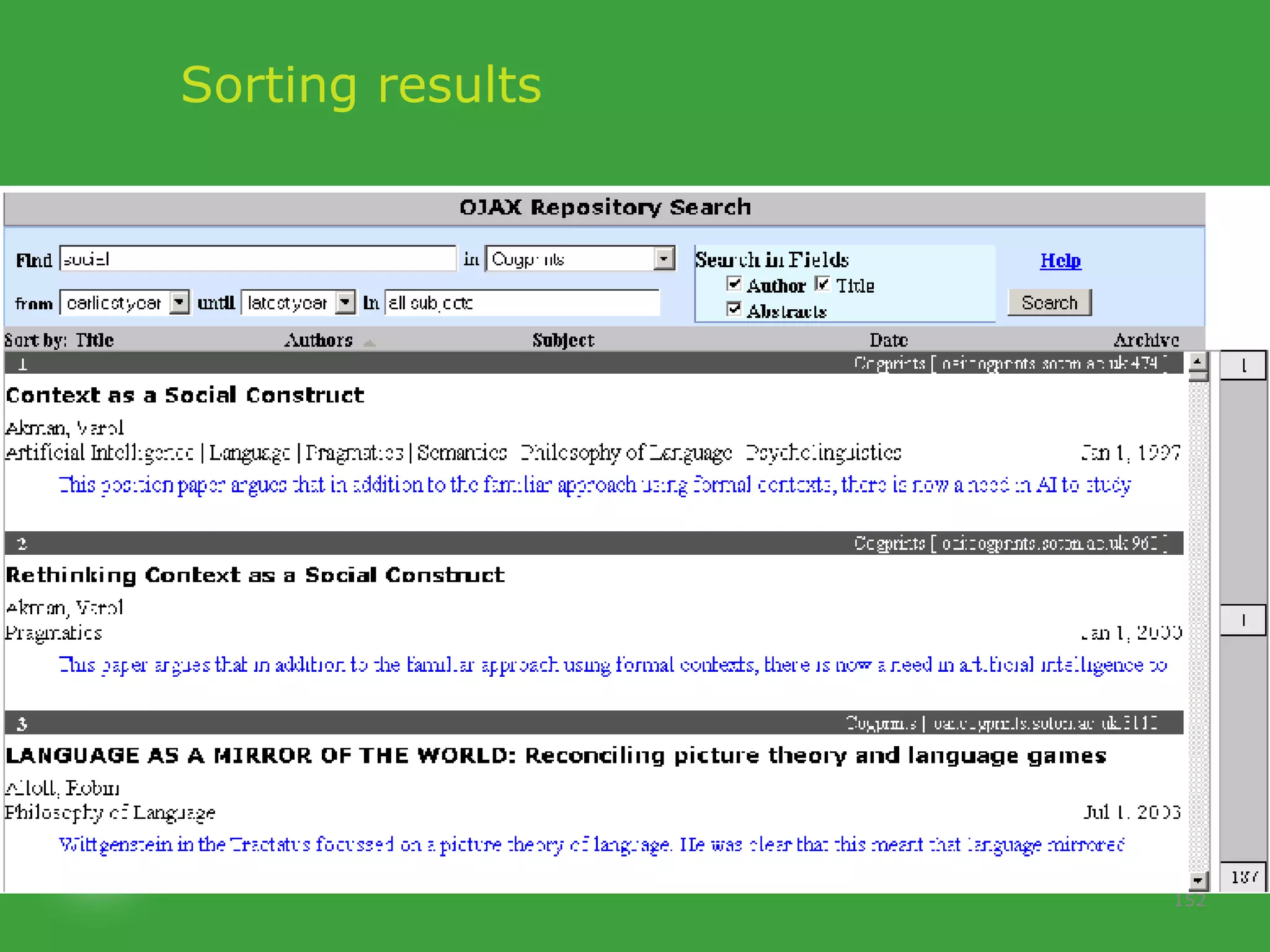
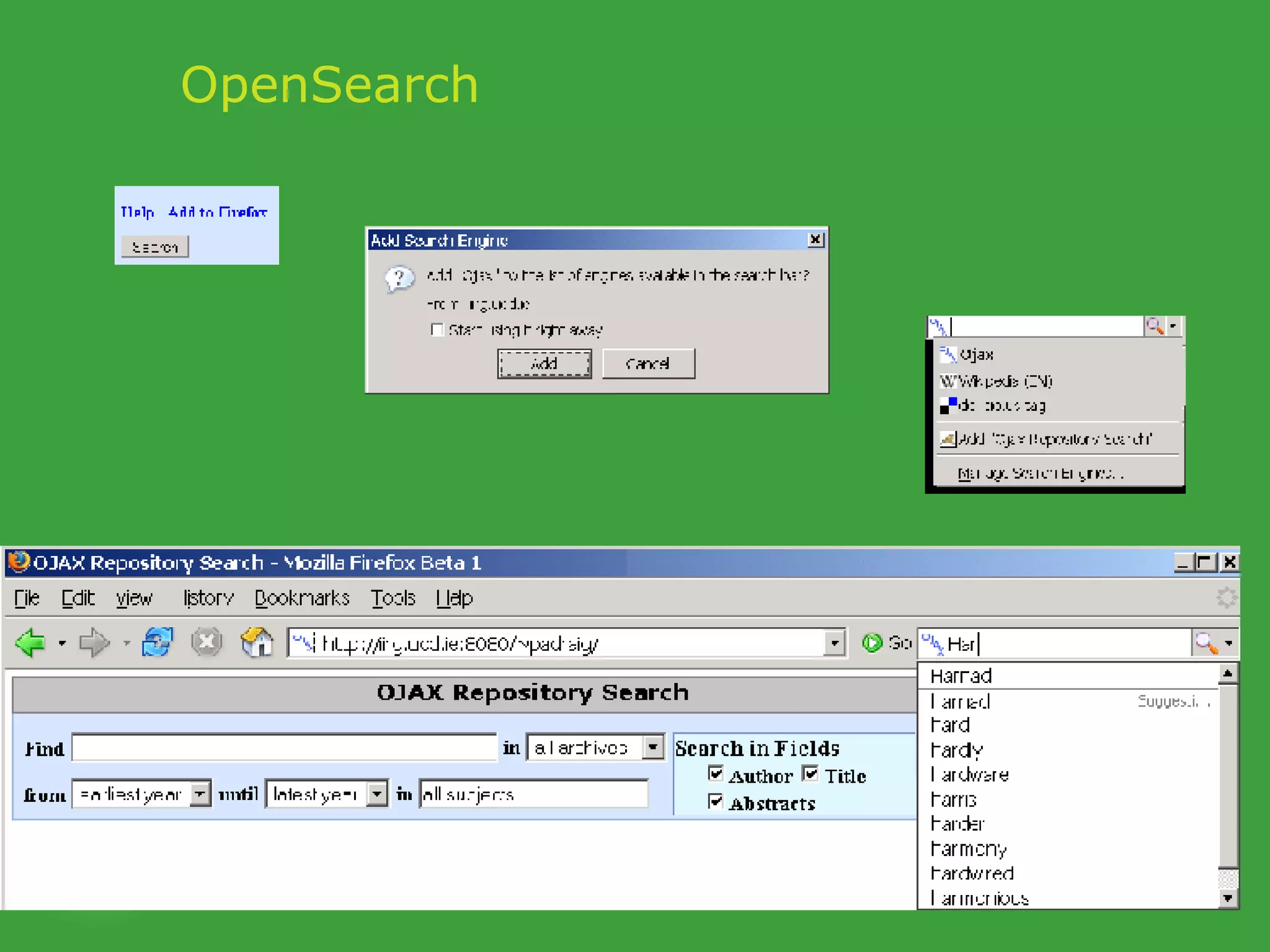

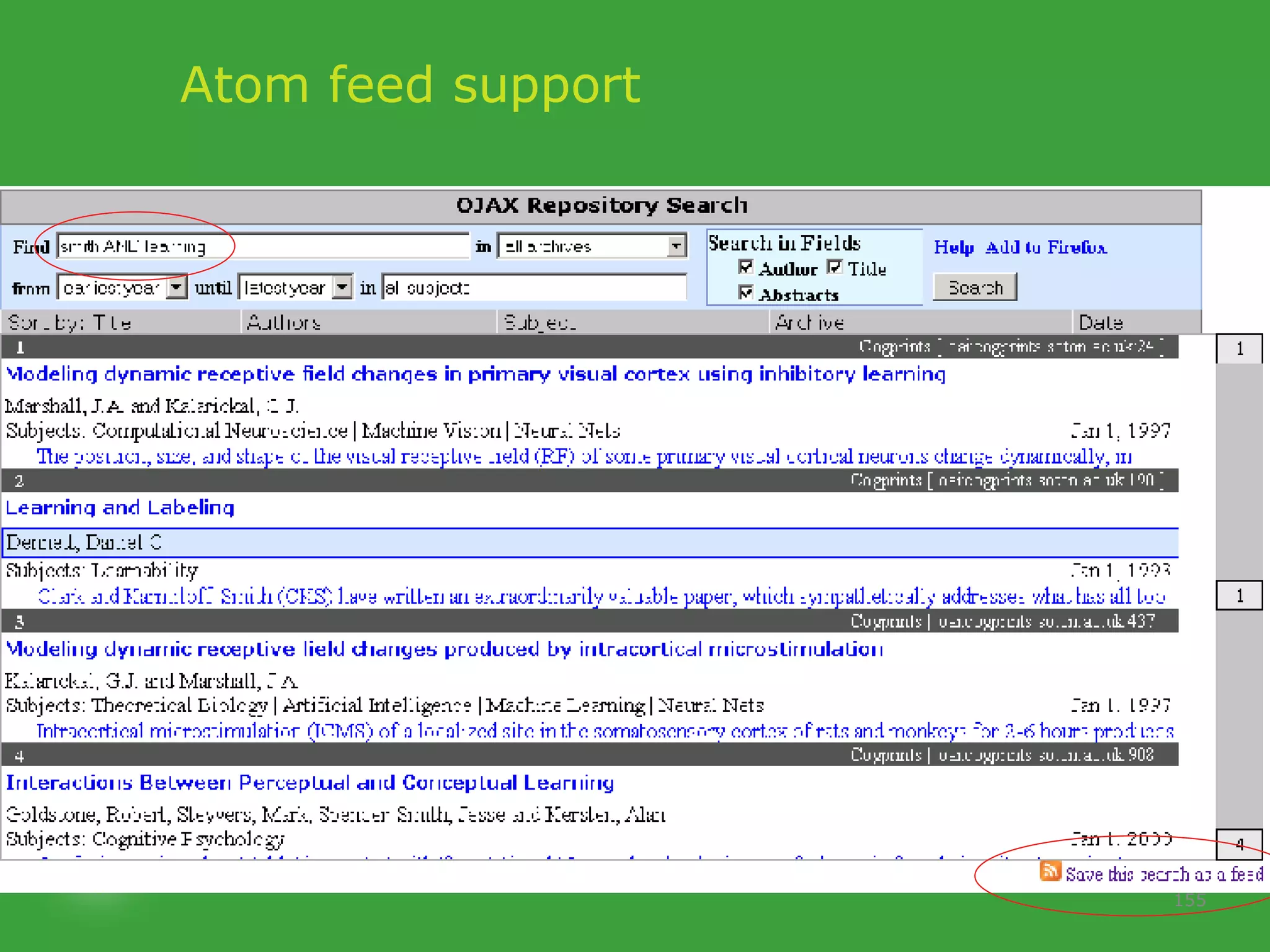
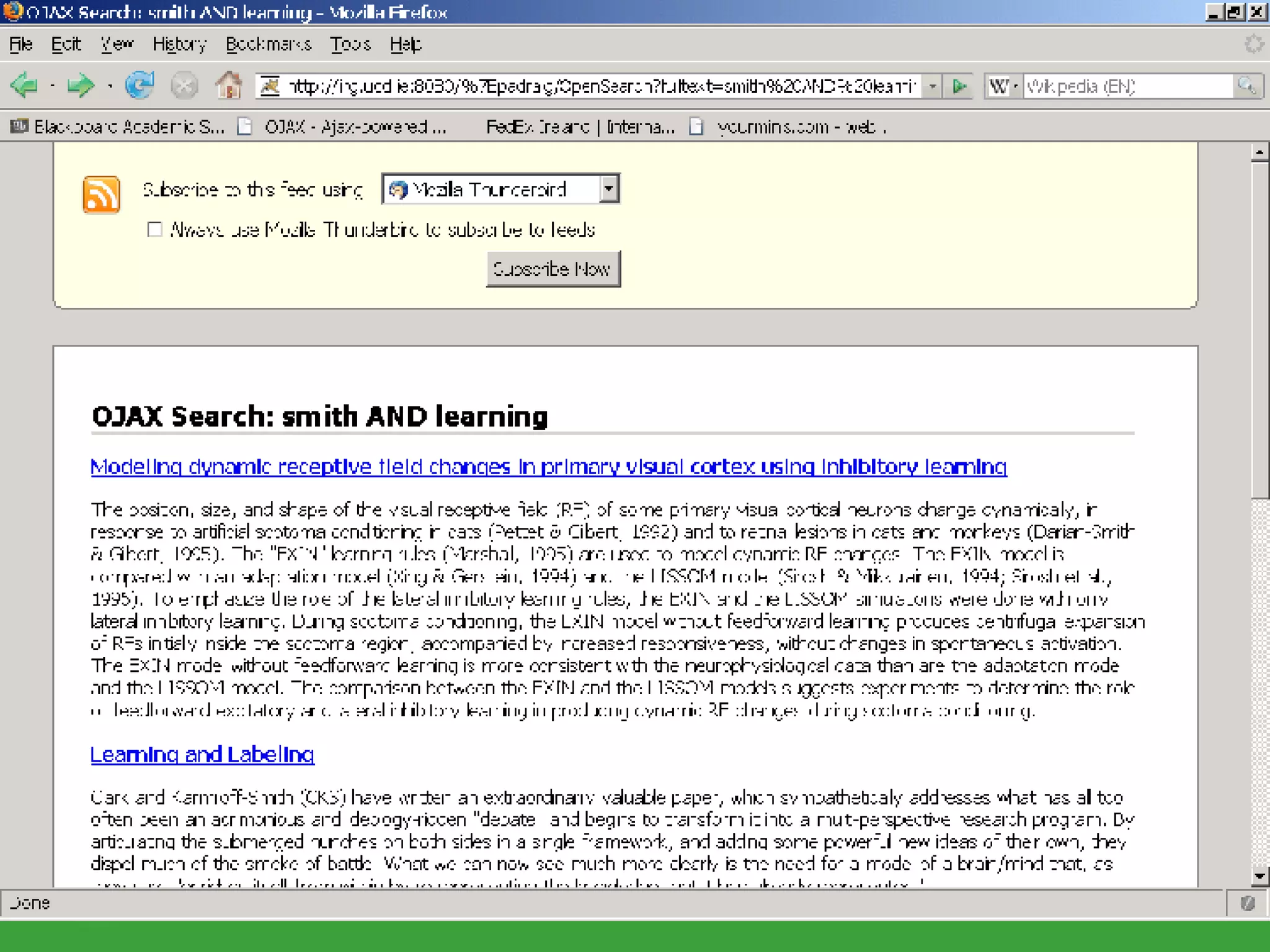
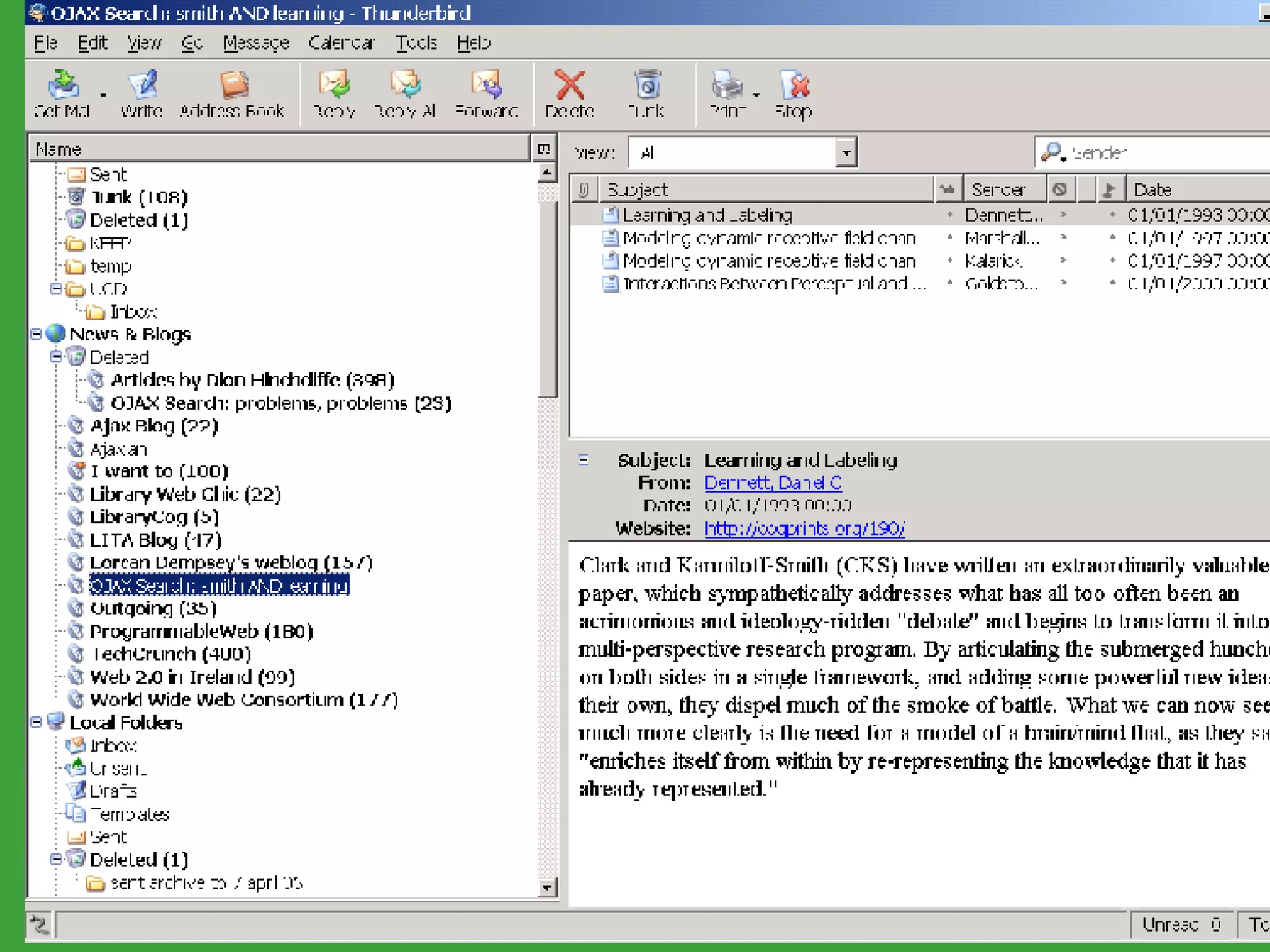
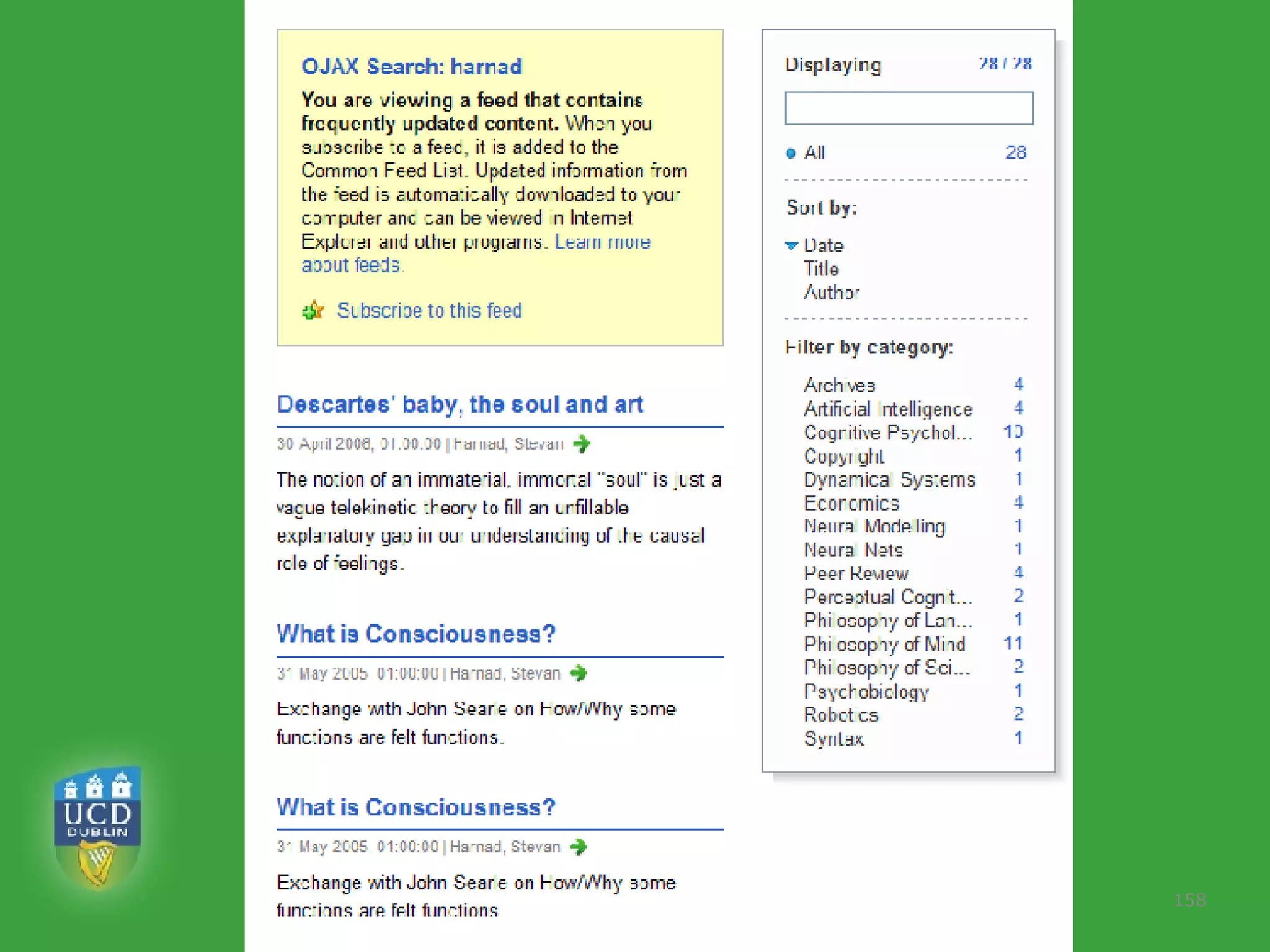


