Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
MapR Technologies Japan
3,070 views
MapR M7 技術概要
MapR Technologies CTO の M.C. Srivas による、MapR M7 技術概要。
Technology
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 48 times
1
/ 40
2
/ 40
3
/ 40
4
/ 40
5
/ 40
6
/ 40
7
/ 40
8
/ 40
9
/ 40
10
/ 40
11
/ 40
12
/ 40
13
/ 40
14
/ 40
15
/ 40
16
/ 40
17
/ 40
18
/ 40
19
/ 40
20
/ 40
21
/ 40
22
/ 40
23
/ 40
24
/ 40
25
/ 40
26
/ 40
27
/ 40
28
/ 40
29
/ 40
30
/ 40
31
/ 40
32
/ 40
33
/ 40
34
/ 40
35
/ 40
36
/ 40
37
/ 40
38
/ 40
39
/ 40
40
/ 40
More Related Content
PDF
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
by
MapR Technologies Japan
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PPTX
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
PDF
Apache Drill を利用した実データの分析
by
MapR Technologies Japan
PDF
Hadoop入門
by
Preferred Networks
PDF
ストリーミングアーキテクチャ: State から Flow へ - 2016/02/08 Hadoop / Spark Conference Japan ...
by
MapR Technologies Japan
PDF
MapR 5.2: MapR コンバージド・コミュニティ・エディションを使いこなす
by
MapR Technologies Japan
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
by
MapR Technologies Japan
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
Apache Drill を利用した実データの分析
by
MapR Technologies Japan
Hadoop入門
by
Preferred Networks
ストリーミングアーキテクチャ: State から Flow へ - 2016/02/08 Hadoop / Spark Conference Japan ...
by
MapR Technologies Japan
MapR 5.2: MapR コンバージド・コミュニティ・エディションを使いこなす
by
MapR Technologies Japan
What's hot
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PPTX
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PDF
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
PDF
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
Apache Drill でオープンデータを分析してみる - db tech showcase Sapporo 2015 2015/09/11
by
MapR Technologies Japan
PPTX
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
by
LINE Corporation
PDF
MapR と Vertica エンジニアが語る、なぜその組み合わせが最高なのか? - db tech showcase 大阪 2014 2014/06/19
by
MapR Technologies Japan
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PDF
Hadoop最新情報 - YARN, Omni, Drill, Impala, Shark, Vertica - MapR CTO Meetup 2014...
by
MapR Technologies Japan
PDF
Hadoopによる大規模分散データ処理
by
Yoji Kiyota
PDF
HBase と Drill - 緩い型付けの SQL がいかに NoSQL に適しているか
by
MapR Technologies Japan
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
Hadoop概要説明
by
Satoshi Noto
PDF
CDH4.1オーバービュー
by
Cloudera Japan
PDF
Hadoopを用いた大規模ログ解析
by
shuichi iida
PDF
Hadoop / MapReduce とは
by
Takeshi Matsuoka
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Apache Drill でオープンデータを分析してみる - db tech showcase Sapporo 2015 2015/09/11
by
MapR Technologies Japan
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
by
LINE Corporation
MapR と Vertica エンジニアが語る、なぜその組み合わせが最高なのか? - db tech showcase 大阪 2014 2014/06/19
by
MapR Technologies Japan
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
Hadoop最新情報 - YARN, Omni, Drill, Impala, Shark, Vertica - MapR CTO Meetup 2014...
by
MapR Technologies Japan
Hadoopによる大規模分散データ処理
by
Yoji Kiyota
HBase と Drill - 緩い型付けの SQL がいかに NoSQL に適しているか
by
MapR Technologies Japan
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
Osc2012 spring HBase Report
by
Seiichiro Ishida
Hadoop概要説明
by
Satoshi Noto
CDH4.1オーバービュー
by
Cloudera Japan
Hadoopを用いた大規模ログ解析
by
shuichi iida
Hadoop / MapReduce とは
by
Takeshi Matsuoka
Viewers also liked
PDF
実践機械学習 — MahoutとSolrを活用したレコメンデーションにおけるイノベーション - 2014/07/08 Hadoop Conference ...
by
MapR Technologies Japan
PDF
Apache Drill で JSON 形式の オープンデータを分析してみる - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
PDF
Drill超簡単チューニング
by
MapR Technologies Japan
PDF
スケールアウト・インメモリ分析の標準フォーマットを目指す Apache Arrow と Value Vectors - Tokyo Apache Dril...
by
MapR Technologies Japan
PPTX
MapR Streams and MapR Converged Data Platform
by
MapR Technologies
PDF
20170225_Sample size determination
by
Takanori Hiroe
PPTX
20150827_simplesize
by
Takanori Hiroe
PPTX
Apache Drill で日本語を扱ってみよう + オープンデータ解析
by
MapR Technologies Japan
PPTX
Inside MapR's M7
by
Ted Dunning
PDF
Deep Learning at Scale
by
Mateusz Dymczyk
PPTX
HBase New Features
by
rxu
PPTX
MapR 5.2: Getting More Value from the MapR Converged Community Edition
by
MapR Technologies
PDF
MapR & Skytree:
by
MapR Technologies
PDF
Apache Drill でたしなむ セルフサービスデータ探索 - 2014/11/06 Cloudera World Tokyo 2014 LTセッション
by
MapR Technologies Japan
PDF
ビジネスへの本格活用が始まったHadoopの今 ~MapRが選ばれる理由~ - ビッグデータEXPO東京 2014/02/26
by
MapR Technologies Japan
PDF
Big Data Hadoop Briefing Hosted by Cisco, WWT and MapR: MapR Overview Present...
by
ervogler
PDF
MapR Streams & MapR コンバージド・データ・プラットフォーム
by
MapR Technologies Japan
PDF
20150321 医学:医療者教育研究ネットワーク@九州大学
by
Takanori Hiroe
PDF
JSME_47th_Nigata
by
Takanori Hiroe
PDF
20151128_SMeNG_態度は変えられるのか
by
Takanori Hiroe
実践機械学習 — MahoutとSolrを活用したレコメンデーションにおけるイノベーション - 2014/07/08 Hadoop Conference ...
by
MapR Technologies Japan
Apache Drill で JSON 形式の オープンデータを分析してみる - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
Drill超簡単チューニング
by
MapR Technologies Japan
スケールアウト・インメモリ分析の標準フォーマットを目指す Apache Arrow と Value Vectors - Tokyo Apache Dril...
by
MapR Technologies Japan
MapR Streams and MapR Converged Data Platform
by
MapR Technologies
20170225_Sample size determination
by
Takanori Hiroe
20150827_simplesize
by
Takanori Hiroe
Apache Drill で日本語を扱ってみよう + オープンデータ解析
by
MapR Technologies Japan
Inside MapR's M7
by
Ted Dunning
Deep Learning at Scale
by
Mateusz Dymczyk
HBase New Features
by
rxu
MapR 5.2: Getting More Value from the MapR Converged Community Edition
by
MapR Technologies
MapR & Skytree:
by
MapR Technologies
Apache Drill でたしなむ セルフサービスデータ探索 - 2014/11/06 Cloudera World Tokyo 2014 LTセッション
by
MapR Technologies Japan
ビジネスへの本格活用が始まったHadoopの今 ~MapRが選ばれる理由~ - ビッグデータEXPO東京 2014/02/26
by
MapR Technologies Japan
Big Data Hadoop Briefing Hosted by Cisco, WWT and MapR: MapR Overview Present...
by
ervogler
MapR Streams & MapR コンバージド・データ・プラットフォーム
by
MapR Technologies Japan
20150321 医学:医療者教育研究ネットワーク@九州大学
by
Takanori Hiroe
JSME_47th_Nigata
by
Takanori Hiroe
20151128_SMeNG_態度は変えられるのか
by
Takanori Hiroe
Similar to MapR M7 技術概要
PDF
事例から見るNoSQLの使い方 - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
PDF
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
PPT
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
PDF
第25回 Hadoopソースコードリーディング 「HBase 最新情報」
by
Toshihiro Suzuki
PDF
AWS Black Belt Online Seminar Amazon Redshift
by
Amazon Web Services Japan
PDF
B-Treeのアーキテクチャ解説 (第49回PostgreSQLアンカンファレンス@東京 発表資料)
by
NTT DATA Technology & Innovation
PDF
[B27] エンタープライズ NoSQL/HBase プラットフォーム – MapR M7 エディション by Masataka Oka
by
Insight Technology, Inc.
PDF
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
PDF
HBaseCon 2012 参加レポート
by
NTT DATA OSS Professional Services
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
PPTX
Hadoop summit 2012 report
by
Sho Shimauchi
PDF
20分でわかるHBase
by
Sho Shimauchi
PDF
20110517 okuyama ソーシャルメディアが育てた技術勉強会
by
Takahiro Iwase
PDF
ICDE 2015 Study (R24-4, R27-3)
by
Masafumi Oyamada
PDF
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
PDF
InfoTalk springbreak_2012
by
Hiroshi Bunya
PDF
20130626 kawasaki.rb NKT77
by
nkt77
PDF
Info talk #36
by
Hiroshi Bunya
PDF
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
PPSX
実動するIot&hadoopから学ぶ会_資料
by
FwardNetwork
事例から見るNoSQLの使い方 - db tech showcase Tokyo 2015 2015/06/11
by
MapR Technologies Japan
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
第25回 Hadoopソースコードリーディング 「HBase 最新情報」
by
Toshihiro Suzuki
AWS Black Belt Online Seminar Amazon Redshift
by
Amazon Web Services Japan
B-Treeのアーキテクチャ解説 (第49回PostgreSQLアンカンファレンス@東京 発表資料)
by
NTT DATA Technology & Innovation
[B27] エンタープライズ NoSQL/HBase プラットフォーム – MapR M7 エディション by Masataka Oka
by
Insight Technology, Inc.
