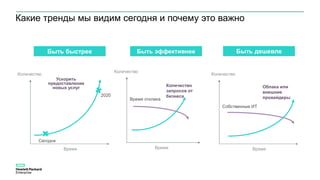
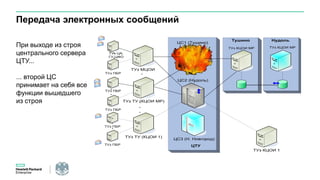
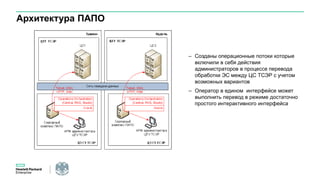
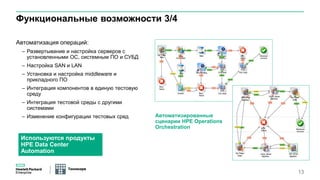
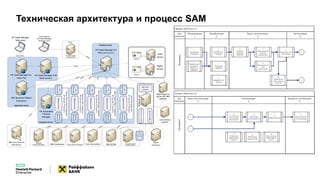
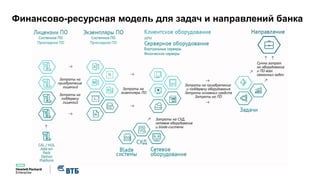
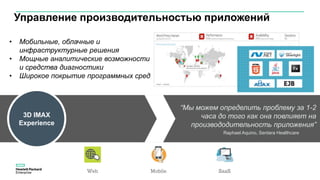
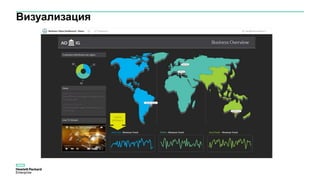
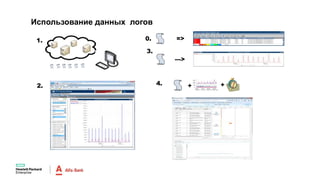
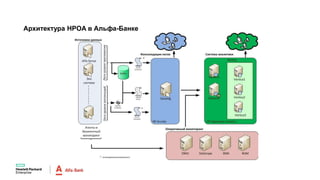
Документ описывает конференцию по программным решениям HPE, состоявшуюся 14 апреля 2016 года, и охватывает вопросы стратегии HPE, автоматизации IT-услуг, а также важность преобразования в гибридную инфраструктуру для повышения эффективности и инноваций в бизнесе. Приводятся данные о текущих и будущих IT-трендах, включая необходимость DevOps и автоматизации процессов для снижения времени на внедрение и управление приложениями. Также рассматриваются различные примеры и подходы к автоматизации в области электронной передачи сообщений в банковской системе России.