![PhD starting September 2007 In collaboration with UCD School of Computer Science and Informatics Requirements Honours degree (preferably first class or 2.1) in Computer Science or a related field or equivalent technical expertise Preferred Experience : Web technology JavaScript AJAX one of Java, Ruby or Python. http://www.ucd.ie/wusteman [email_address] .](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-162-2048.jpg)


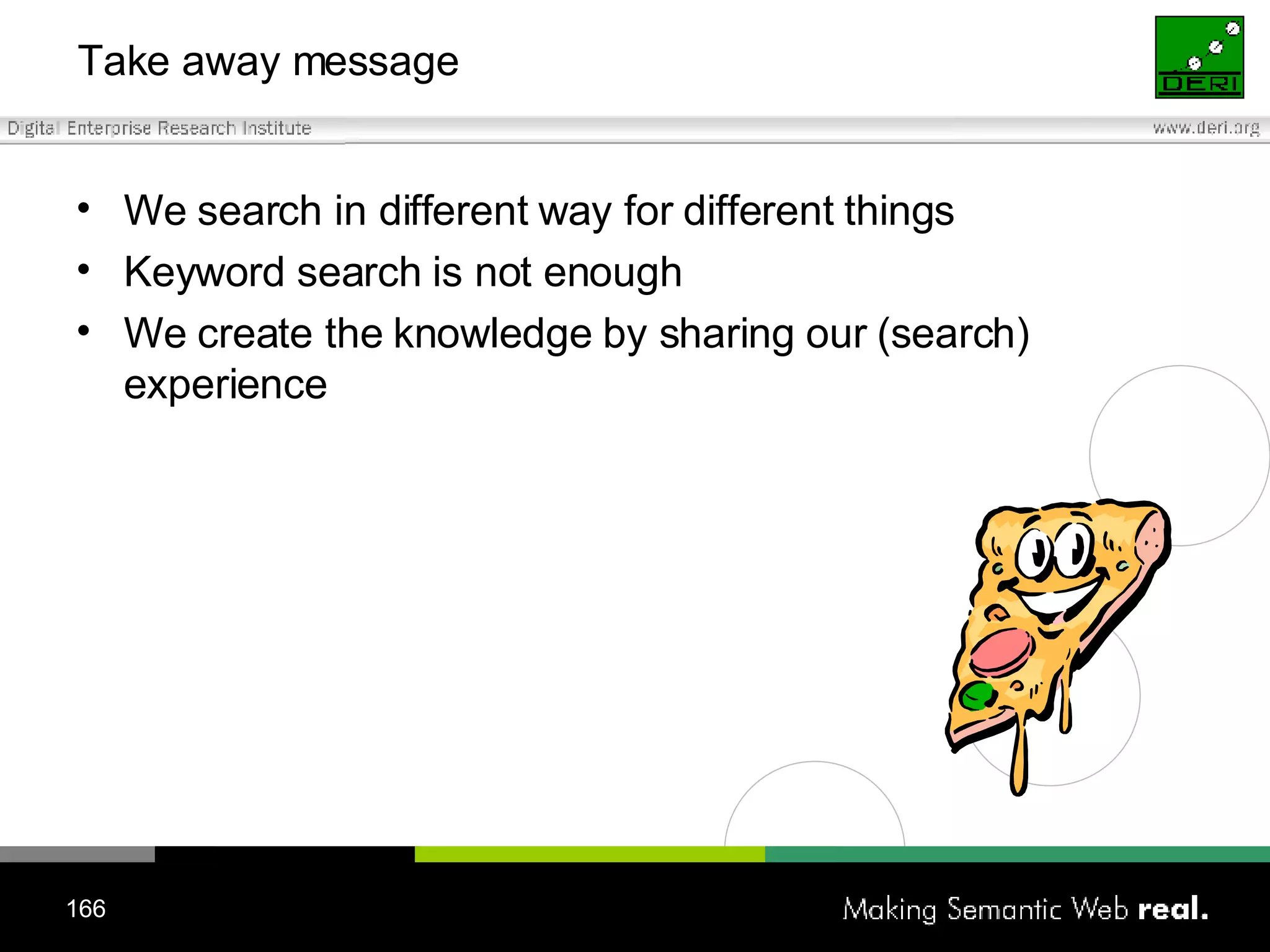
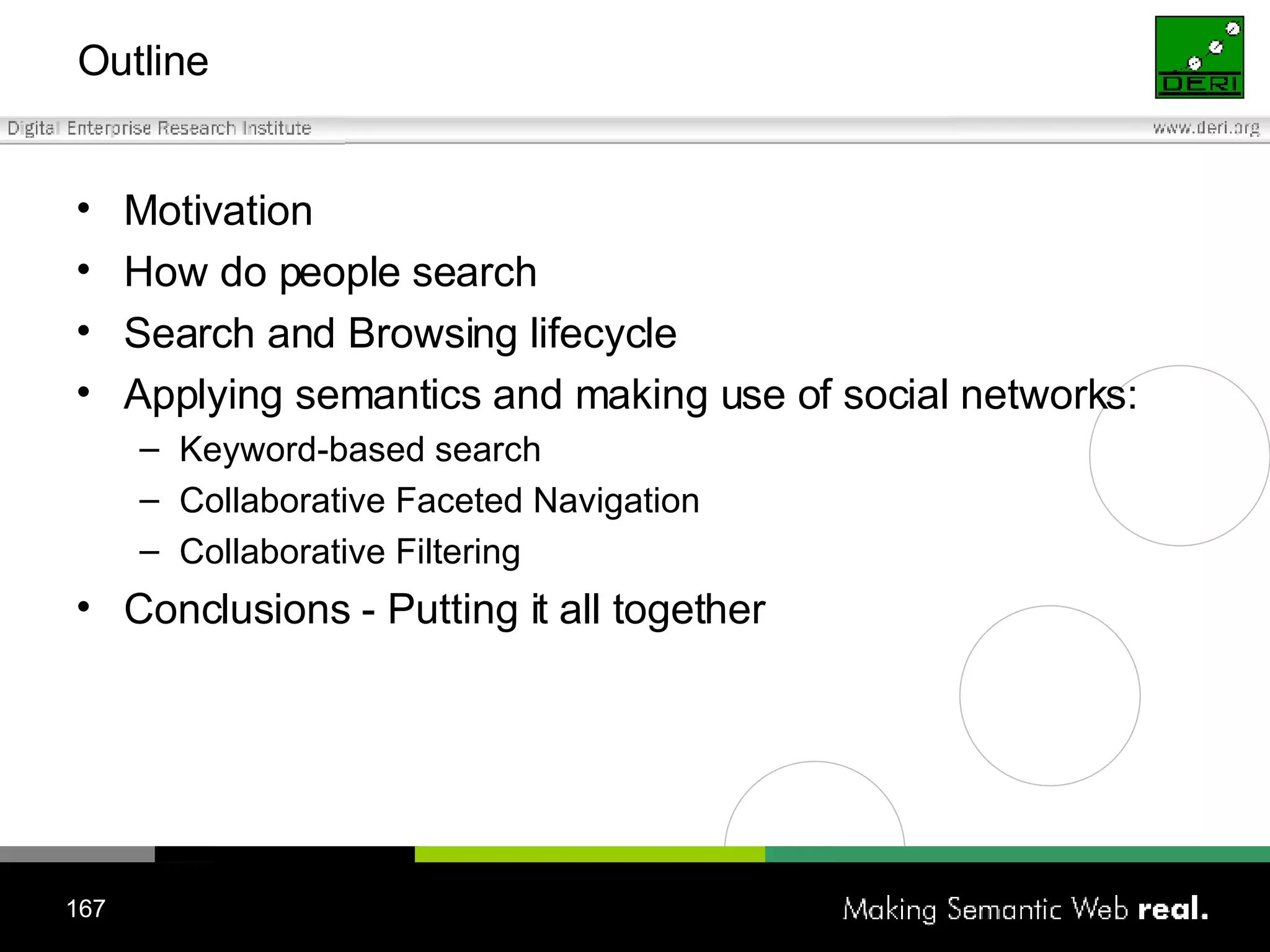

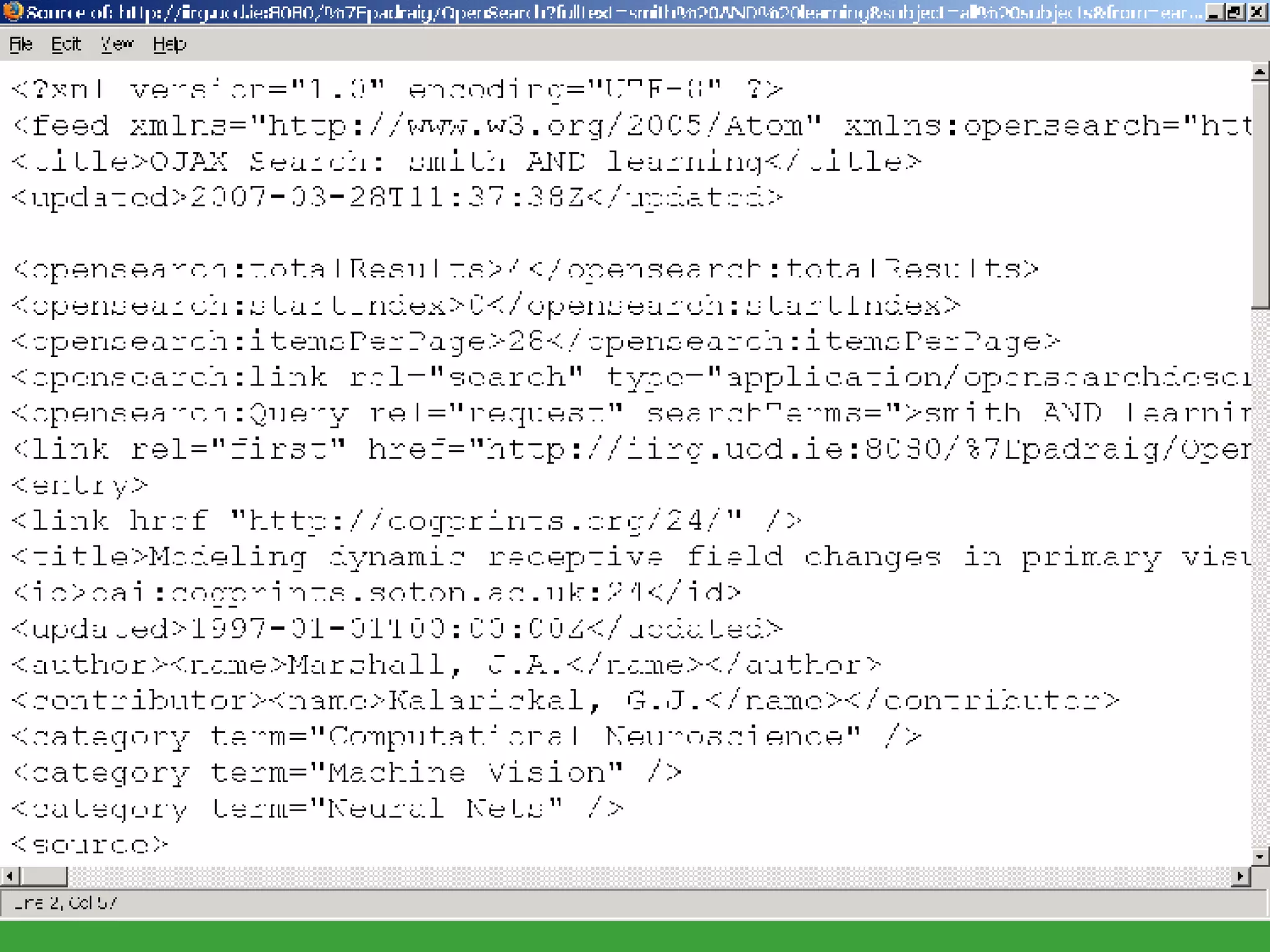
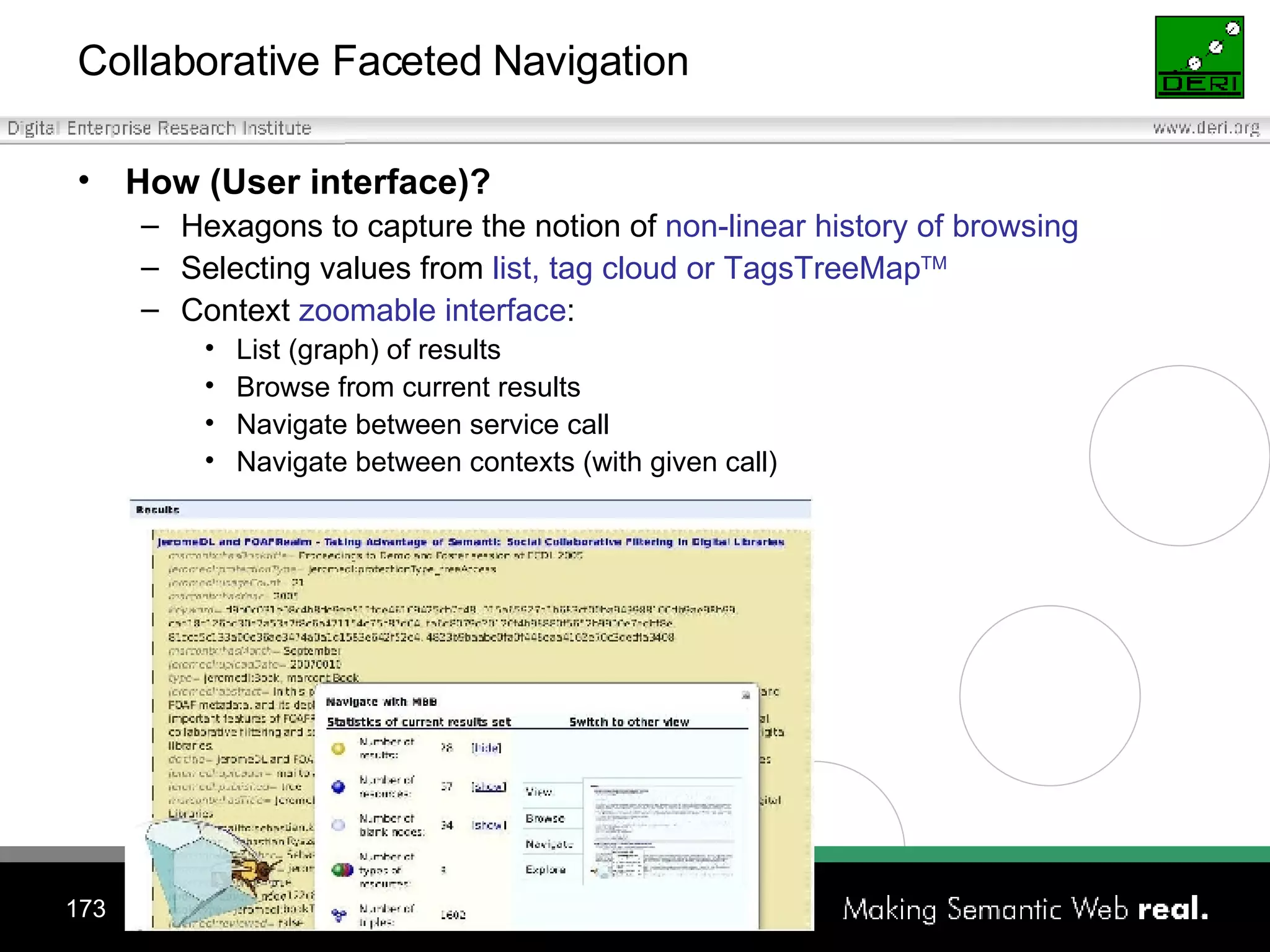