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
HBaseCon 2012 参加レポート
by
NTT DATA OSS Professional Services
Facebookのリアルタイム Big Data 処理
by
maruyama097
Hadoop summit 2012 report
by
Sho Shimauchi
20分でわかるHBase
by
Sho Shimauchi
20110517 okuyama ソーシャルメディアが育てた技術勉強会
by
Takahiro Iwase
ICDE 2015 Study (R24-4, R27-3)
by
Masafumi Oyamada
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
InfoTalk springbreak_2012
by
Hiroshi Bunya
20130626 kawasaki.rb NKT77
by
nkt77
Info talk #36
by
Hiroshi Bunya
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
実動するIot&hadoopから学ぶ会_資料
by
FwardNetwork
More from MapR Technologies Japan
PDF
時系列の世界の時系列データ
by
MapR Technologies Japan
PDF
Apache Drill: Rethinking SQL for Big data – Don’t Compromise on Flexibility o...
by
MapR Technologies Japan
PDF
Hadoop によるゲノム解読
by
MapR Technologies Japan
PDF
Drilling into Data with Apache Drill - Tokyo Apache Drill Meetup 2015/11/12
by
MapR Technologies Japan
PDF
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
PDF
Fast Data を扱うためのデザインパターン
by
MapR Technologies Japan
PDF
逆らえない大きな流れ: 次世代のエンタープライズアーキテクチャ
by
MapR Technologies Japan
PDF
マップアールが考える企業システムにおける分析プラットフォームの進化 - 2014/06/27 Data Scientist Summit 2014
by
MapR Technologies Japan
PDF
エンタープライズ NoSQL/HBase プラットフォーム – MapR M7 エディション - db tech showcase 大阪 2014 201...
by
MapR Technologies Japan
時系列の世界の時系列データ
by
MapR Technologies Japan
Apache Drill: Rethinking SQL for Big data – Don’t Compromise on Flexibility o...
by
MapR Technologies Japan
Hadoop によるゲノム解読
by
MapR Technologies Japan
Drilling into Data with Apache Drill - Tokyo Apache Drill Meetup 2015/11/12
by
MapR Technologies Japan
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
Fast Data を扱うためのデザインパターン
by
MapR Technologies Japan
逆らえない大きな流れ: 次世代のエンタープライズアーキテクチャ
by
MapR Technologies Japan
マップアールが考える企業システムにおける分析プラットフォームの進化 - 2014/06/27 Data Scientist Summit 2014
by
MapR Technologies Japan
エンタープライズ NoSQL/HBase プラットフォーム – MapR M7 エディション - db tech showcase 大阪 2014 201...
by
MapR Technologies Japan
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
MapR M7 技術概要
1.
1 ©MapR Technologies
MapR M7 技術概要 M. C. Srivas CTO/Founder, MapR
2.
2 ©MapR Technologies
MapR: データセンターの完全自動化へ • 自動フェールオーバー • 自動再レプリケーション • ハードウェアおよびソフトウェア障 害からの自律回復 • 負荷分散 • ローリングアップグレード • ジョブやデータの損失なし • 99.999% の稼働時間 高信頼処理 高信頼ストレージ • スナップショットおよびミラーによる 事業継続 • ポイントインタイムの復旧 • エンドツーエンドチェックサム • 強い一貫性 • ビルトイン圧縮 • RTO ポリシーに基づく拠点間ミラー
3.
3 ©MapR Technologies
MapR の MapReduce 性能 (速い) TeraSort 記録 1 TB を 54 秒 1003 ノード MinuteSort 記録 1.5 TB を 59 秒 2103 ノード
4.
4 ©MapR Technologies
MapR の MapReduce 性能 (より速い) TeraSort 記録 1 TB を 54 秒 1003 ノード MinuteSort 記録 1.5 TB を 59 秒 2103 ノード 1.65 300
5.
5 ©MapR Technologies
Dynamo DB ZopeDB Shoal CloudKit Vertex DB FlockD B NoSQL
6.
6 ©MapR Technologies
HBase テーブルアーキテクチャ § テーブルは Key 範囲で分割される (Region) § Region は各ノードが管理 (RegionServer) § カラムはアクセスグループに分割される (カラムファミリー) CF1 CF2 CF3 CF4 CF5 R1 R2 R3 R4
7.
7 ©MapR Technologies
HBase アーキテクチャが優れている点 § 強い一貫性モデル – 書き込み完了後、すべての読み出しは同じ値になることを保証 – 他のNoSQLの「Eventually Consistent」は、実際にはときどき 「Eventually Inconsistent」に § 効率の良いスキャン – ブロードキャストを行わない – Ring ベースの NoSQL データベース (例: Cassandra, Riak) はスキャン が大変 § 自動的にスケール – Regionが大きくなると自動で分割される – データ分散や格納スペースの管理に HDFS を利用 § Hadoop との連携 – HBase のデータを MapReduce で直接処理できる
8.
8 ©MapR Technologies
MapR M7 非構造化データおよび構造化データ のための統合システム
9.
9 ©MapR Technologies
MapR M7 テーブル § Apache HBase とバイナリ互換 – M7 テーブルへのアクセスには再コンパイル不要 – CLASSPATH を設定するだけ – HBase コマンドラインインターフェースを含む § パス名の指定で M7 テーブルにアクセス – openTable( “hello”) … HBase を使用 – openTable( “/hello”) … M7 を使用 – openTable( “/user/srivas/hello”) … M7 を使用
10.
10 ©MapR Technologies
バイナリ互換 § HBase アプリケーションは M7 でも「変更なしで」動作 – 再コンパイル不要、CLASSPATH を設定するだけ § M7 と HBase を単一クラスタで同時に稼働できる – 例: 移行期間中 – 同じプログラムで M7 テーブルと HBase テーブルの両方にアクセス可 能 § 標準の Apache HBase CopyTable ツールを使用して、HBase か ら M7 にテーブルをコピー(逆も可) % hbase org.apache.hadoop.hbase.mapreduce.CopyTable -‐-‐new.name=/user/srivas/mytable oldtable
11.
11 ©MapR Technologies
特徴 § テーブル数の制限なし – HBase は一般的に 10〜20 程度 (最大でも 100) § コンパクションなし § 即時起動 – 復旧時間ゼロ § 8倍の挿入/更新性能 § 10倍のランダムスキャン性能 § Flash の活用で10倍の性能 -‐ Flash の特別サポート
12.
12 ©MapR Technologies
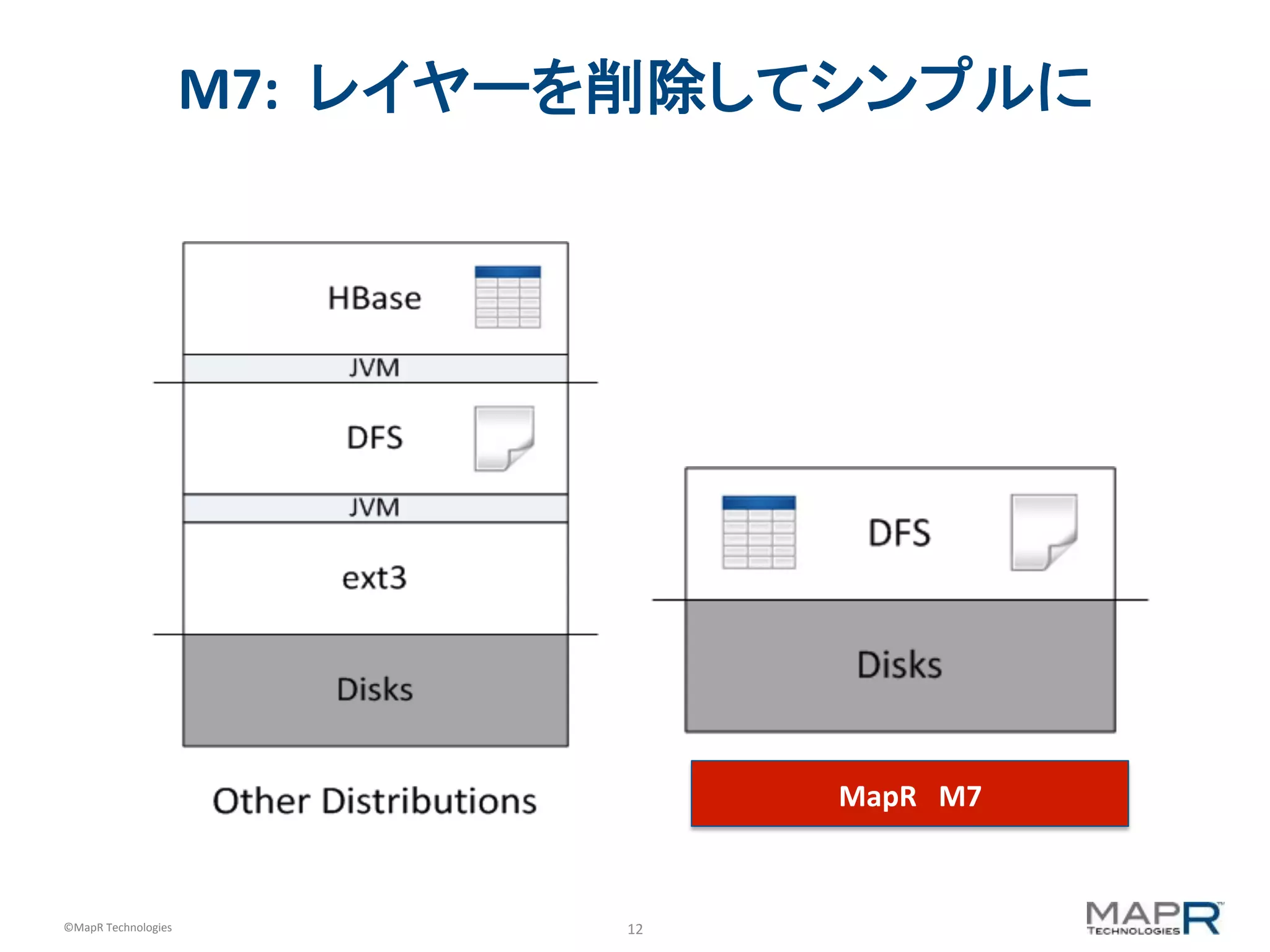
M7: レイヤーを削除してシンプルに MapR M7
13.
