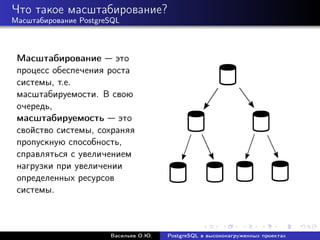
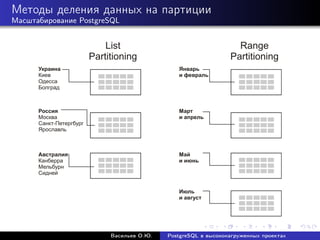
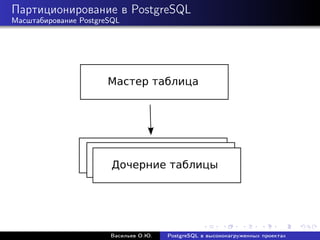
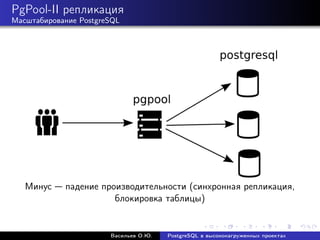
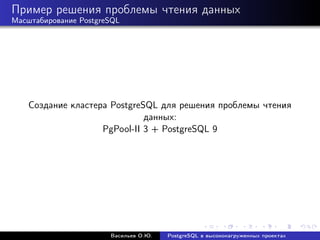
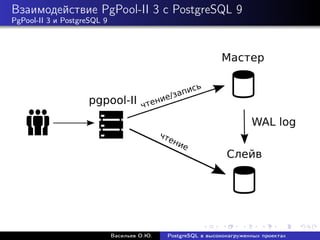
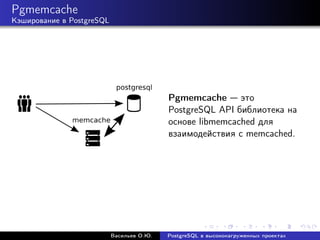
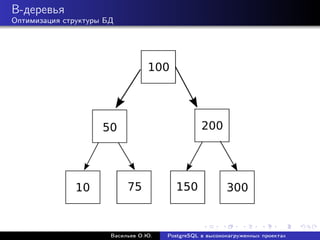
Документ рассматривает использование PostgreSQL в высоконагруженных проектах, акцентируя внимание на его надежности, масштабируемости и оптимизации производительности. Описываются методы настройки, такие как партиционирование, репликация и использование пулов соединений, а также проблемы, связанные с производительностью и масштабированием. Также представлены рекомендации по оптимизации SQL-запросов и стратегий кэширования для увеличения общей эффективности работы базы данных.





























![Анализирование SQL запросов
EXPLAIN [ANALYZE]
pgFouine — это анализатор
log-файлов для PostgreSQL
COPY vs INSERT на
больших объемах данных
Васильев О.Ю. PostgreSQL в высоконагруженных проектах](https://image.slidesharecdn.com/postgresql-101120114648-phpapp01/85/PostgreSQL-38-320.jpg)

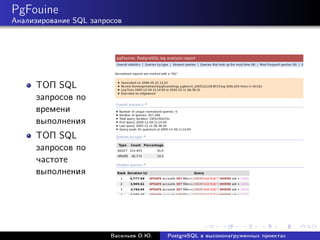


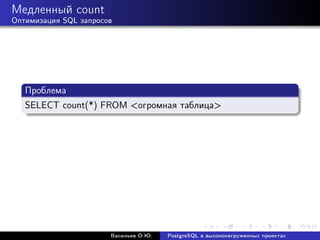
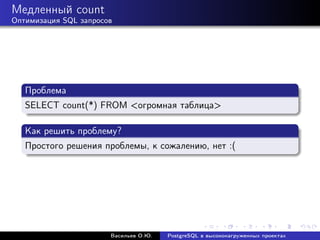
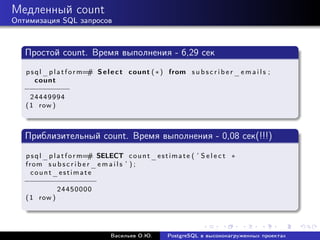
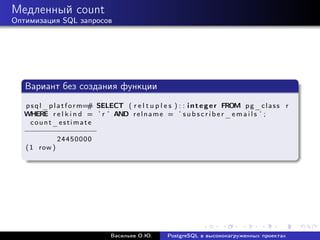
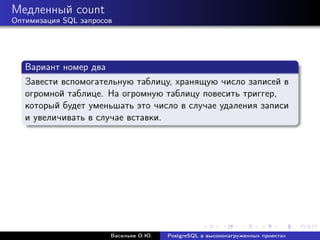
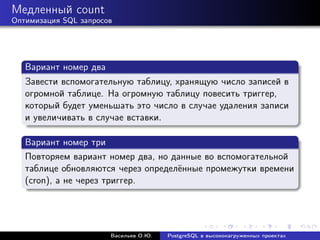
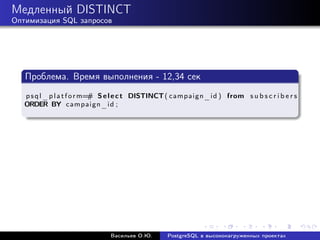
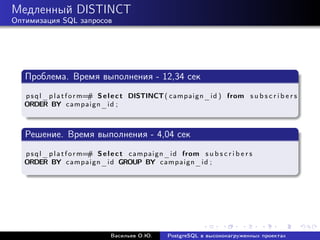
![Медленный count
Оптимизация SQL запросов
Решение номер один: приблизительное количество
CREATE FUNCTION count_estimate ( query t e x t )
RETURNS integer AS $$
DECLARE
r e c r e c o r d ;
rows integer ;
BEGIN
FOR r e c IN EXECUTE ’EXPLAIN ’ | | query LOOP
rows := substring ( r e c . "QUERY PLAN" FROM ’
rows = ( [ [ : d i g i t : ] ] + ) ’ ) ;
EXIT WHEN rows IS NOT NULL;
END LOOP;
RETURN rows ;
END;
$$ LANGUAGE p l p g s q l VOLATILE STRICT ;
Васильев О.Ю. PostgreSQL в высоконагруженных проектах](https://image.slidesharecdn.com/postgresql-101120114648-phpapp01/85/PostgreSQL-46-320.jpg)