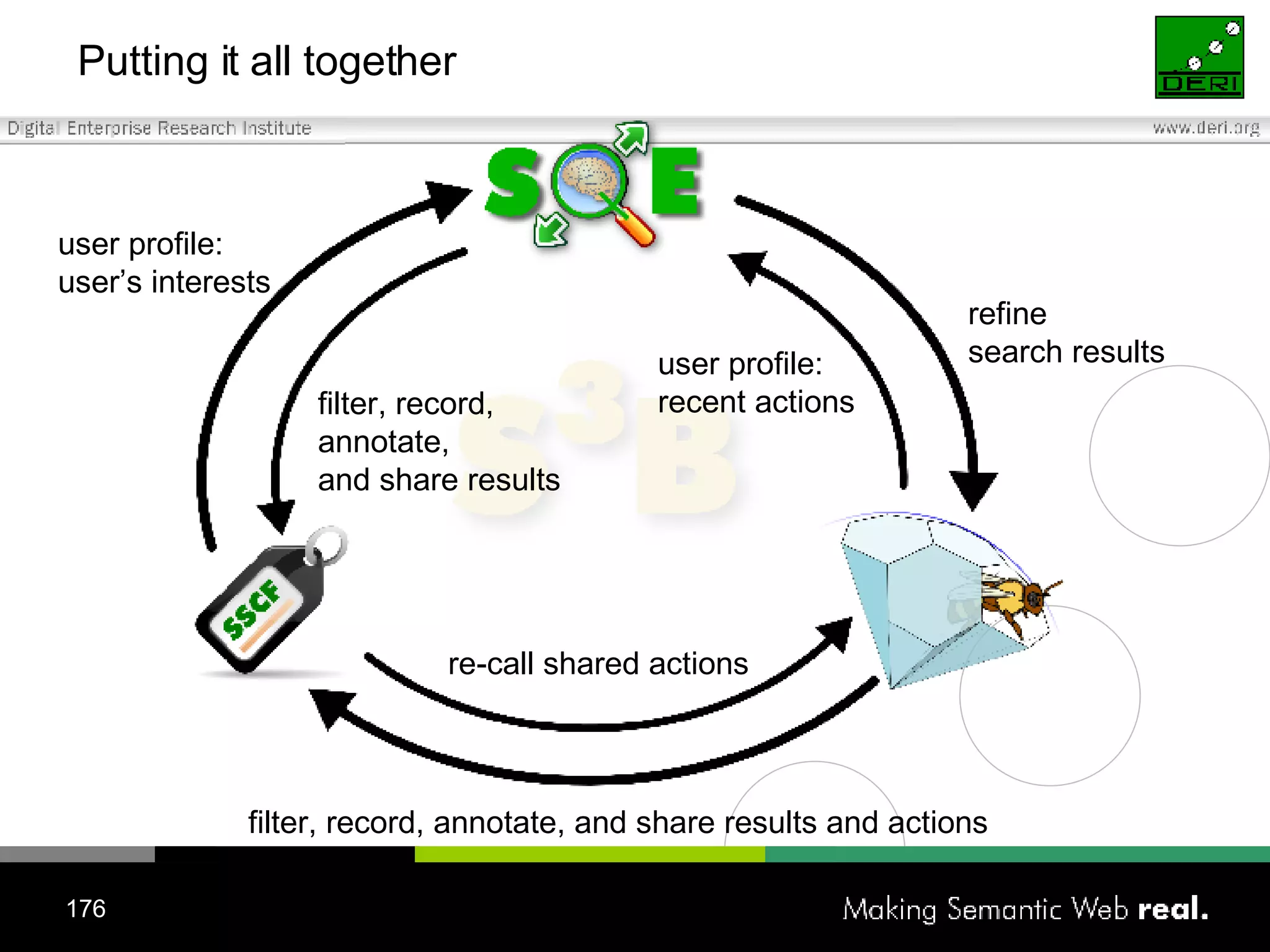
![Search and browsing lifecycle Why ? Information can be useful Information can be a garbage How ? (Search and browsing actions) [REUSE] keyword-based search (resource seeking) [REDUCE] faceted navigation (navigational) [RECYCLE] collaborative