13 ©MapR Technologies
MapR クラスタ内の M7 テーブル § M7 テーブルはストレージに統合されている – いつでも、どのノードでも利用可能 – 別のプロセスを起動・監視する必要なし – 管理不要 – チューニングパラメータなし … そのまま動く § M7 テーブルは 「期待通りに」動く – 一つ目のコピーは書き込みクライアント自身の場所に – スナップショットやミラーを適用可能 – クォータ、レプリケーション数、データ配置の指定が可能
14.
14 ©MapR Technologies
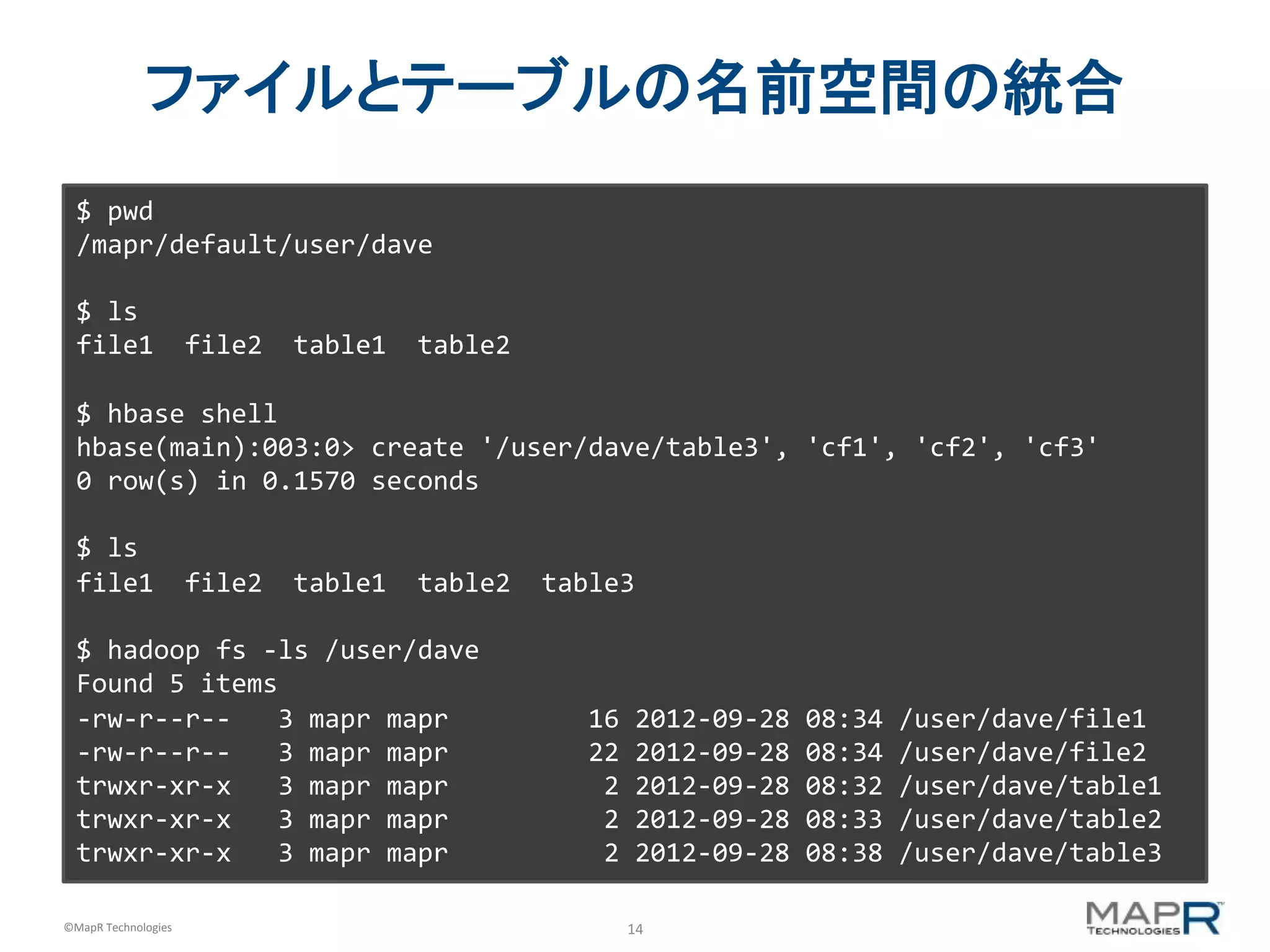
ファイルとテーブルの名前空間の統合 $ pwd /mapr/default/user/dave $ ls file1 file2 table1 table2 $ hbase shell hbase(main):003:0> create '/user/dave/table3', 'cf1', 'cf2', 'cf3' 0 row(s) in 0.1570 seconds $ ls file1 file2 table1 table2 table3 $ hadoop fs -‐ls /user/dave Found 5 items -‐rw-‐r-‐-‐r-‐-‐ 3 mapr mapr 16 2012-‐09-‐28 08:34 /user/dave/file1 -‐rw-‐r-‐-‐r-‐-‐ 3 mapr mapr 22 2012-‐09-‐28 08:34 /user/dave/file2 trwxr-‐xr-‐x 3 mapr mapr 2 2012-‐09-‐28 08:32 /user/dave/table1 trwxr-‐xr-‐x 3 mapr mapr 2 2012-‐09-‐28 08:33 /user/dave/table2 trwxr-‐xr-‐x 3 mapr mapr 2 2012-‐09-‐28 08:38 /user/dave/table3
15.
15 ©MapR Technologies
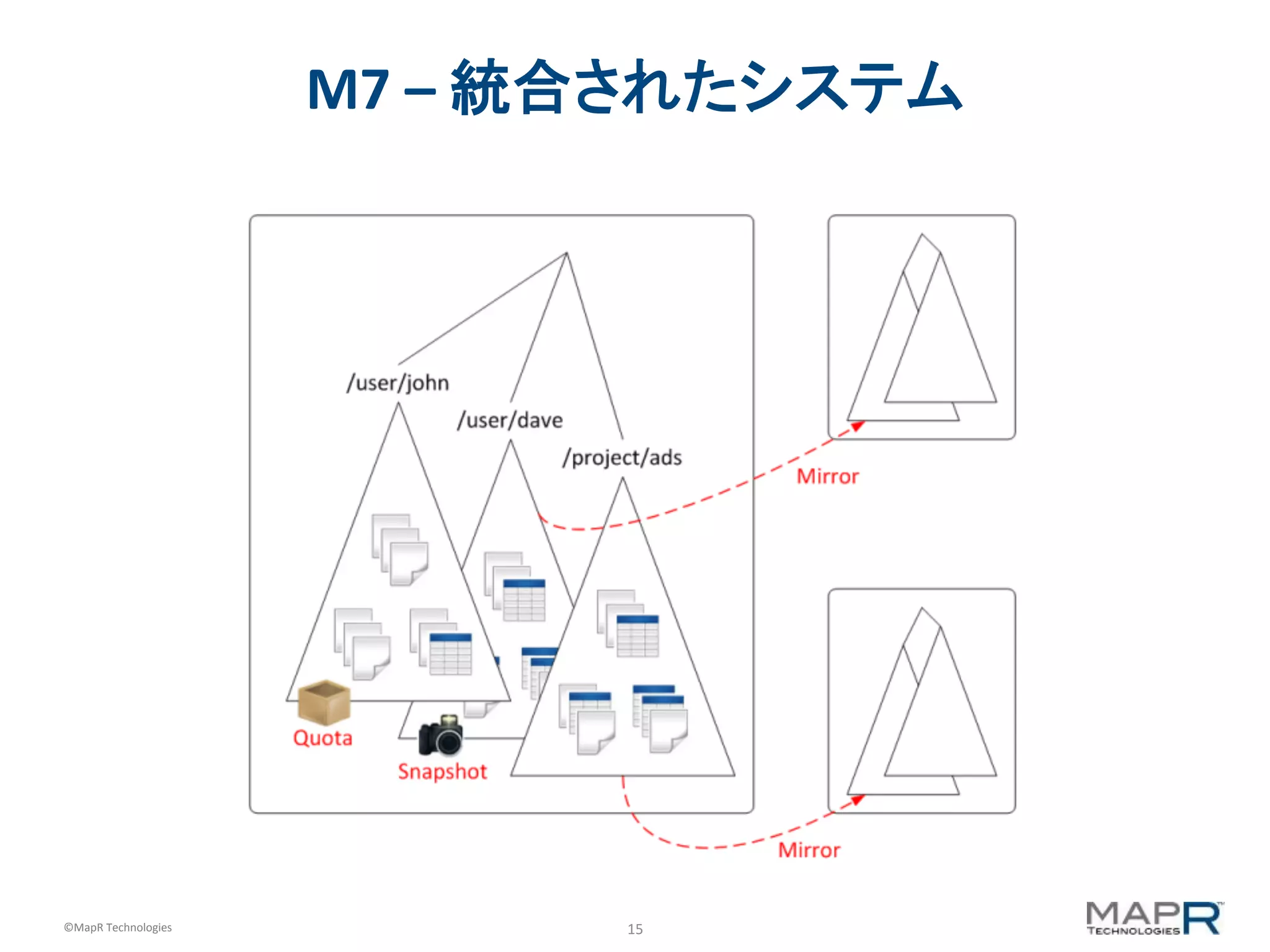
M7 – 統合されたシステム
16.
