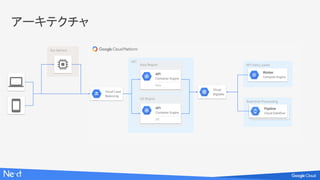
API
● 分析結果を APIとして各サービスに提供
○ 機械学習による予測の結果
○ レコメンデーション
● 基本的に Key に対する Value を返せば十分
○ リクエストのたびに予測はしない
15.
API
US Region
Our Service
AsiaRegion
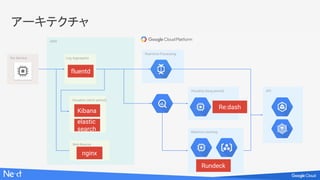
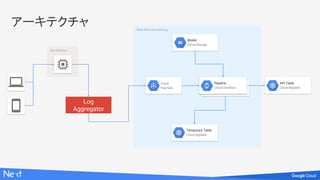
アーキテクチャ
Cloud Load
Balancing
API
Container Engine
Asia
API
Container Engine
US
Cloud
Bigtable
API Data Loader
Worker
Compute Engine
Real-time Processing
Pipeline
Cloud Dataflow
16.
API Data Loader
●API で提供するデータを Bigtable へ反映
○ S3 へのファイル配置イベントを SQS へ流す
○ Worker が Receive して Bigtable へ書き込む
17.
API Data Loaderの利用ケース
● 他チームの API 利用者
● 各種バッチ
● 最大数千万行の Bigtable への Put オペレーション
18.
API サーバ
● Scalatraベース
● GET のみ
○ リクエストパスに Key を含める
○ Key で Bigtable を引き Value を JSON で返す
Flatten 後の副入力あり ParDo変換
● エラーが発生してパイプラインが実行されない
○ GetData failed: status: APPLICATION_ERROR(3):
Computation F64does not have state family S1 for
value read



















































![[Cloud OnAir] お客様事例紹介 -リクルートライフスタイルにおける デジタルトランスフォーメーションとクラウド活用- 2018年7月12日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/444444444444-180712090757-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevmiyazawa-191031085336-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]FOTS: Fast Oriented Text Spotting with a Unified Network](https://cdn.slidesharecdn.com/ss_thumbnails/20181012yokota-181012004624-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)





























































