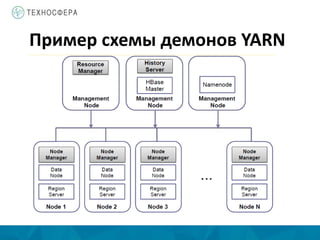
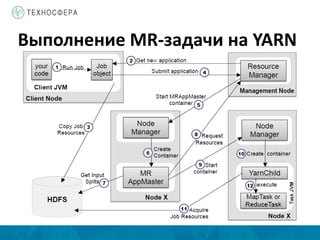
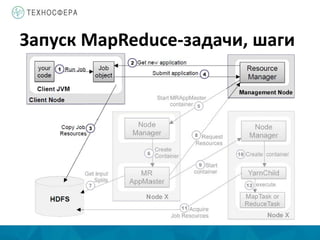
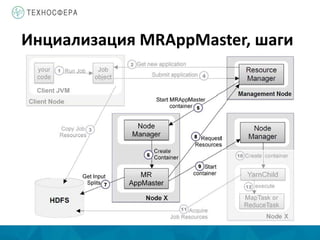
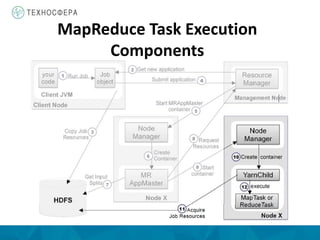
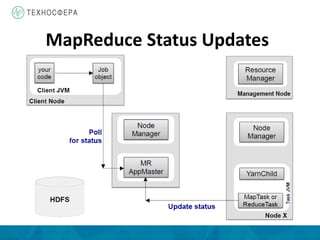
Документ описывает архитектуру и компоненты YARN (Yet Another Resource Negotiator) в контексте распределенной обработки данных с использованием Hadoop. Он охватывает процессы выполнения задач MapReduce, включая инициализацию, назначение задач и управление ресурсами, а также преимущества YARN по сравнению с устаревшей моделью MapReduce. Также представлены аспекты управления памятью и обработка ошибок в системе.