16 ©MapR Technologies
エンドユーザーから見たテーブル § ユーザーは自分のテーブルを作成・管理できる – テーブル数の制限がないから – 一つ目のコピーは自分の場所に § テーブルはどのディレクトリにも作成できる – テーブルはボリュームの管理下になり、ユーザークォータの計算 対象になる § 管理者の介在は不要 – 処理は即時に行われ、サーバの停止・再開は不要 § 自動データ保護とディザスタリカバリ – ユーザーは自分のスナップショット/ミラーから復旧可能
17.
17 ©MapR Technologies
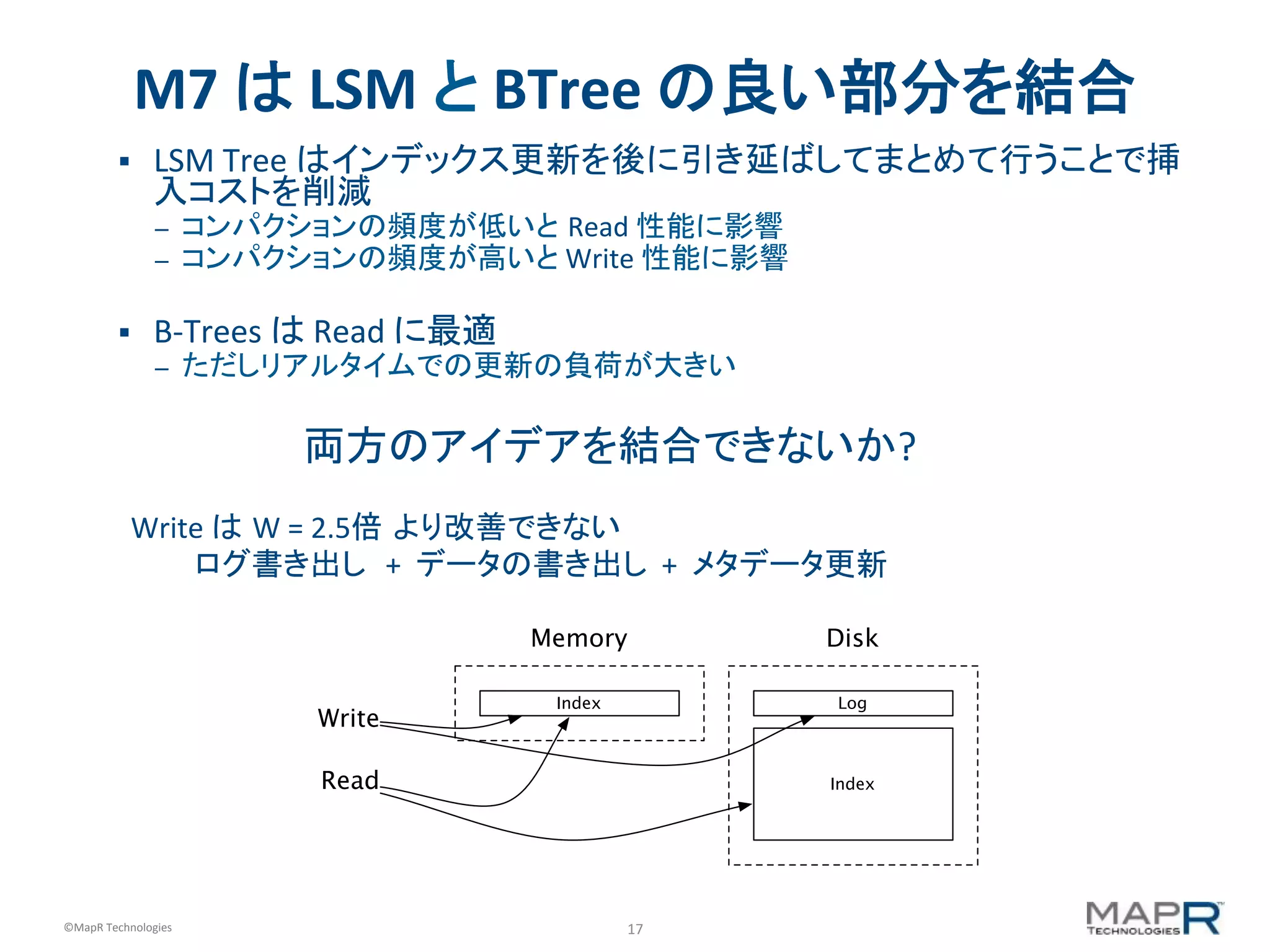
M7 は LSM と BTree の良い部分を結合 § LSM Tree はインデックス更新を後に引き延ばしてまとめて行うことで挿 入コストを削減 – コンパクションの頻度が低いと Read 性能に影響 – コンパクションの頻度が高いと Write 性能に影響 § B-‐Trees は Read に最適 – ただしリアルタイムでの更新の負荷が大きい Index Log Index Memory Disk Write Read 両方のアイデアを結合できないか? Write は W = 2.5倍 より改善できない ログ書き出し + データの書き出し + メタデータ更新
18.
18 ©MapR Technologies
MapR M7 § 改良 BTree – リーフは可変サイズ (8KB〜8MB もしくはそれ以上) – 長期間アンバランスである事を許容 • 挿入の繰り返しにより最終的にバランスが取れる • 内部 BTree ノードに対する更新を自動的に調整 – M7 はデータが格納されるべき「おおよその」場所に挿入される § Read – BTree 構造を利用して「近くまで」非常に高速に到達 • 非常に高いブランチングとKey プリフィックス圧縮 – 別の低いレベルのインデックスを利用して正確な場所を確定 • Get には「直接更新される」Bloom フィルタ, Scan にはRange Map § オーバーヘッド – 1KB レコードの Read では、logN 回のシークで約 32KB のディスクか らの転送が行われる
19.
19 ©MapR Technologies
M7 Apache HBase, Level-‐DB, BTree の比較分析
20.
20 ©MapR Technologies
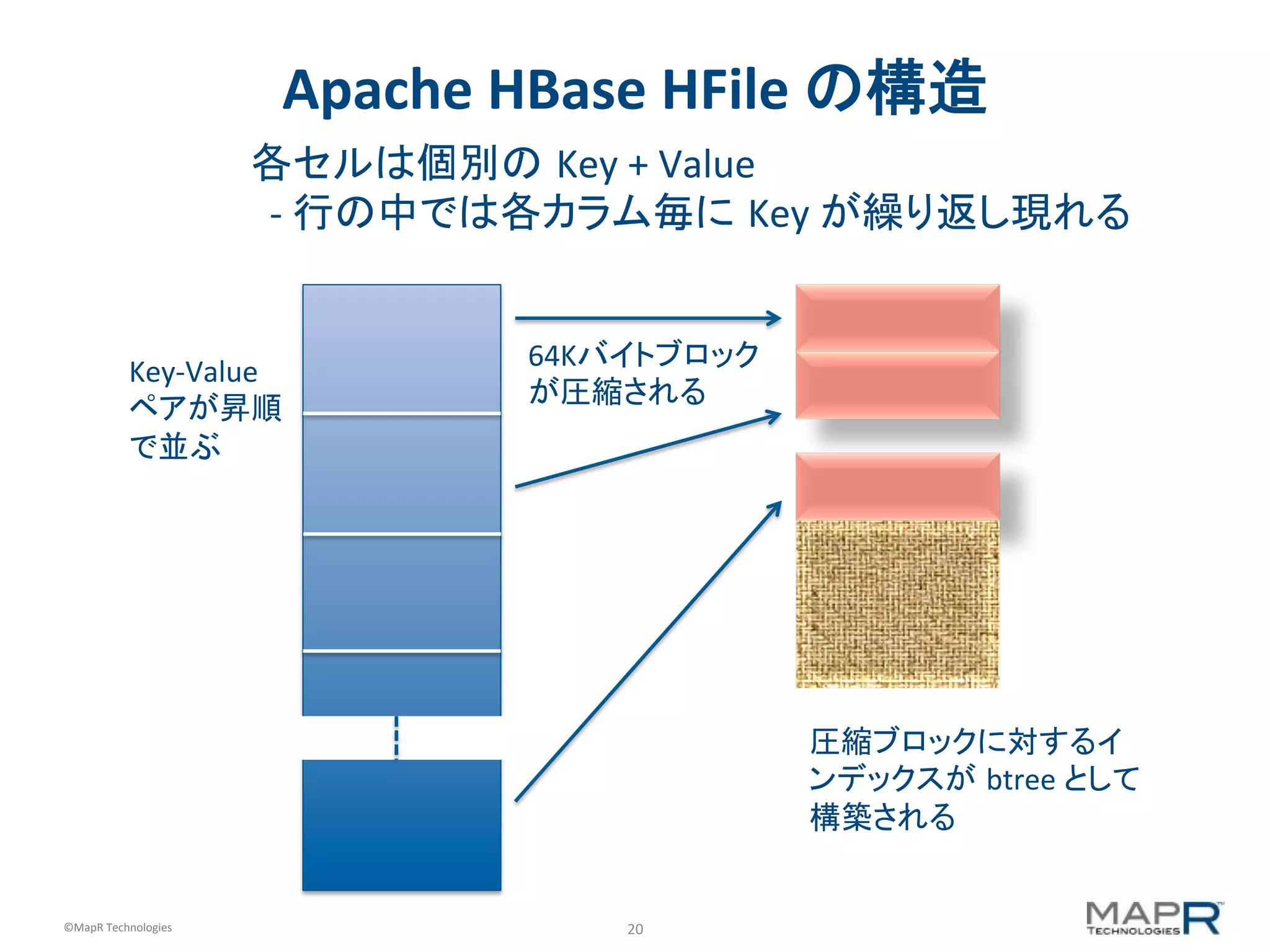
Apache HBase HFile の構造 64Kバイトブロック が圧縮される 圧縮ブロックに対するイ ンデックスが btree として 構築される Key-‐Value ペアが昇順 で並ぶ 各セルは個別の Key + Value -‐ 行の中では各カラム毎に Key が繰り返し現れる
21.
