Download to read offline


![Sample job: driver
public static void main(String[] a) throws Exception {
Configuration conf = new Configuration();
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(a[0]));
FileOutputFormat.setOutputPath(job, new Path(a[1]));
job.waitForCompletion(true);
}](https://image.slidesharecdn.com/20140427parallelprogrammingzlobinlecture11-140427125541-phpapp02/85/20140427-parallel-programming_zlobin_lecture11-2-320.jpg)







![Disco driver
job = Job().run(
input=["http://discoproject.org/media/text/chekhov.
txt"],
map=map,
reduce=reduce)
for word, count in result_iterator(job.wait(show=True)):
print(word, count)](https://image.slidesharecdn.com/20140427parallelprogrammingzlobinlecture11-140427125541-phpapp02/85/20140427-parallel-programming_zlobin_lecture11-10-320.jpg)



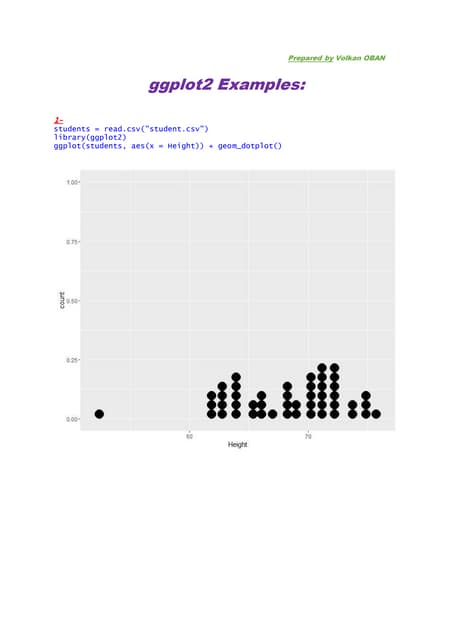
This document provides examples and snippets of code for MapReduce, Pig, Hive, Spark, Shark, and Disco frameworks. It also includes two sections of references for related papers and Disco documentation. The examples demonstrate basic MapReduce jobs with drivers, mappers, and reducers in Java, Pig and Hive queries, Spark and Shark table operations, and a Disco MapReduce job.