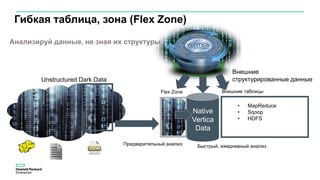
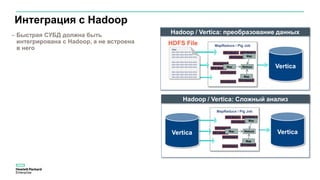
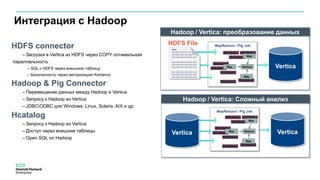
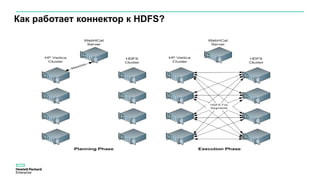
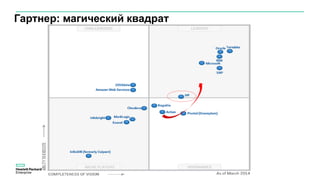
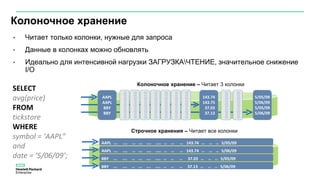
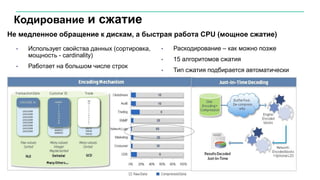
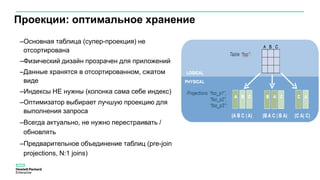
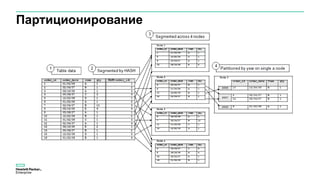
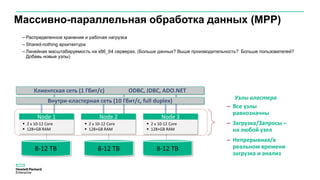
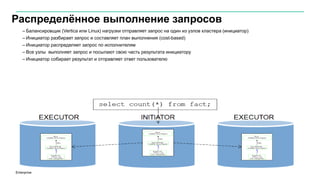
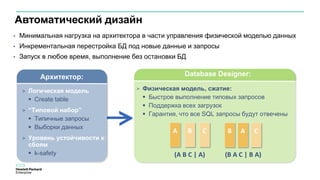
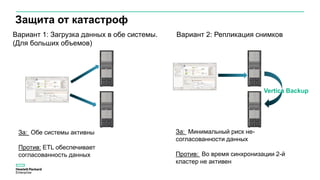
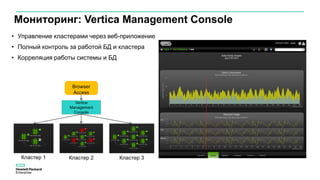
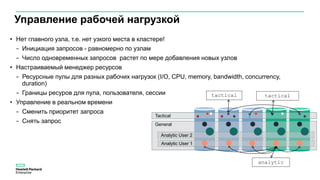
Документ описывает значительное увеличение объема данных, создаваемых в интернете, включая примеры и статистику. Он также разбирает недостатки традиционных платформ обработки данных и предлагает решение в виде аналитической платформы Vertica для быстрого анализа больших данных. Подразумевается необходимость эффективных стратегий для извлечения полезной информации из больших объемов данных.






















![Исходный код в R
UDx в R, пример: метод K-средних
# Example: K-means (k=5)
# Input: two-dimensional points
# Output: the point coordinates plus their assigned
# cluster
kmeansClu <- function(x)
{
cl <- kmeans(x,5,10)
res <- data.frame(x[,1:2], cl$cluster)
res
kmeansCluFactory <- function()
{
list(name=kmeansClu,
udxtype=c("transform"),
intype=c("float","float"),
outtype=c("float","float","int"),
outnames=c("x","y","cluster") )
}
Создание и использование
функции
-- Define function
CREATE LIBRARY rlib
AS ‘/path/rcode.R’ LANGUAGE 'R';
CREATE TRANSFORM FUNCTION Kmeans
AS LANGUAGE 'R' NAME 'kmeansCluFactory'
LIBRARY rlib;
-- Use function
CREATE TABLE point_data (
x FLOAT, y FLOAT );
SELECT Kmeans(x, y)
OVER() FROM point_data;](https://image.slidesharecdn.com/shortinfrastructureoverviewruhpe-vertica-160407053005/85/Short-Infrastructure-Overview-ru-hpe-Vertica-36-320.jpg)