21 ©MapR Technologies
HBase Region オペレーション § 典型的な Region サイズは数 GB、ときどき 10GB〜20GB § RS はフルになるまでデータをメモリに保持し、新しい HFile に書き出す – HFileの階層で構成されるデータベースの論理ビュー (新しいものが一番上) この Region が格納する Key の範囲 新しい 古い
22.
22 ©MapR Technologies
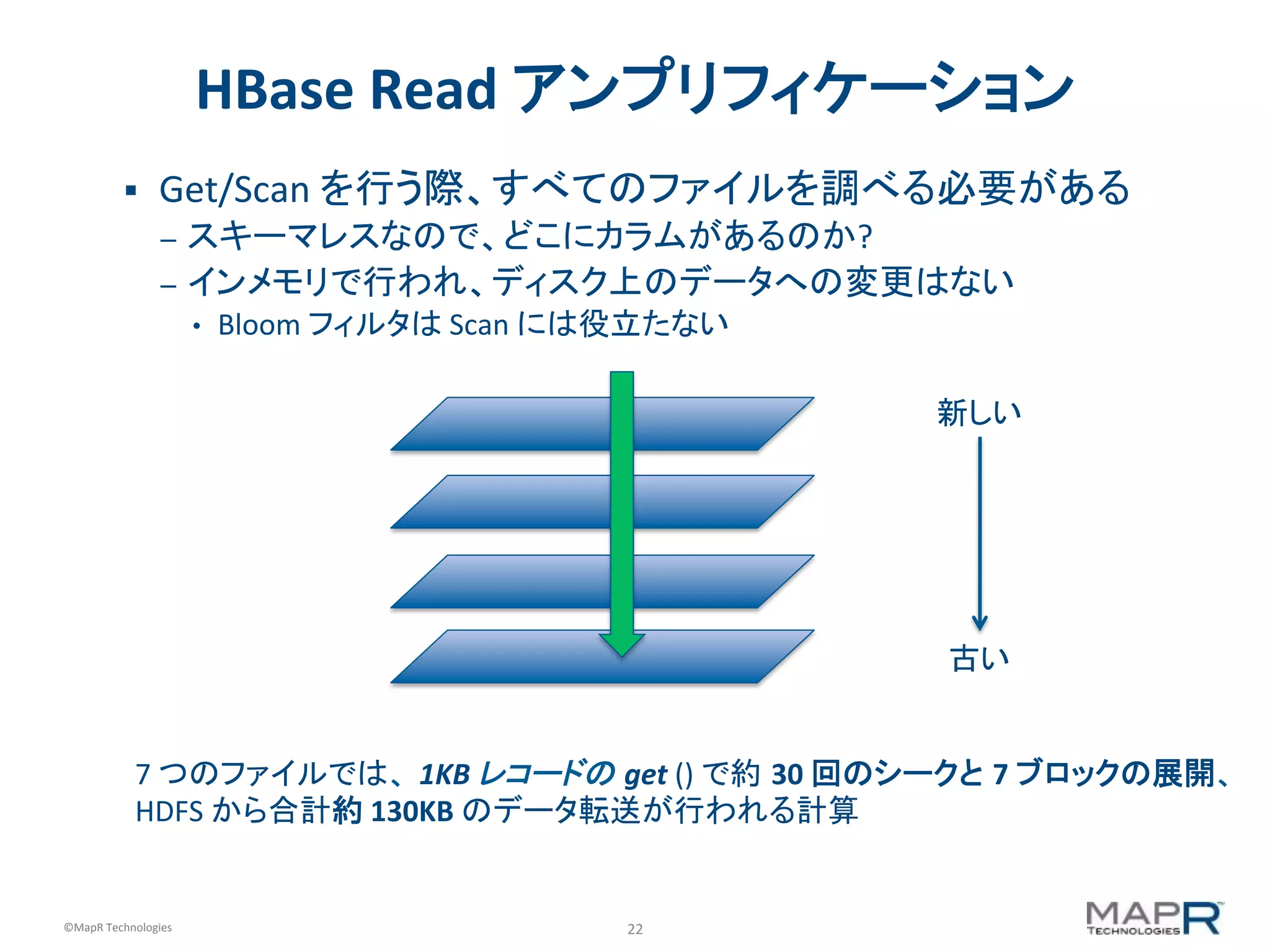
HBase Read アンプリフィケーション § Get/Scan を行う際、すべてのファイルを調べる必要がある – スキーマレスなので、どこにカラムがあるのか? – インメモリで行われ、ディスク上のデータへの変更はない • Bloom フィルタは Scan には役立たない 新しい 古い 7 つのファイルでは、 1KB レコードの get () で約 30 回のシークと 7 ブロックの展開、 HDFS から合計約 130KB のデータ転送が行われる計算
23.
23 ©MapR Technologies
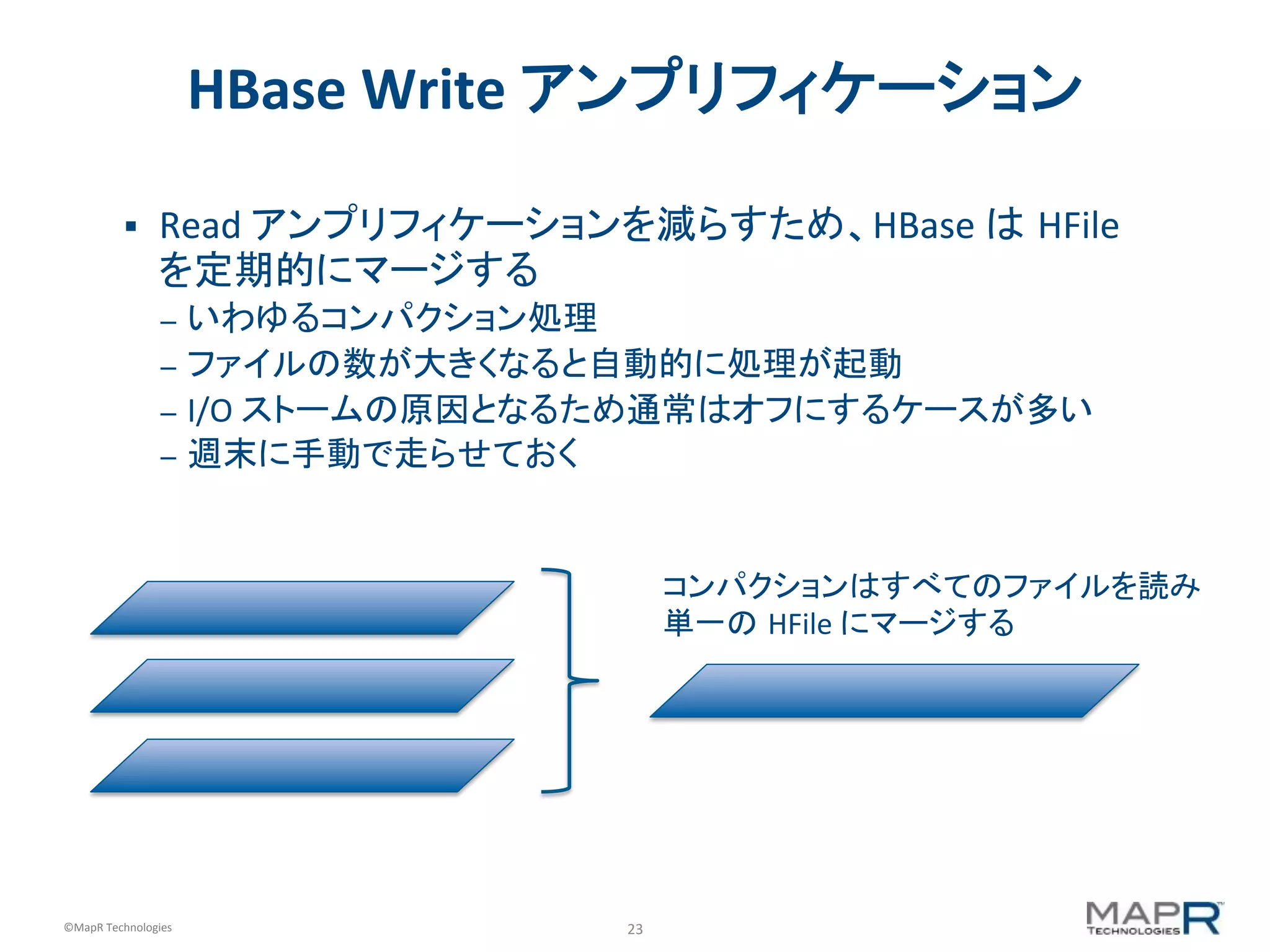
HBase Write アンプリフィケーション § Read アンプリフィケーションを減らすため、HBase は HFile を定期的にマージする – いわゆるコンパクション処理 – ファイルの数が大きくなると自動的に処理が起動 – I/O ストームの原因となるため通常はオフにするケースが多い – 週末に手動で走らせておく コンパクションはすべてのファイルを読み 単一の HFile にマージする
24.
