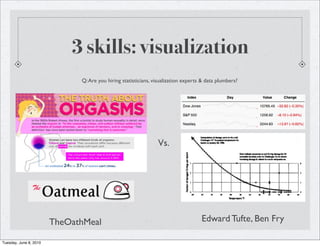
The document discusses the rise of big data and data science. It notes that while companies were dealing with medium sized data in the past, data is growing exponentially due to the internet and technologies like sensors. This growth is outpacing disk I/O performance, necessitating new database approaches like NoSQL and MapReduce. The key skills of data scientists are described as statistics, visualization, and data plumbing like cleaning, transforming and structuring large datasets. More data is also said to beat smart algorithms in many cases.













![3 skills: data plumbing
Glue languages: Python, Perl, regex, XSLT
Admin: setting up, maintaining clusters
Affinity with OSS & *nix
NoSQL = NoSchema = Transform Data
/^([w!#$%&'*+-/=?^`{|}~]+.)*[w!#$%&
'*+-/=?^`{|}~]+@((((([a-z0-9]{1}[a-z0-9-]{0,62}[a-
z0-9]{1})|[a-z]).)+[a-z]{2,6})|(d{1,3}.){3}d{1,3}(:d{1,5})?)$/i
Tuesday, June 8, 2010](https://image.slidesharecdn.com/bigdatabodenseebarcamp-100608035009-phpapp01/85/Big-Data-Bodensee-Barcamp-2010-14-320.jpg)






































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










