Download as PDF, PPTX




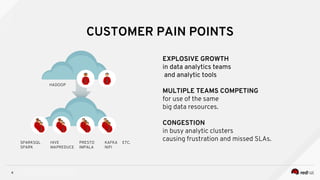
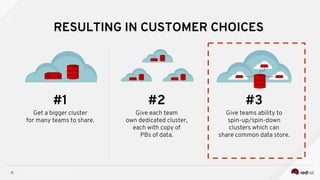
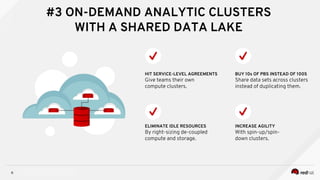
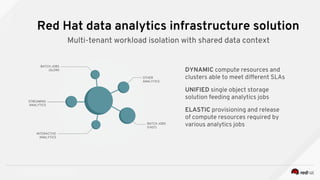


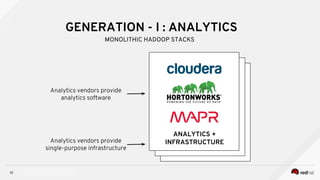
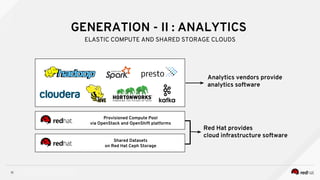
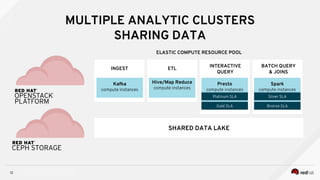
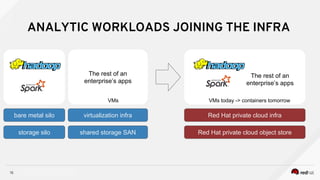
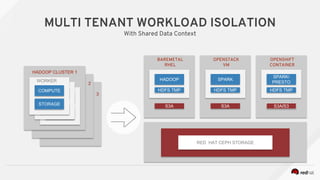
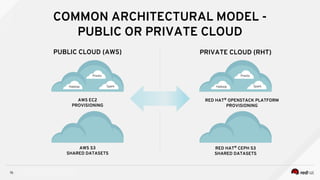


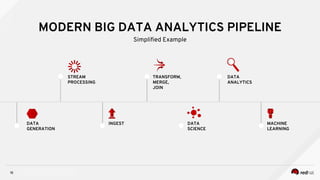


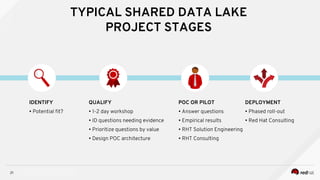







Managing Data Analytics in a Hybrid Cloud discusses challenges with traditional analytics approaches and proposes using shared data lakes with dynamic compute clusters. Common challenges include explosive analytics team growth leading to resource contention, and duplicating large datasets for each cluster. The proposed approach uses shared object storage to hold unified datasets accessed by multiple ephemeral analytics clusters provisioned on-demand. This allows teams independent resources while avoiding duplicate storage costs and improving agility. The document outlines example architectures and benefits of this shared data lake approach when implemented on a private or public cloud.


































