24 ©MapR Technologies
HBase コンパクションの分析 § Region あたり 10GB、1日で10%を更新、1週間で10%増加、を 仮定 – 1GB の Write – 7日後、1GB のファイルが 7 つと 10GB のファイルが 1 つ § コンパクション – Read 合計: 17GB (= 7 x 1GB + 1 x 10GB) – Write 合計: 25GB (= 7GB WAL + 7GB 書き出し + 11GB 新しい HFile へ の Write) § 500 Region では – 8.5TB の Read、12.5TB の Write è ノードの長時間の停止 – HFile の数が少なくなれば、より状況は悪化 § ベストプラクティスは、ノードあたり 500GB 未満にすること (50 Region)
25.
25 ©MapR Technologies
Level-‐DB § 階層化され、対数的に増加 – L1: 2 x 1MB ファイル – L2: 10 x 1MB – L3: 100 x 1MB – L4: 1,000 x 1MB, など § コンパクションのオーバーヘッド – I/O ストームの回避 (10MB 未満の細かい単位で I/O 処理) – しかし、HBase と比較して非常に大きな帯域を必要とする § Read オーバーヘッドは依然大きい – 10〜15 シーク、最下層のサイズが非常に大きい場合はそれ以上 – 1KB レコードを取得するために 40KB〜60KB のディスクからの Read
26.
26 ©MapR Technologies
BTree の分析 § Read は直接データを発見、最速であることは証明済み – 内部ノードは Key のみを保持 – 非常に大きなブランチングファクター – Value はリーフのみに存在 – このためキャッシュが有効に機能する – キャッシュがない場合、R = logN シーク – 1KB レコードの Read で logN ブロックのディスクからの転送 § Write は挿入処理を伴い、遅い – 即時に正しい位置に挿入される – さもなければ Read で発見できないため – BTree の継続的なリバランスが要求される – 挿入パスにおいて激しいランダム I/O を引き起こす – キャッシュがない場合、W = 2.5倍 + logN シーク
27.
27 ©MapR Technologies
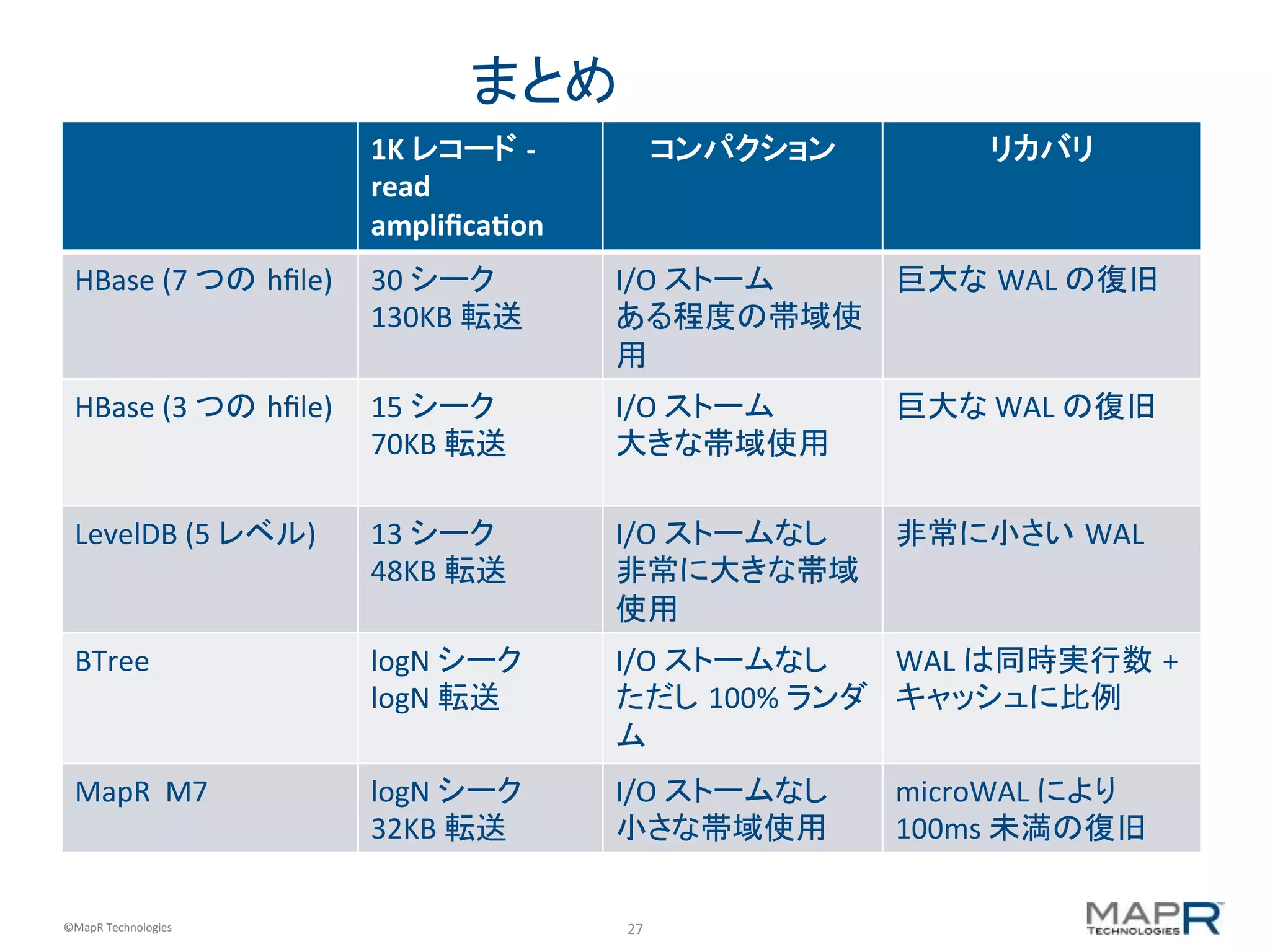
1KB レコード -‐ Read アンプリ フィケーション コンパクション リカバリ HBase (7 つの HFile) 30 シーク 130KB 転送 I/O ストーム ある程度の帯域使 用 巨大な WAL の復旧 HBase (3 つの HFile) 15 シーク 70KB 転送 I/O ストーム 大きな帯域使用 巨大な WAL の復旧 LevelDB (5 レベル) 13 シーク 48KB 転送 I/O ストームなし 非常に大きな帯域 使用 非常に小さい WAL BTree logN シーク logN 転送 I/O ストームなし ただし 100% ランダ ム WAL は同時実行数 + キャッシュに比例 MapR M7 logN シーク 32KB 転送 I/O ストームなし 小さな帯域使用 microWAL により 100ms 未満の復旧 まとめ
28.
確認のために いくつかの性能値を見てみる
29.
29 ©MapR Technologies
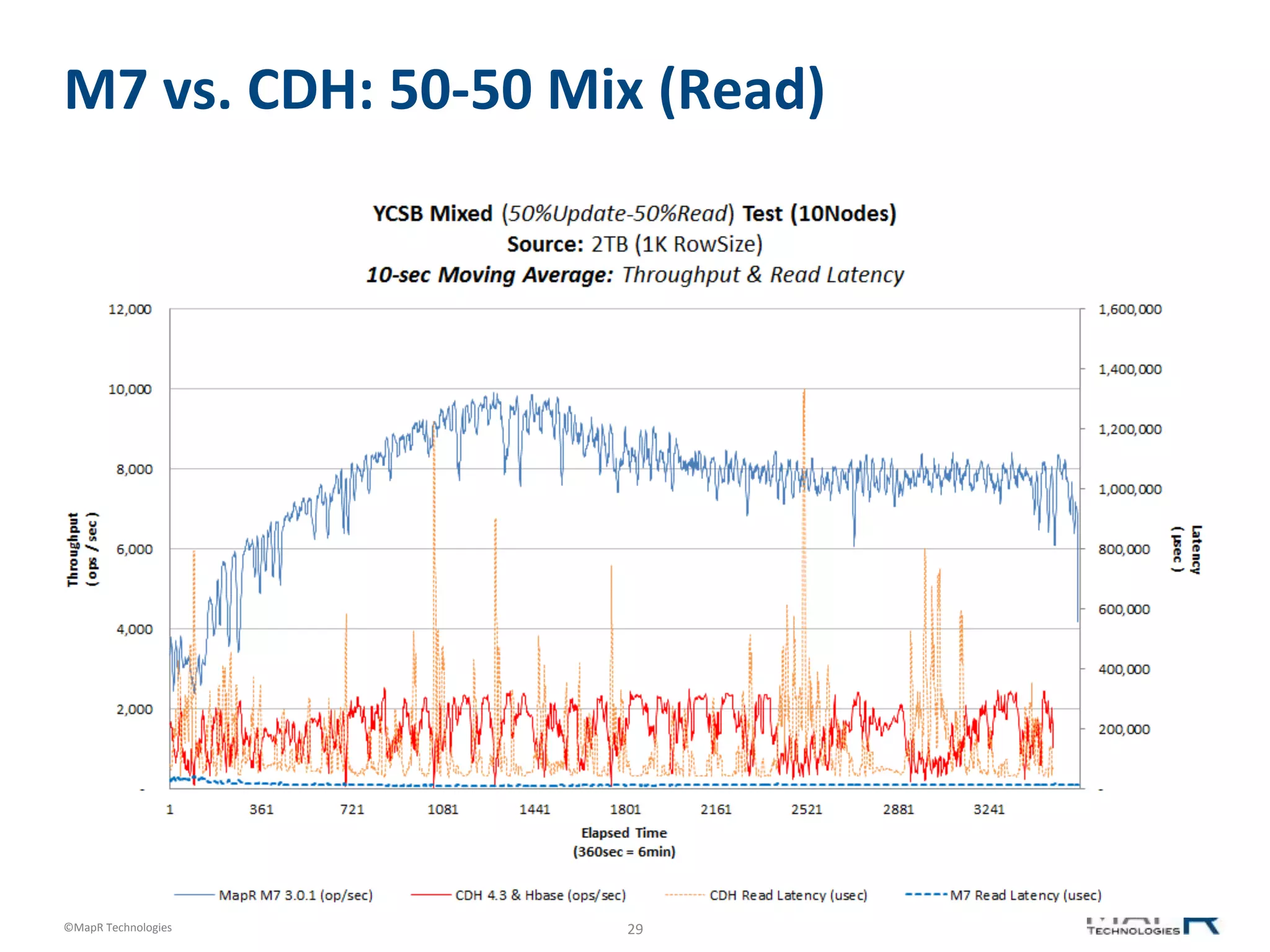
M7 vs. CDH: 50-‐50 Mix (Read)
30.
