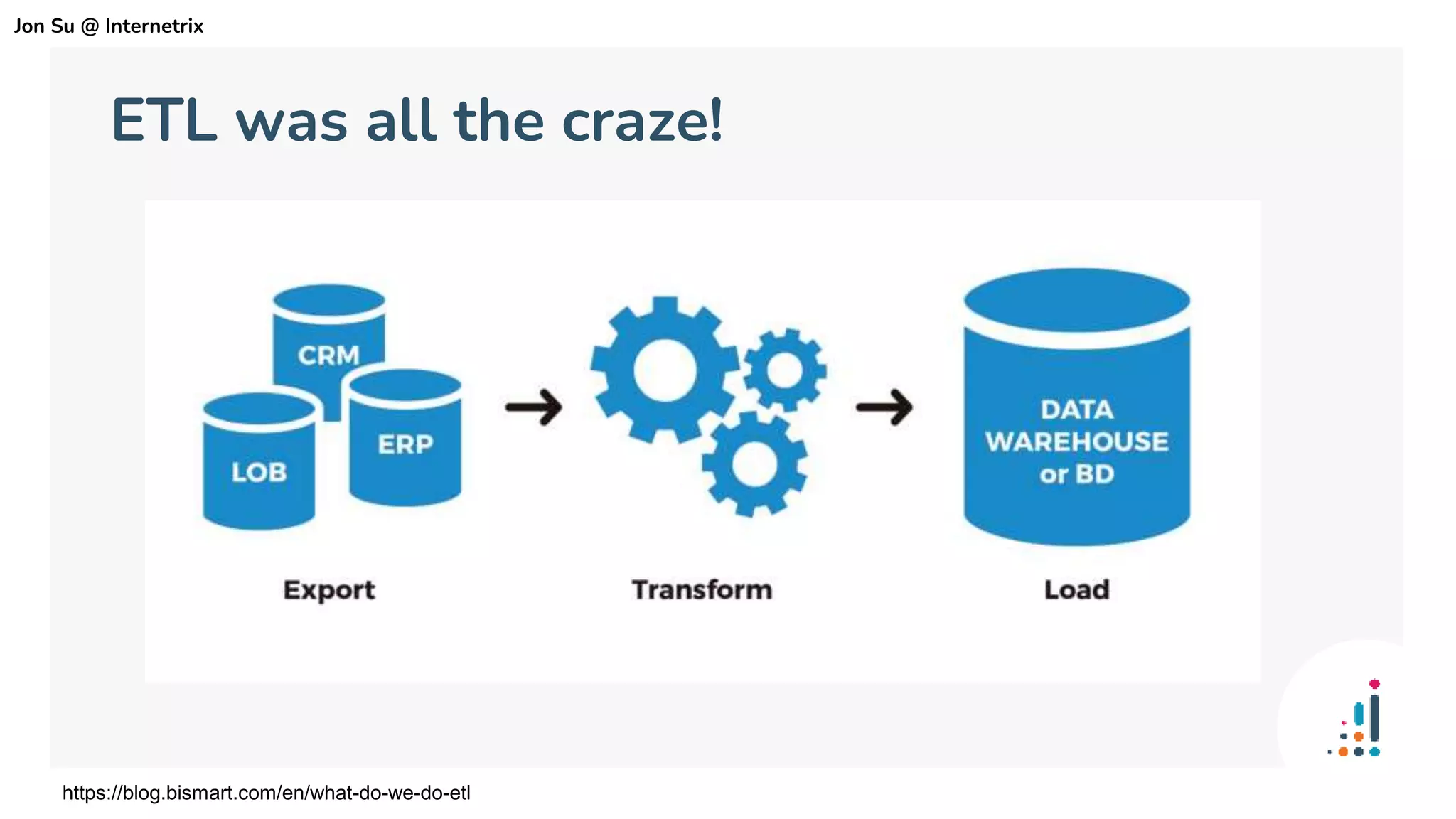
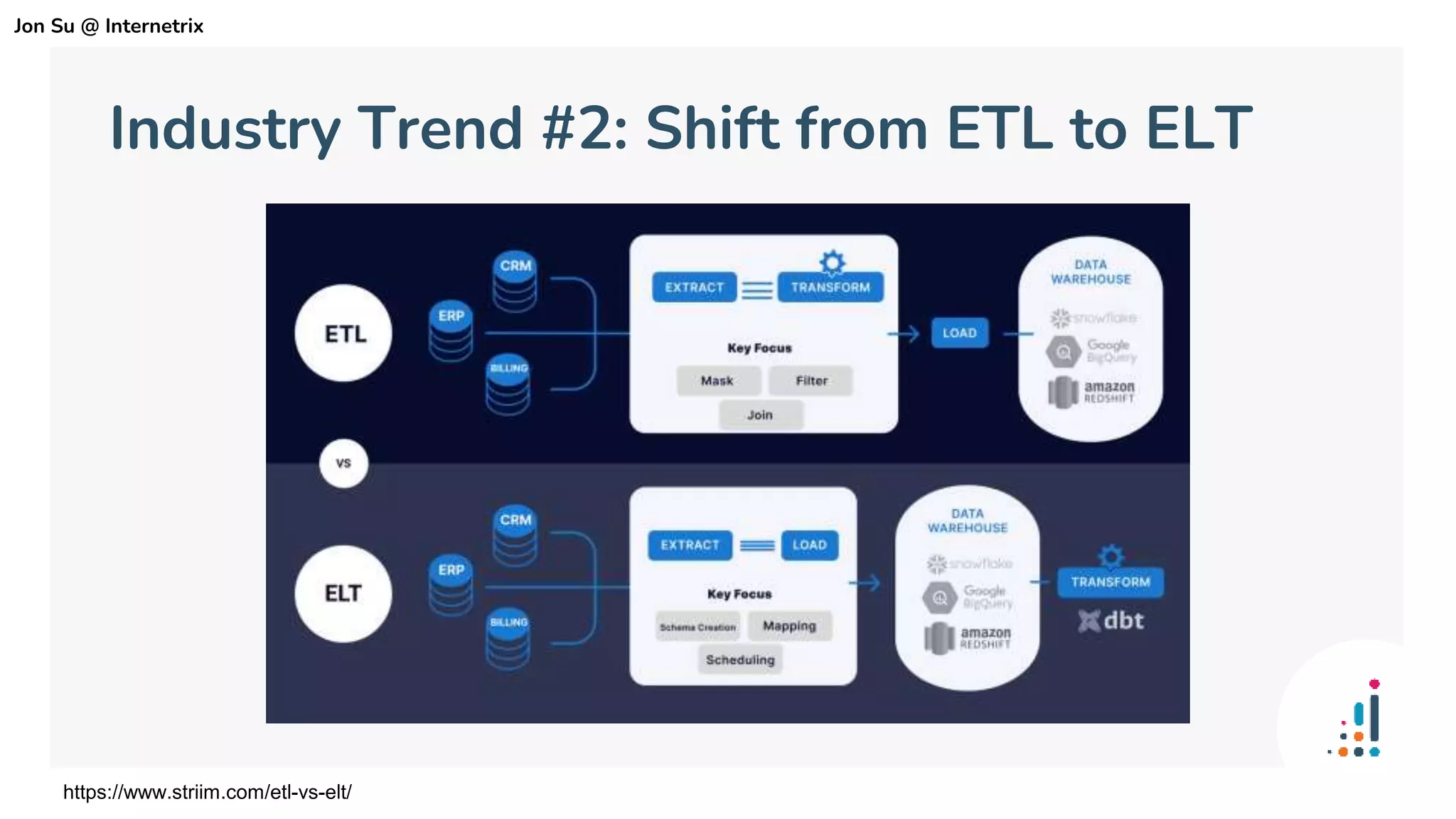
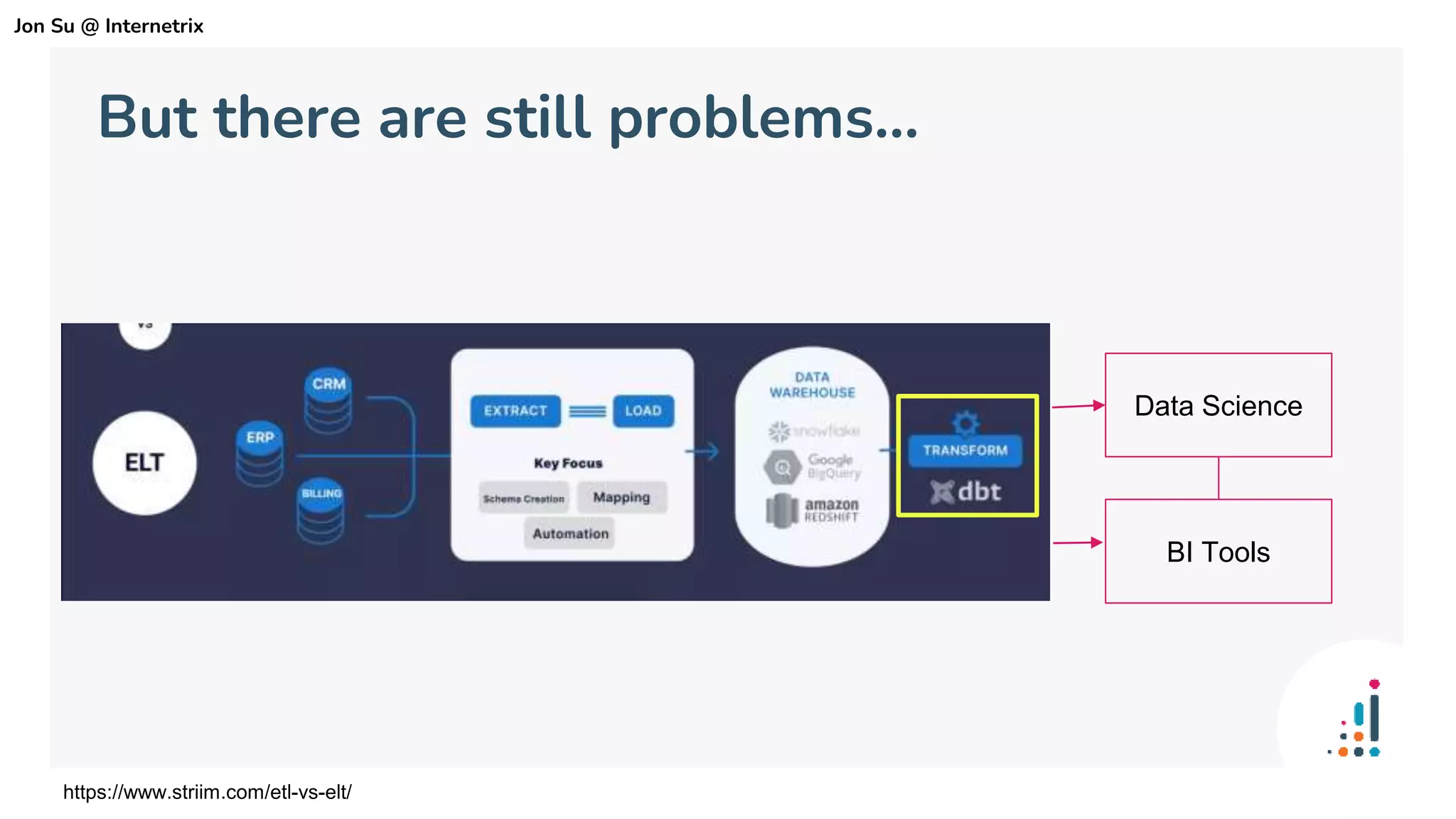
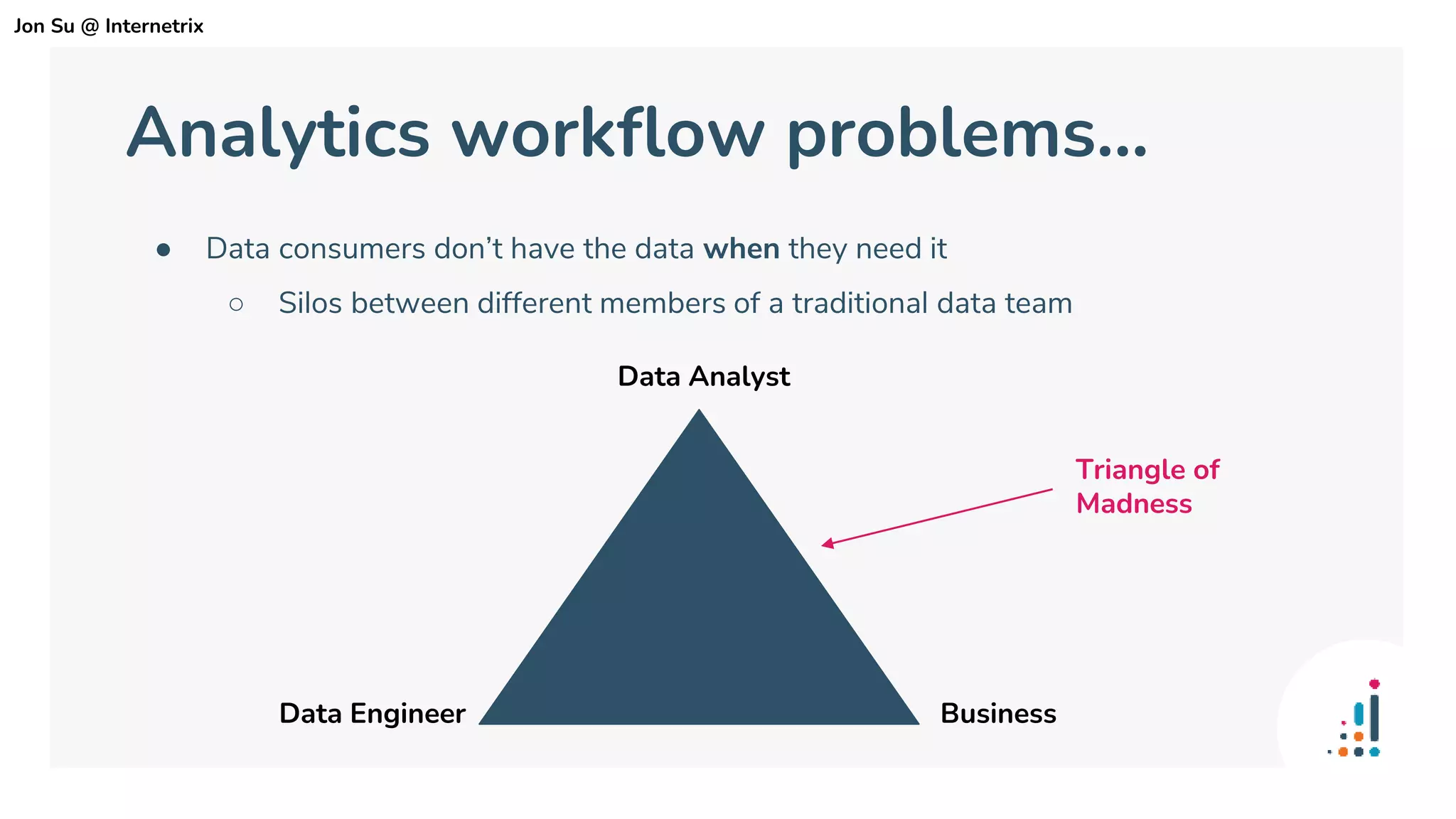
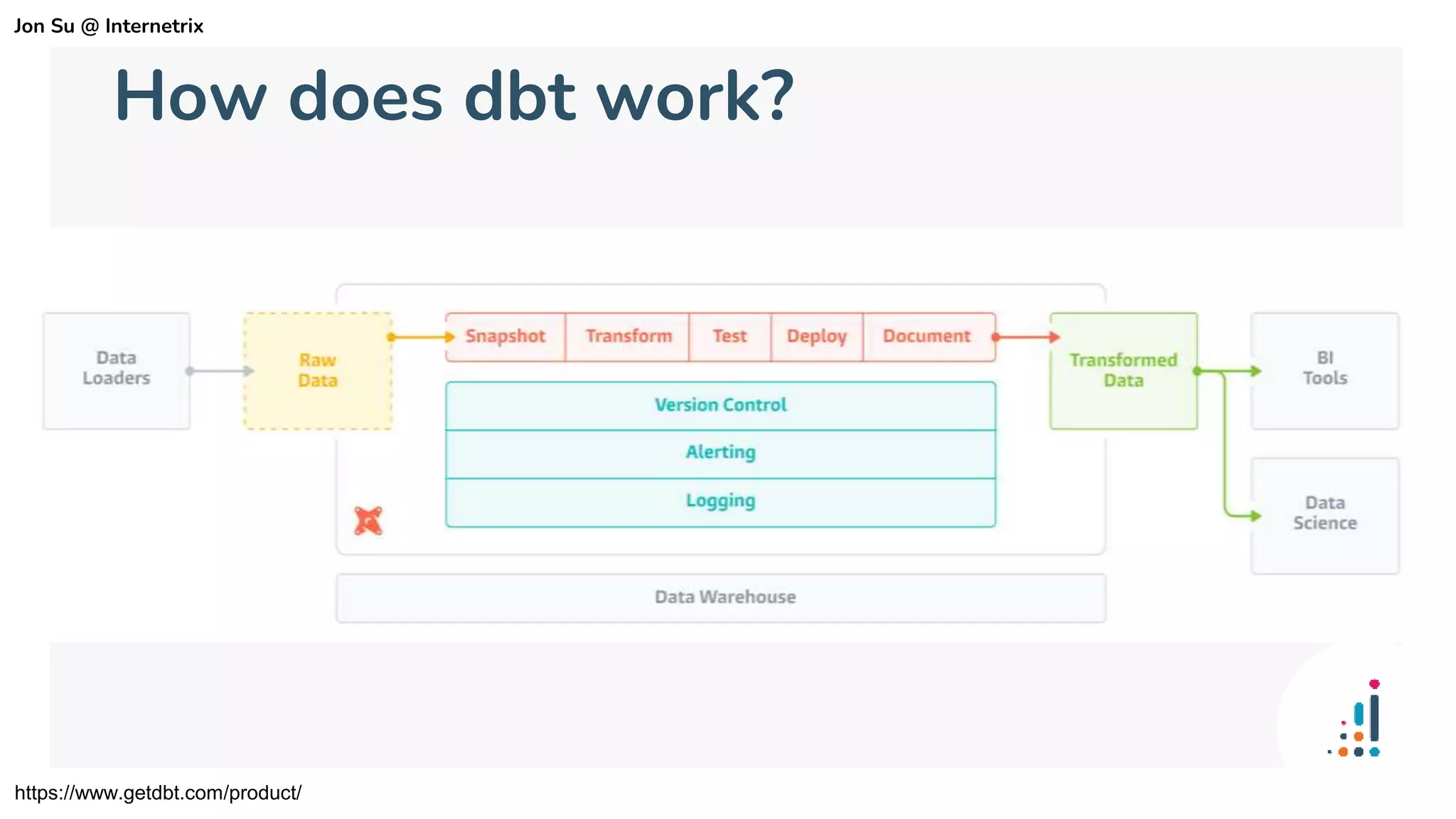
