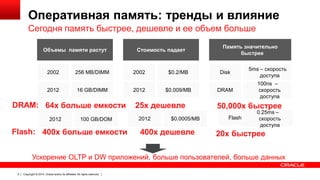
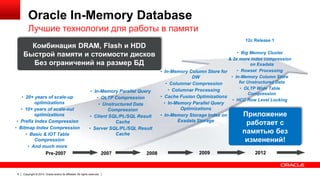
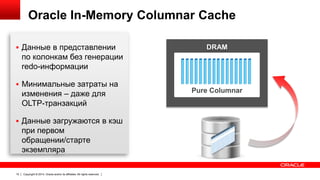
Downloaded 37 times








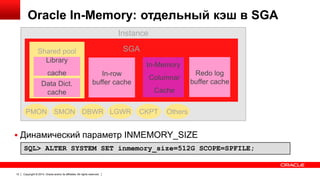
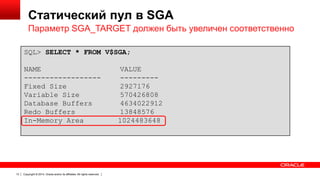
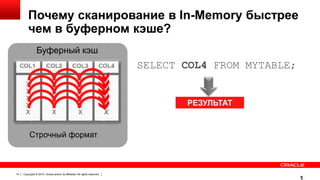

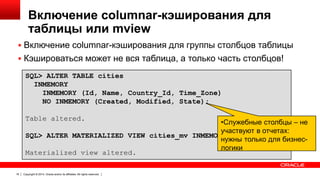







![Новые параметры в init.ora
INMEMORY_SIZE
INMEMORY_FORCE= { DEFAULT | OFF }
INMEMORY_CLAUSE_DEFAULT= [INMEMORY] [NO INMEMORY]
[compression-clauses][priority-clauses]
INMEMORY_QUERY={ENABLE | DISABLE}
INMEMORY_MAX_POPULATE_SERVERS
OPTIMIZER_INMEMORY_AWARE
INMEMORY_TRICKLE_REPOPULATE_SERVERS_PERCENT
Copyright © 2014, Oracle and/or its affiliates. 38 All rights reserved.](https://image.slidesharecdn.com/inmemoryoptionv1-140928125539-phpapp01/85/Oracle-Database-In-Memory-38-320.jpg)


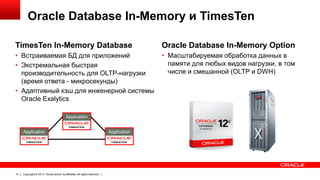

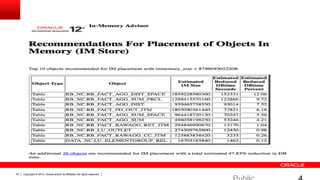


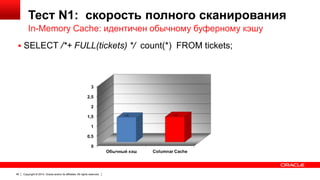
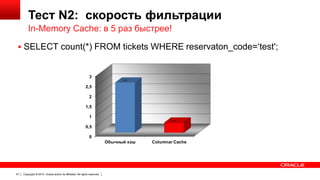
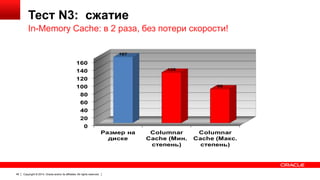
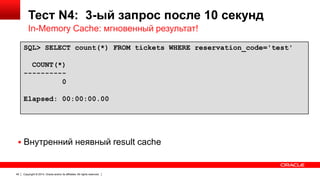






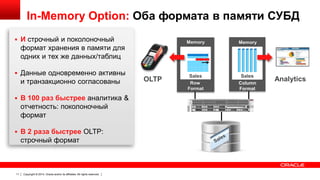
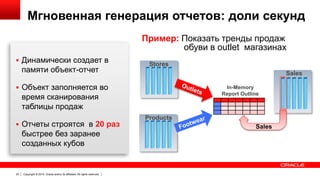
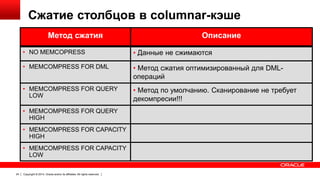
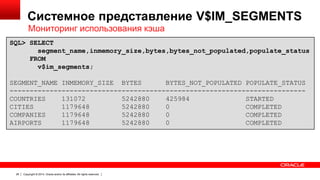
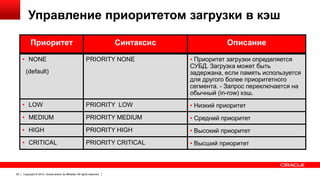
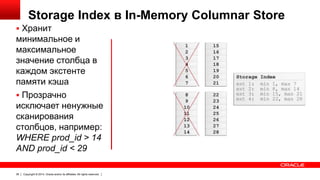
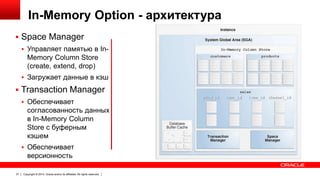
Документ описывает возможность использования памяти в Oracle Database для повышения производительности обработки данных. Он рассматривает технологии, оптимизации и способы кэширования, которые делают запросы в 100 раз быстрее для аналитики и в 2 раза быстрее для OLTP. В документе также представлены примеры использования различных методов сжатия и обработки данных в памяти.
































