30 ©MapR Technologies
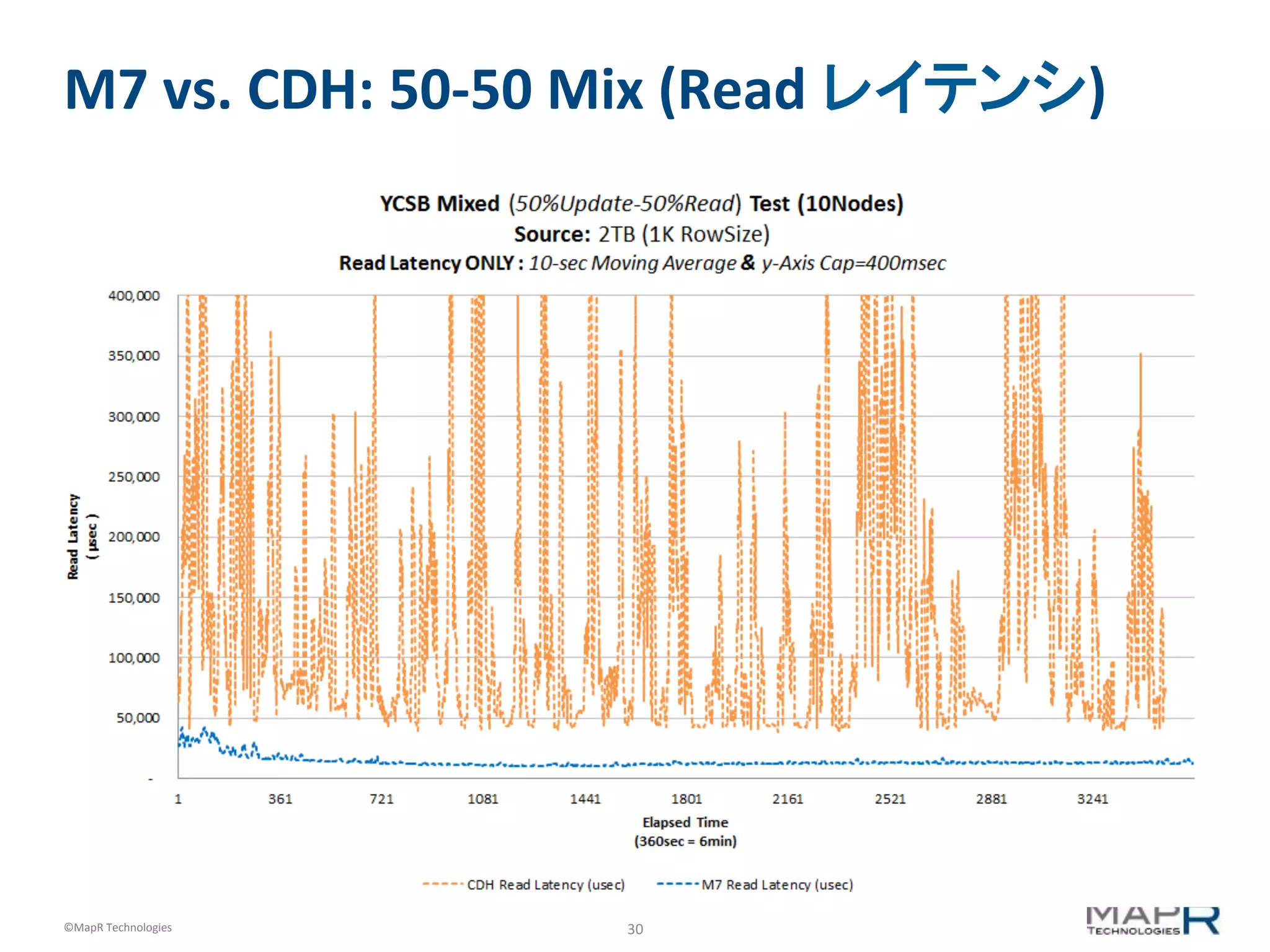
M7 vs. CDH: 50-‐50 Mix (Read レイテンシ)
31.
31 ©MapR Technologies
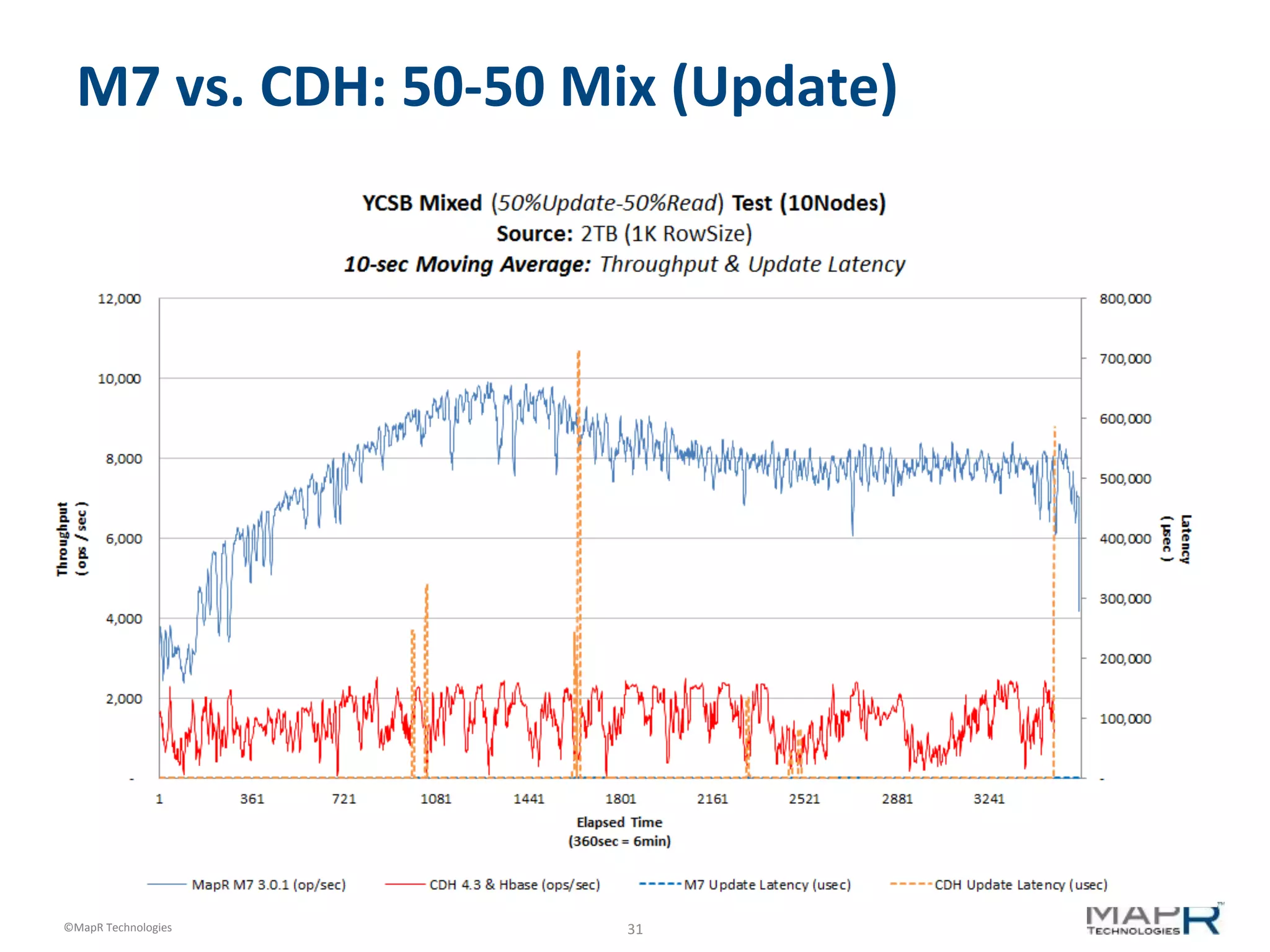
M7 vs. CDH: 50-‐50 Mix (Update)
32.
