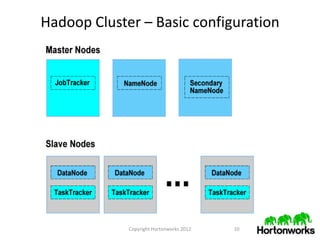
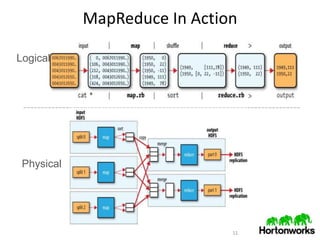
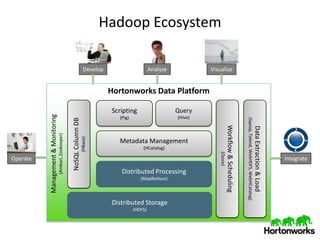
This document provides an overview of the Hadoop ecosystem. It discusses what big data is, characteristics of big data like volume, velocity and variety. It then describes the problems with legacy solutions and how Hadoop provides an improved approach by processing data locally, expecting hardware failures and handling failover elegantly. The core components of Hadoop like HDFS, MapReduce, YARN and HBase are explained. Finally, it discusses what's next in terms of downloading Hadoop, using support and training resources from Hortonworks.