Download to read offline





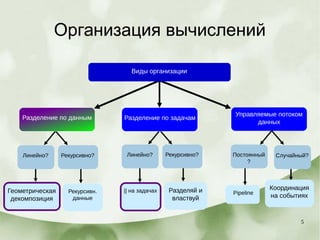





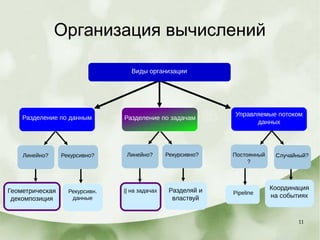



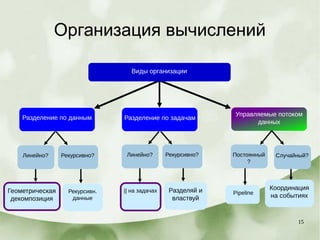








Документ описывает этапы разработки программного обеспечения, включая выбор алгоритмов и структур для реализации, а также принципы проектирования, такие как эффективность и масштабируемость. Рассматриваются различные модели организации вычислений, включая параллельные циклы, геометрическую декомпозицию и обработку потоков данных. Также упоминаются примеры и техники управления задачами в параллельных вычислениях, включая библиотеки OpenMP и TBB.















