32 ©MapR Technologies
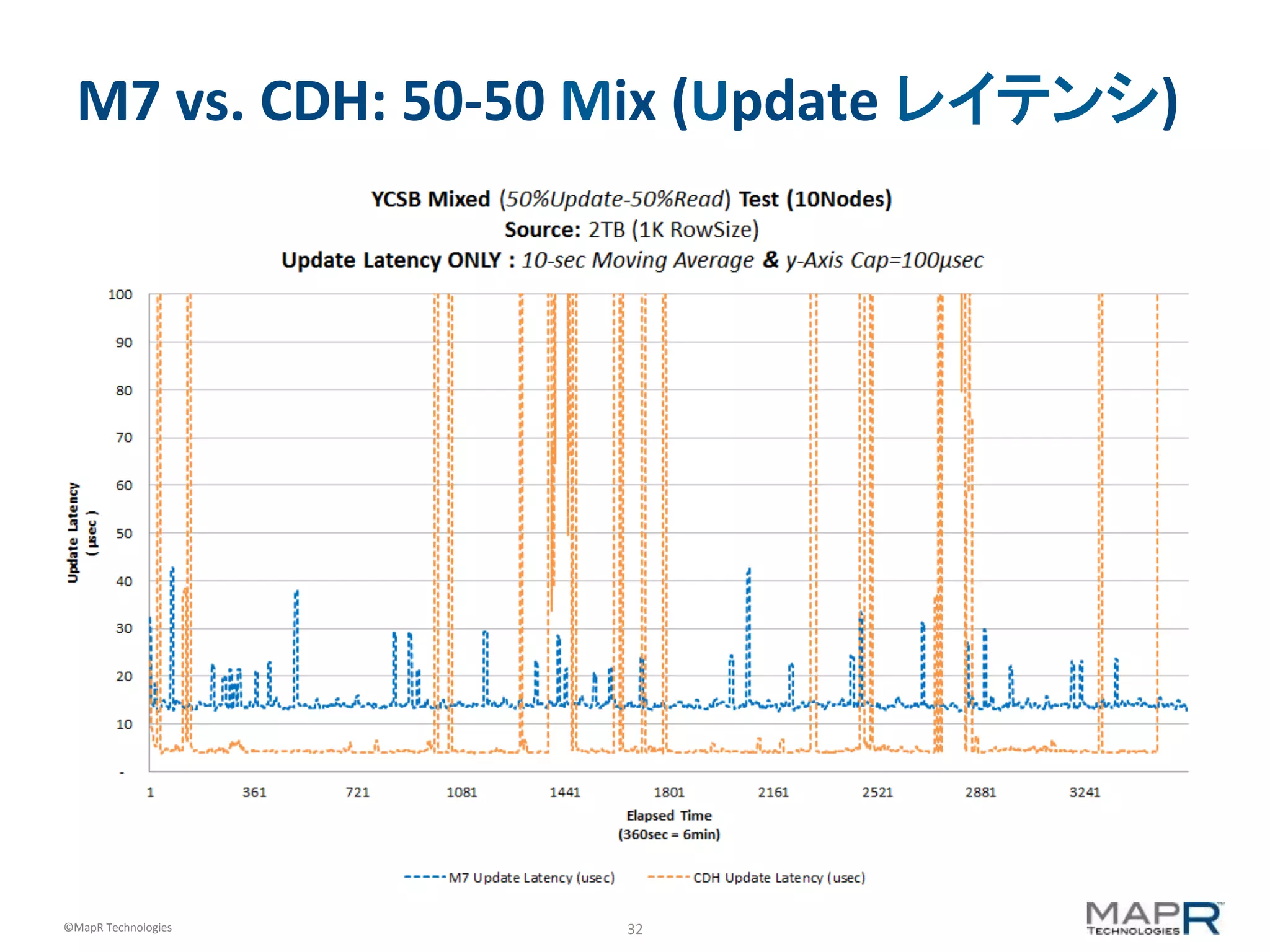
M7 vs. CDH: 50-‐50 Mix (Update レイテンシ)
33.
33 ©MapR Technologies
MapR M7によるHBaseアプリケーションの高速化 ベンチマーク MapR 3.0.1 (M7) CDH 4.3.0 (HBase) MapR 性能比 50% Read, 50% Update 8000 1695 5.5倍 95% Read, 5% Update 3716 602 6倍 Read 5520 764 7.2倍 スキャン (50 行) 1080 156 6.9倍 CPU: 2 x Intel Xeon CPU E5645 2.40GHz 12 コア RAM: 48GB ディスク: 12 x 3TB (7200 RPM) レコードサイズ: 1KB データサイズ: 2TB OS: CentOS Release 6.2 (Final) ベンチマーク MapR 3.0.1 (M7) CDH 4.3.0 (HBase) MapR 性能比 50% Read, 50% Update 21328 2547 8.4倍 95% Read, 5% update 13455 2660 5倍 Read 18206 1605 11.3倍 スキャン (50 行) 1298 116 11.2倍 CPU: 2 x Intel Xeon CPU E5620 2.40GHz 8 コア RAM: 24GB ディスク: 1 x 1.2TB Fusion I/O ioDrive2 レコードサイズ: 1KB データサイズ: 600GB OS: CentOS Release 6.3 (Final) HDD 使用時の MapR の性能: 5-‐7 倍 SSD 使用時の MapR の性能: 5-‐11.3 倍
34.
34 ©MapR Technologies
M7: Fileserver が Region を管理 § Region は全体がコンテナ内部に格納される – ZooKeeper によるコーディネーションは行われない § コンテナが分散トランザクションをサポート – レプリケーションも行われる § システム内で行われるコーディネーションは分割のみ – Region マップとデータコンテナ間での調整 – ファイルとデータチャンクの扱いにおいて既にこの課題は解決済 み
35.
35 ©MapR Technologies
サーバーの再起動 § コンテナレポートは全部合わせてもごくわずか – 1,000 ノードのクラスタで CLDB が必要とする DRAM は 2GB § ボリュームはすぐにオンラインになる – 各ボリュームは他ボリュームから独立に管理 – コンテナの最小レプリカ数を満たせばすぐにオンラインに
36.
36 ©MapR Technologies
サーバーの再起動 § コンテナレポートは全部合わせてもごくわずか – 1,000 ノードのクラスタで CLDB が必要とする DRAM は 2GB § ボリュームはすぐにオンラインになる – 各ボリュームは他ボリュームから独立に管理 – コンテナの最小レプリカ数を満たせばすぐにオンラインに – クラスタ全体を待たない (例: HDFS は 99.9% のブロックレポートが上がるのを待つ)
37.
37 ©MapR Technologies
サーバーの再起動 § コンテナレポートは全部合わせてもごくわずか – 1,000 ノードのクラスタで CLDB が必要とする DRAM は 2GB § ボリュームはすぐにオンラインになる – 各ボリュームは他ボリュームから独立に管理 – コンテナの最小レプリカ数を満たせばすぐにオンラインに – クラスタ全体を待たない (例: HDFS は 99.9% のブロックレポートが上がるのを待つ) § 1,000 ノードのクラスタは 5 分以内に再起動
38.
38 ©MapR Technologies
M7 の即時復旧 § Region 毎に 0〜40 個の microWAL – アイドル状態の WAL はすぐにゼロになるため、ほとんどは空 – すべての microWAL の復旧を待たずに Region が起動 – Region の復旧はバックグラウンドで並列処理 – Key へのアクセスがあると、対象の microWAL はインラインで復旧 される – 1000〜10000倍の速さで復旧
39.
39 ©MapR Technologies
M7 の即時復旧 § Region 毎に 0〜40 個の microWAL – アイドル状態の WAL はすぐにゼロになるため、ほとんどは空 – すべての microWAL の復旧を待たずに Region が起動 – Region の復旧はバックグラウンドで並列処理 – Key へのアクセスがあると、対象の microWAL はインラインで復旧 される – 1000〜10000倍の速さで復旧 § なぜ HBase ではできなくて、M7ではできるのか? – M7 はMapR ファイルシステムのユニークな機能を活用しており、 HDFS の様々な制約の影響を受けない – ディスク上のファイル数の上限がない – オープンできるファイル数の上限がない – I/O パスがランダム Write をディスクに対するシーケンシャル Write に変換する
40.
40 ©MapR Technologies
MapR M7によるHBaseアプリケーションの高速化 ベンチマーク MapR 3.0.1 (M7) CDH 4.3.0 (HBase) MapR 性能比 50% Read, 50% Update 8000 1695 5.5倍 95% Read, 5% Update 3716 602 6倍 Read 5520 764 7.2倍 スキャン (50 行) 1080 156 6.9倍 CPU: 2 x Intel Xeon CPU E5645 2.40GHz 12 コア RAM: 48GB ディスク: 12 x 3TB (7200 RPM) レコードサイズ: 1KB データサイズ: 2TB OS: CentOS Release 6.2 (Final) ベンチマーク MapR 3.0.1 (M7) CDH 4.3.0 (HBase) MapR 性能比 50% Read, 50% Update 21328 2547 8.4倍 95% Read, 5% update 13455 2660 5倍 Read 18206 1605 11.3倍 スキャン (50 行) 1298 116 11.2倍 CPU: 2 x Intel Xeon CPU E5620 2.40GHz 8 コア RAM: 24GB ディスク: 1 x 1.2TB Fusion I/O ioDrive2 レコードサイズ: 1KB データサイズ: 600GB OS: CentOS Release 6.3 (Final) HDD 使用時の MapR の性能: 5-‐7 倍 SSD 使用時の MapR の性能: 5-‐11.3 倍
Download



















































































![[B27] エンタープライズ NoSQL/HBase プラットフォーム – MapR M7 エディション by Masataka Oka](https://cdn.slidesharecdn.com/ss_thumbnails/b27maprm7-131126004827-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



























