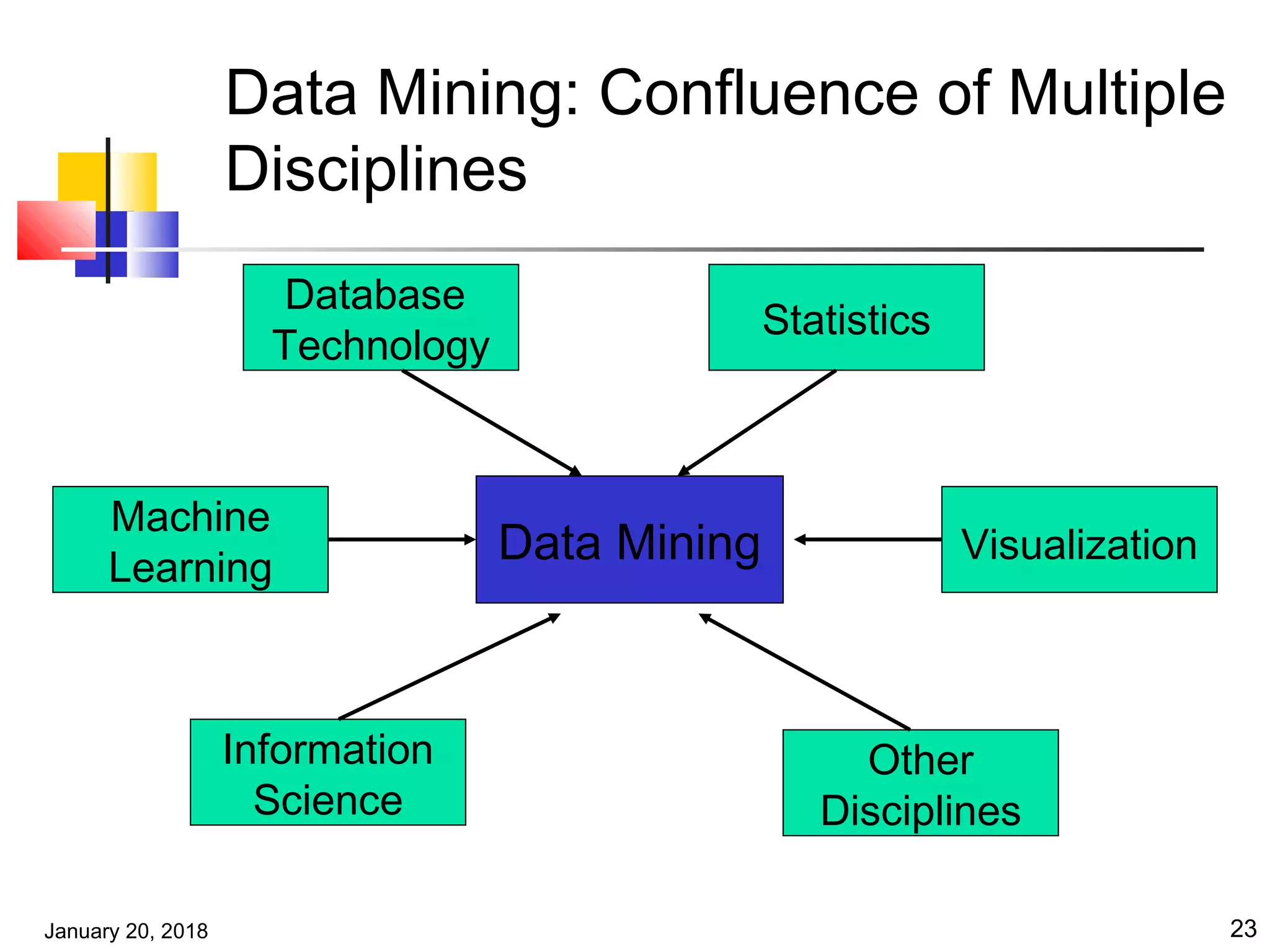
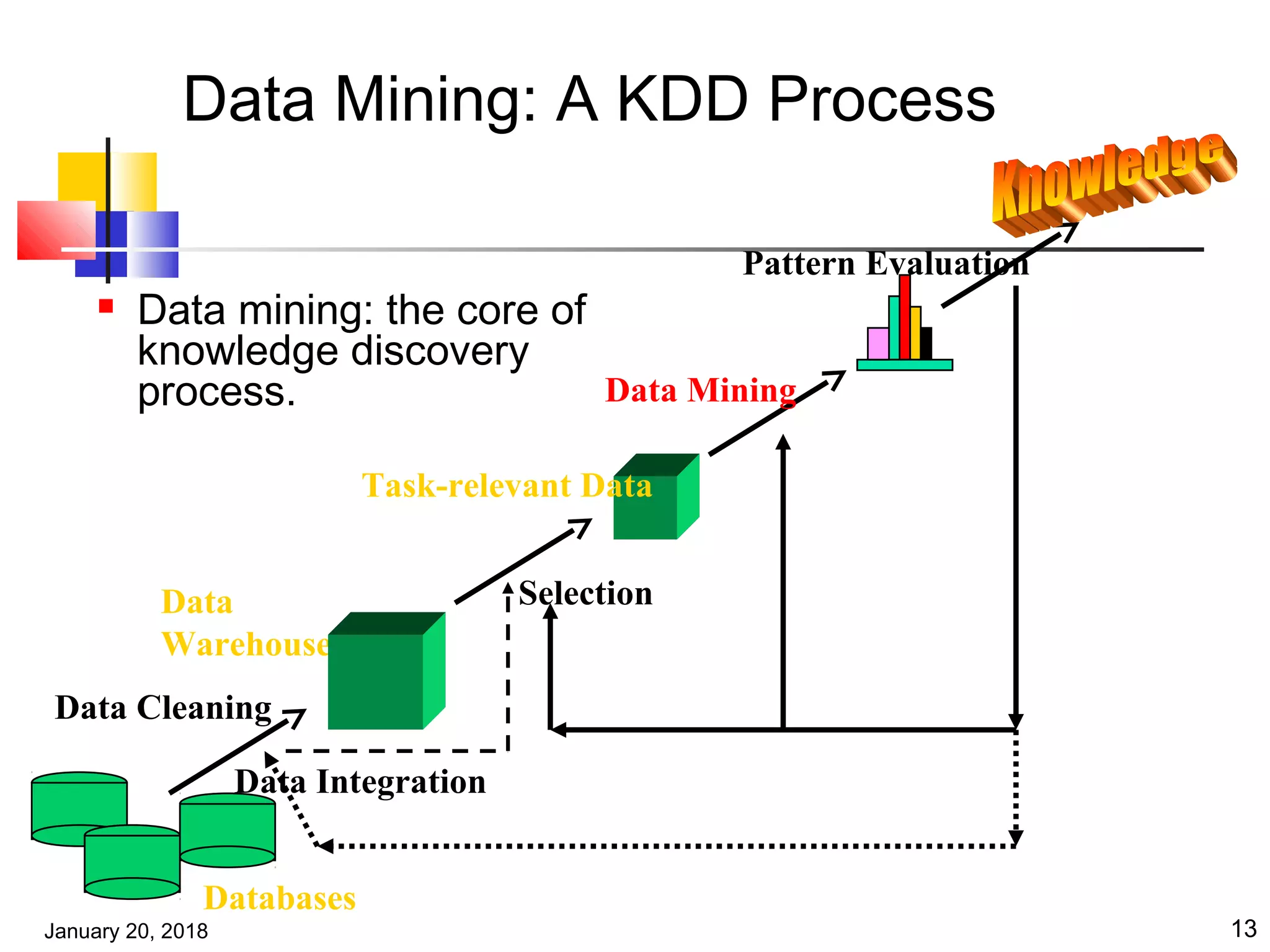
The document provides an introduction to data mining concepts and techniques. It discusses the motivation for data mining due to vast amounts of stored data. It defines data mining as the extraction of interesting and potentially useful patterns from large databases. The document also outlines the key steps in a knowledge discovery process, including data cleaning, transformation, mining, and evaluation. It surveys the major applications and functionalities of data mining, as well as issues that require further research.













![January 20, 2018 18
Data Mining Functionalities (1)
Concept description: Characterization and
discrimination
Generalize, summarize, and contrast data
characteristics, e.g., dry vs. wet regions
Association (correlation and causality)
Multi-dimensional vs. single-dimensional association
age(X, “20..29”) ^ income(X, “20..29K”) buys(X,
“PC”) [support = 2%, confidence = 60%]
contains(T, “computer”) contains(x, “software”) [1%,
75%]](https://image.slidesharecdn.com/1intro-180120120259/75/1intro-18-2048.jpg)