Downloaded 16 times



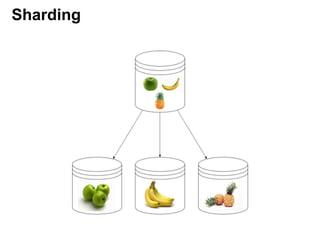
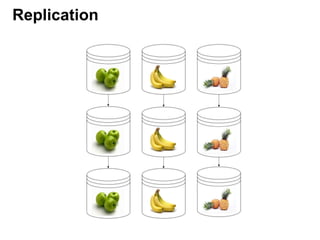
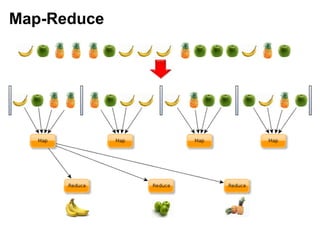


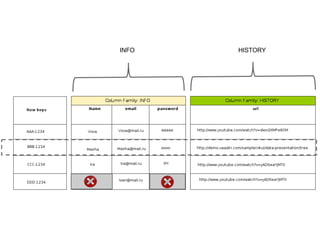
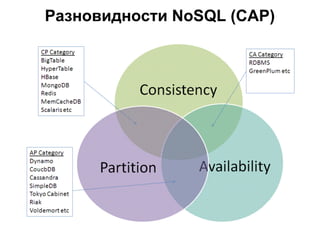
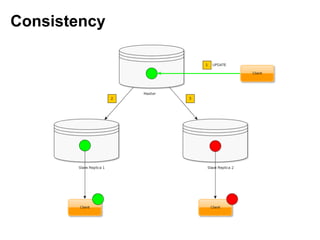
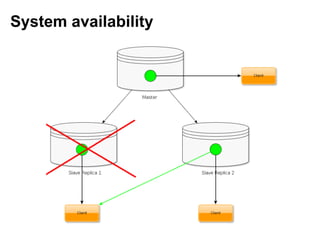
















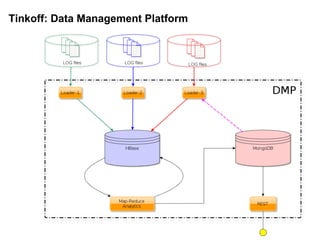

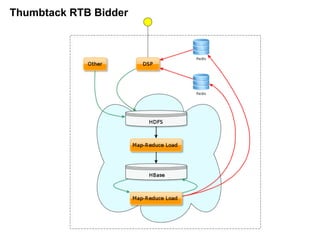



Документ описывает применение решений NoSQL в проектах, таких как Thumbtack и Tinkoff. Он охватывает различные типы NoSQL баз данных, их особенности, использование в проектах, а также сравнивает методы хранения и обработки данных. Основное внимание уделяется системам, таким как Redis, MongoDB, Cassandra и HBase, с акцентом на их преимущества и недостатки.































