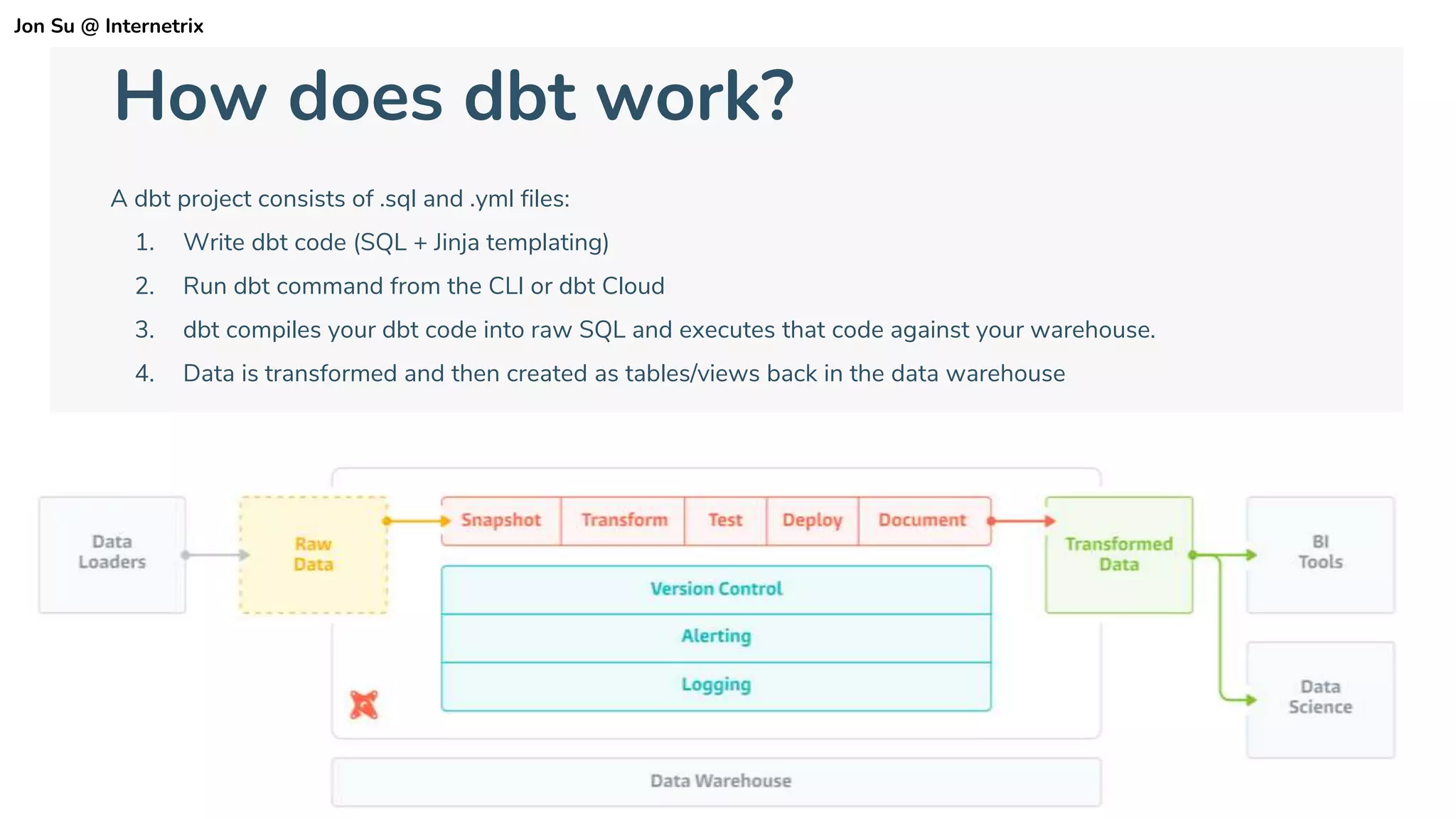
The document discusses the use of dbt (data build tool) to improve analytics workflows by allowing users who know SQL to create their own data pipelines. It highlights industry trends such as the shift from ETL to ELT and the challenges faced by data teams, including data silos and dashboard issues. The presentation includes a demo of dbt in action using a Google merchandising dataset to showcase its capabilities.











































![[DSC DACH 24] Ship data faster with dbt - Sean McIntyre](https://cdn.slidesharecdn.com/ss_thumbnails/seanmcintyre-240921155005-f23c4e8e-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 23] Matteo Molteni - Implementing a Robust CI Workflow with dbt f...](https://cdn.slidesharecdn.com/ss_thumbnails/matteomolteni-implementingarobustciworkflow-231129090959-794aed63-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 24] Jesse Anderson - The State of Data Engineering](https://cdn.slidesharecdn.com/ss_thumbnails/jesseanderson-thestateofdataengineeringbigdata-241219143316-5fdffa3a-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)