filtering (informational) Can this process be improved with Semantic Web and Social Networking technologies?](https://image.slidesharecdn.com/irish-digital-libraries-summit-20515/75/Irish-Digital-Libraries-Summit-169-2048.jpg)








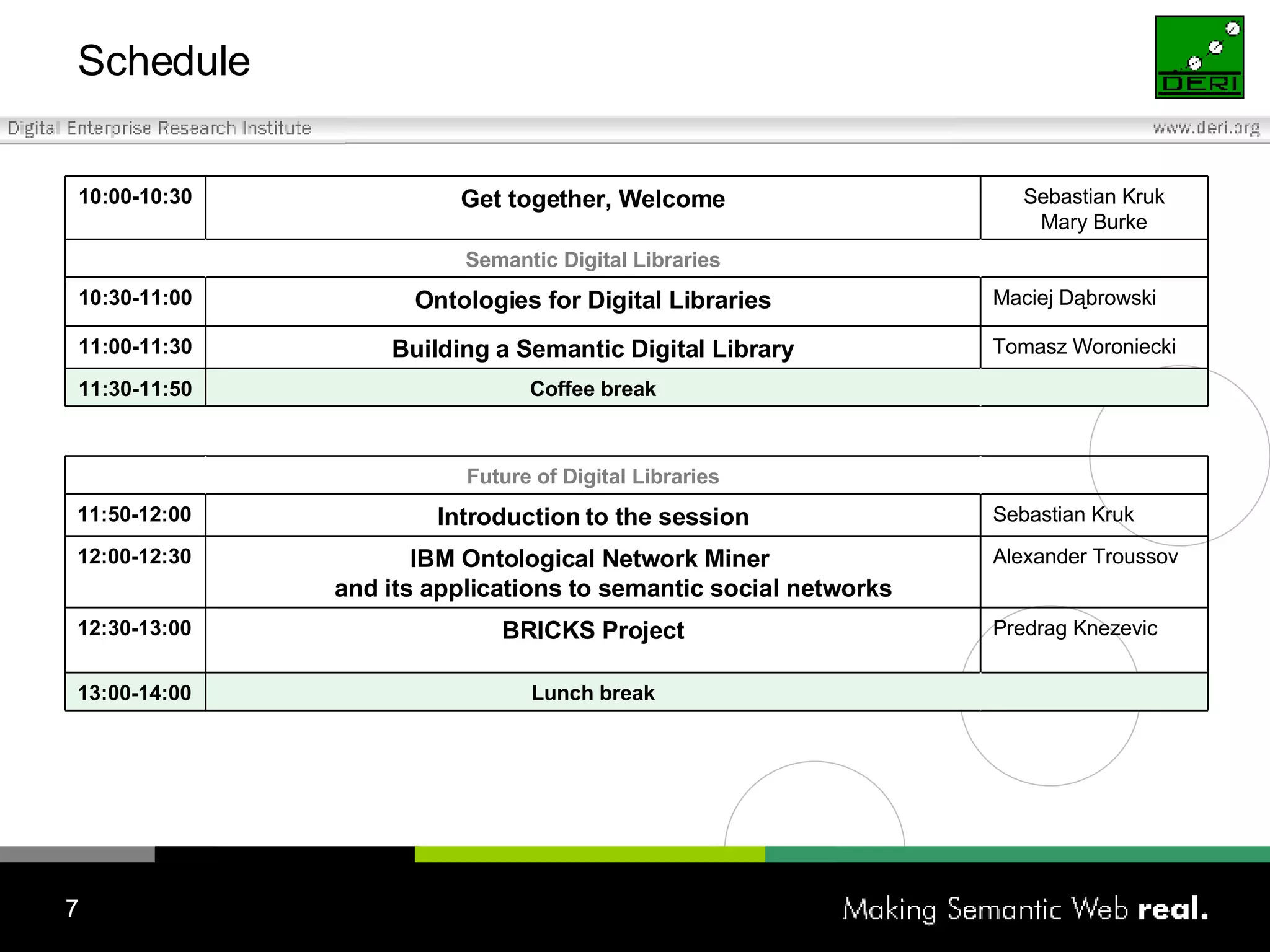
