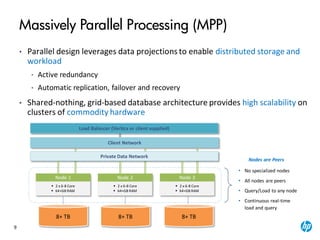
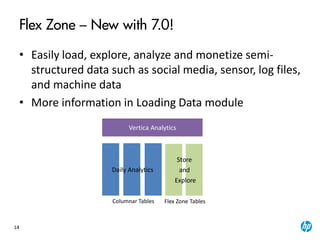
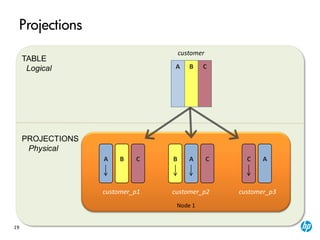
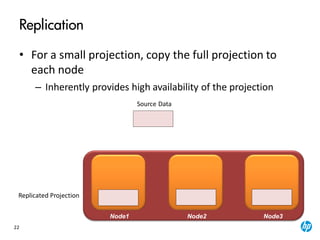
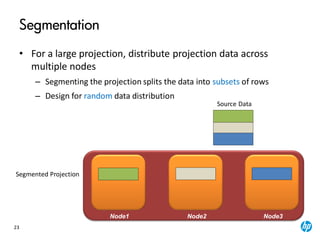
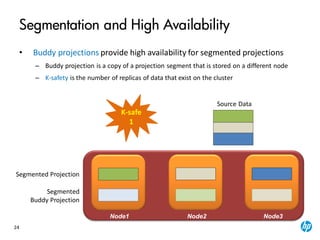
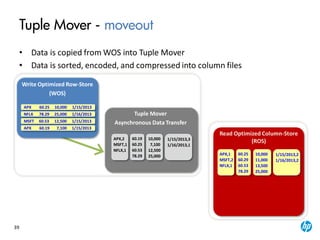
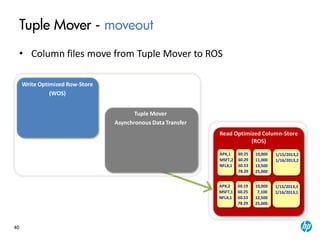
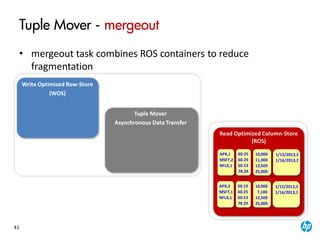
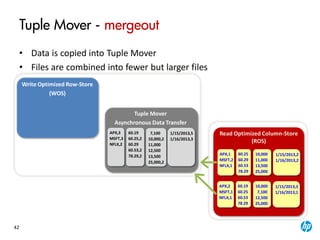
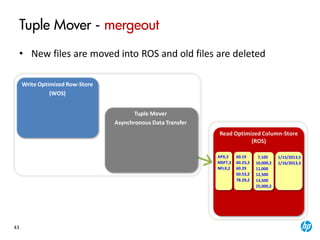
The document provides an overview of the Vertica analytics platform, detailing its architecture, features, and operational processes such as data storage and query execution. Key concepts include the column-oriented storage model, transaction handling, and high availability features that ensure continuous querying and data load. It also highlights the benefits of advanced compression, projections for optimized query execution, and integration with existing tools.












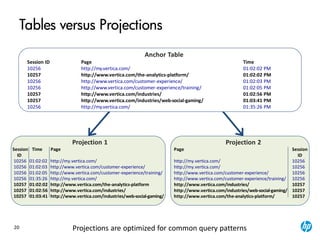






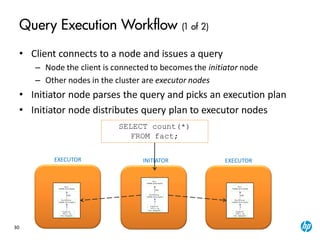
| Aggregates: customer_age), customer_age), count(*)
| Group By: customer_region, customer_name
| +---> STORAGE ACCESS for customer_dimension [Cost:407,Rows:6K](PATH ID:2)
| | Projection: public.customer_dimension_VMart_Design_node0001
| | Materialize: customer_region, customer_name, customer_age
| | Filter: (customer_gender = 'Male')
| | Filter: (customer_region = ANY (ARRAY['East', 'Midwest']))
EXPLAIN
SELECT customer_name,customer_region,avg(customer_age),count(*)
FROM customer_dimension
WHERE customer_gender='Male' and customer_region in('East','Midwest')
GROUP BY customer_region, customer_name;](https://image.slidesharecdn.com/1essentials7-160229065636/85/Vertica-7-0-Architecture-Overview-29-320.jpg)







![[EN] Building modern data pipeline with Snowflake + DBT + Airflow.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/enbuildingmoderndatapipelinewithsnowflakedbtairflow-231024053710-6b96c278-thumbnail.jpg?width=640&height=640&fit=bounds)


























































































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)




