Downloaded 35 times







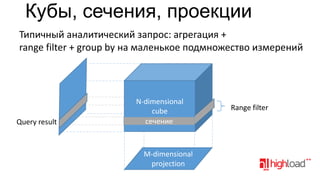














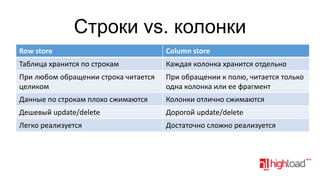











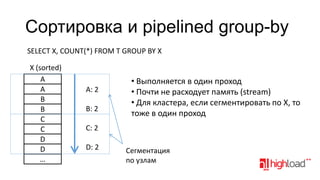
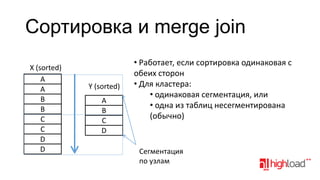

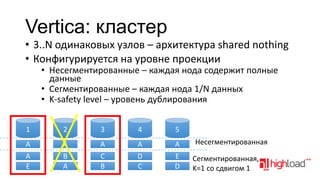
















Документ обсуждает распределенные системы хранения данных, таких как Vertica, в контексте аналитики больших данных, затрагивая функциональные требования, технические сложности и стратегии оптимизации производительности. Упоминаются различные подходы к моделированию и хранению данных, преимущества и недостатки распределенных систем, а также их стоимость и возможности. Также рассматриваются альтернативы, такие как MySQL с специализированными движками и NoSQL решения.



































































