Download as PDF, PPTX





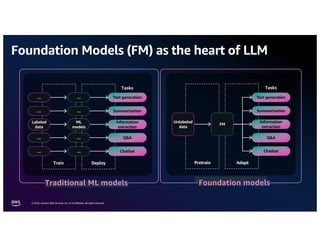

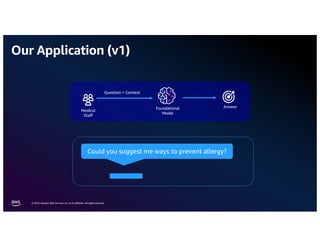

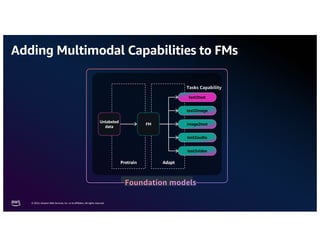



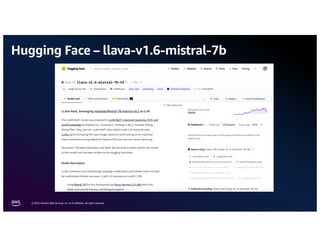
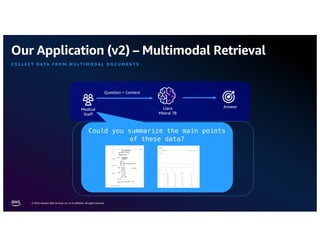
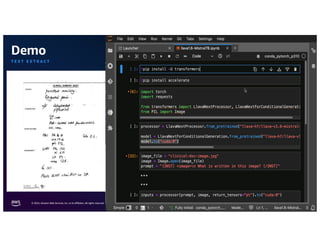
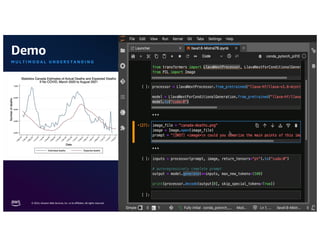
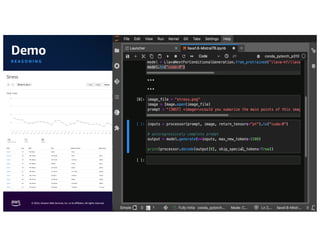





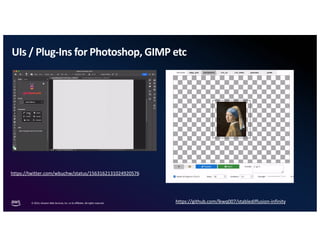
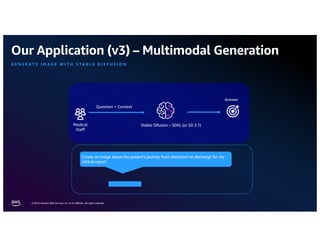
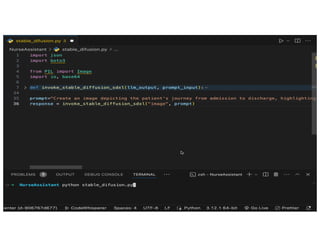



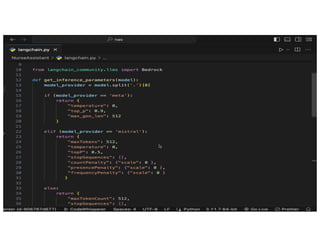
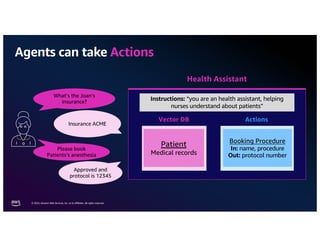


The document discusses the concept of multimodality within large language models (LLMs) and how it enhances various applications such as question answering, medical assistance, and advertising. It highlights the integration of foundation models for tasks like text generation and image analysis, offering multiple use cases including virtual try-on and visual question answering. Additionally, it introduces frameworks like Langchain for simplifying LLM applications and outlines multimodal capabilities in generating and retrieving data.






























































