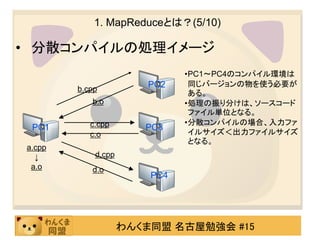
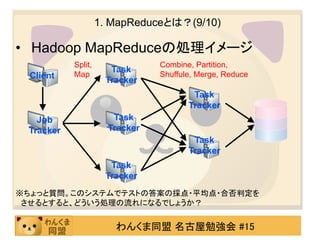
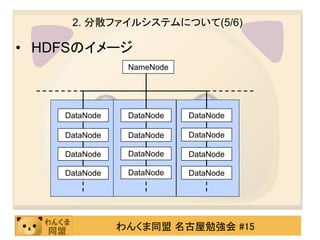
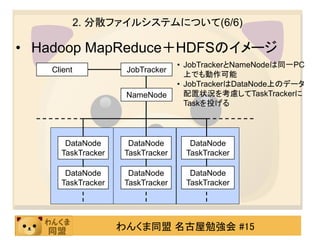
1. MapReduceとは?(2/10)
Hadoopで実装されいるGoogleの技術
• TheGoogle File System (2003年)
http://labs.google.com/papers/gfs.html
• MapReduce: Simplified Data Processing on Larg
e Clusters (2004年)
http://labs.google.com/papers/mapreduce.html
• BigTable: A Distributed Storage System for Struct
ured Data (2006年)
http://labs.google.com/papers/bigtable.html
わんくま同盟 名古屋勉強会 #15
7.
1. MapReduceとは?(3/10)
• Googleでも使わているMapReduceってすげぇ!
•ん?でももう使われてないよw
HighScalability - Google's Colossus Makes Searc
h Real-time by Dumping MapReduce
http://mcaf.ee/d6e97
(参考日本語訳)
AgileCat - Google Instant では、リアルタイム検索
のために MapReduce を排除!
http://wp.me/pwo1E-1Kf
わんくま同盟 名古屋勉強会 #15
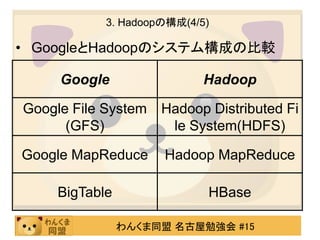
3. Hadoopの構成(4/5)
• GoogleとHadoopのシステム構成の比較
Google Hadoop
Google File System Hadoop Distributed Fi
(GFS) le System(HDFS)
Google MapReduce Hadoop MapReduce
BigTable HBase
わんくま同盟 名古屋勉強会 #15