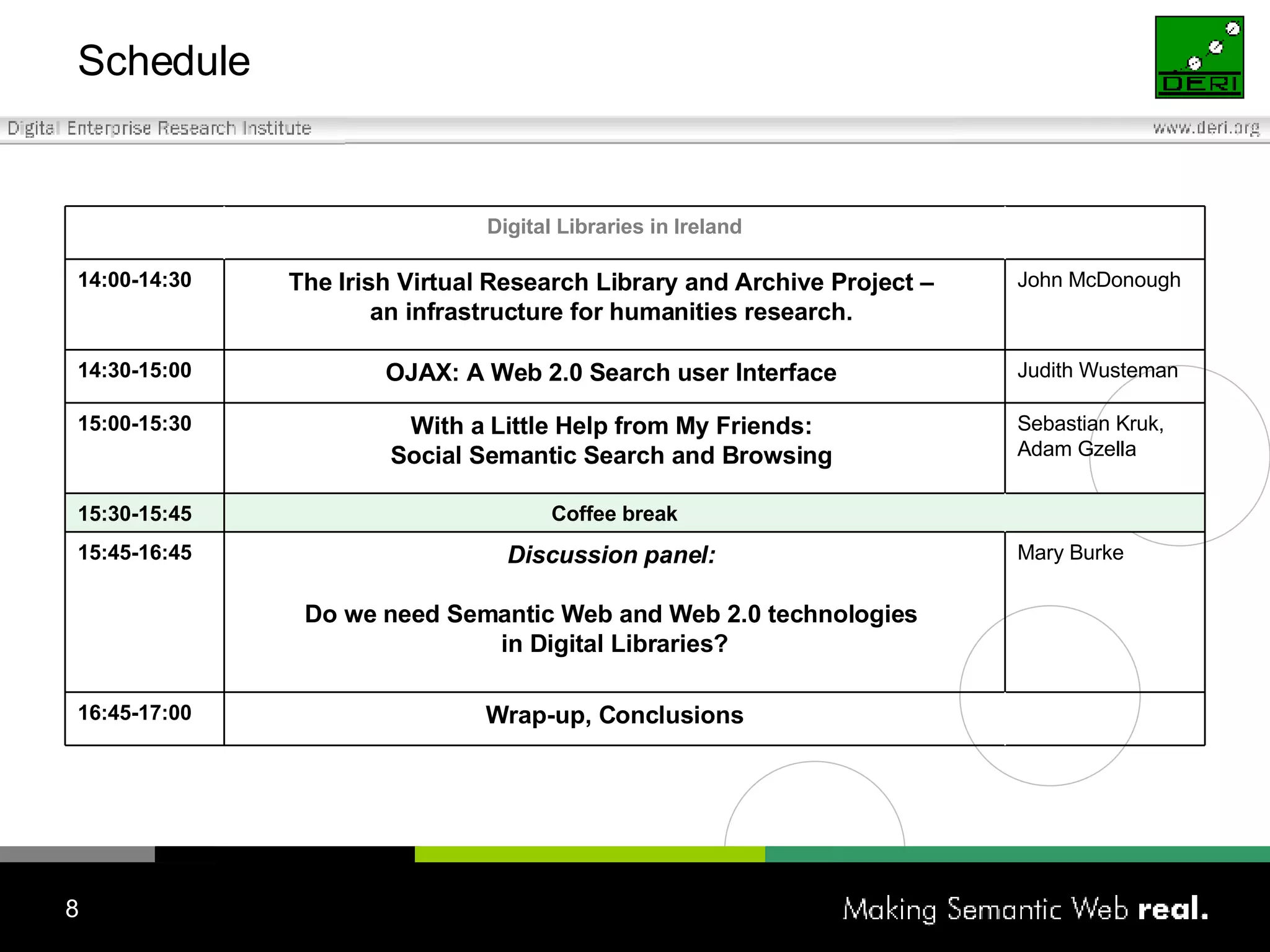
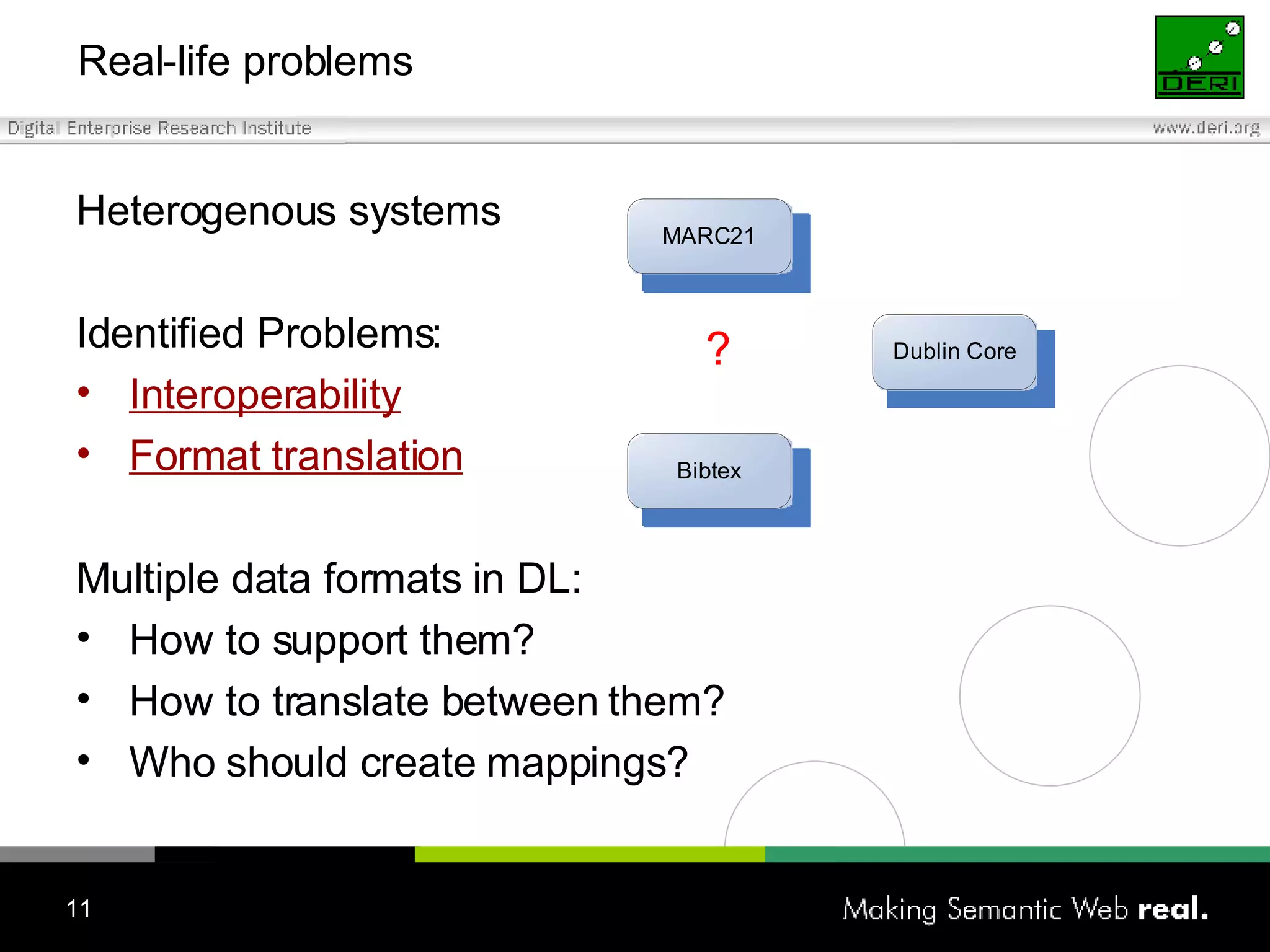
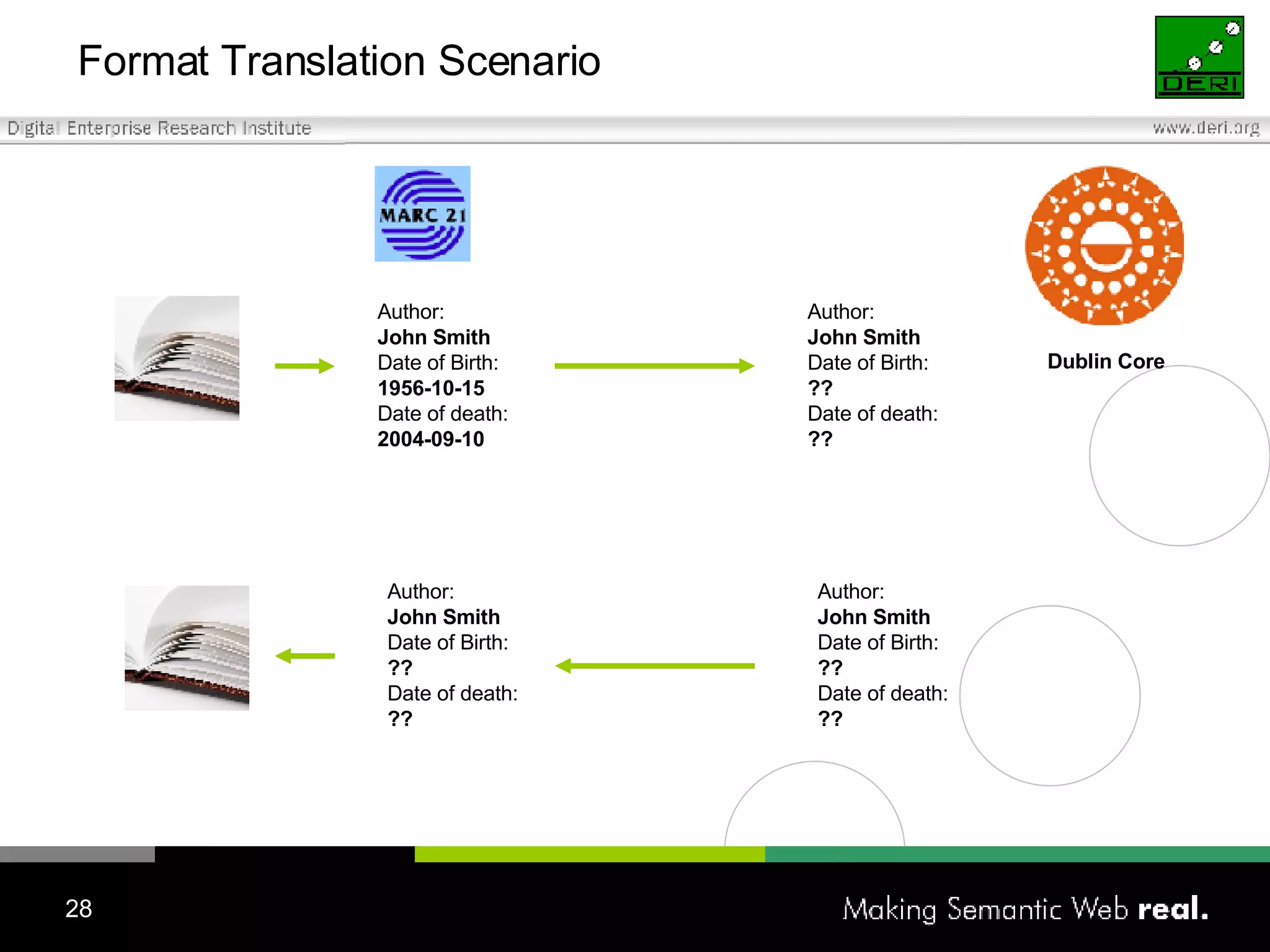
The Irish Digital Libraries Summit discusses the future of Irish digital libraries in the context of the next generation internet, focusing on creating a collaborative and semantic digital library environment. Presentations cover topics such as building semantic digital libraries, the challenges of interoperability and complex searches, and the development of tools for collaborative ontology creation. The initiative aims to enhance digital libraries' capabilities and involve community engagement by integrating existing bibliographic formats and supporting innovative search solutions.













































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






