Downloaded 577 times





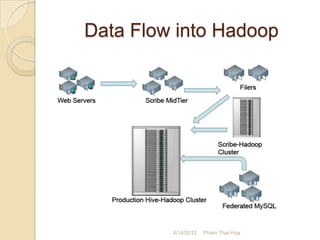


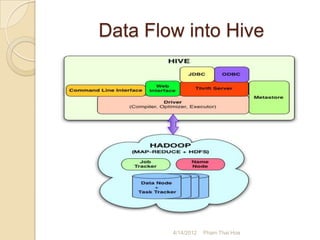










The document is a presentation by Pham Thai Hoa from 4/14/2012 about Hadoop, Hive, and how they are used at Mobion. It introduces Hadoop and Hive, explaining what they are, why they are used, and how data flows through them. It also discusses how Mobion uses Hadoop and Hive for log collection, data transformation, analysis, and reporting. The presentation concludes with Q&A and links for further information.





















































































