Downloaded 212 times










![Future Directions and Questions Archiving information lifecycle (sqoop) Invoking hadoop jobs from Vertica Joining Vertica data mid job Using Vertica for (structured) transient job data [email_address] Vertica.com/MapReduce](https://image.slidesharecdn.com/hadoop-verticav2-091003134832-phpapp02/75/Hadoop-World-Vertica-15-2048.jpg)

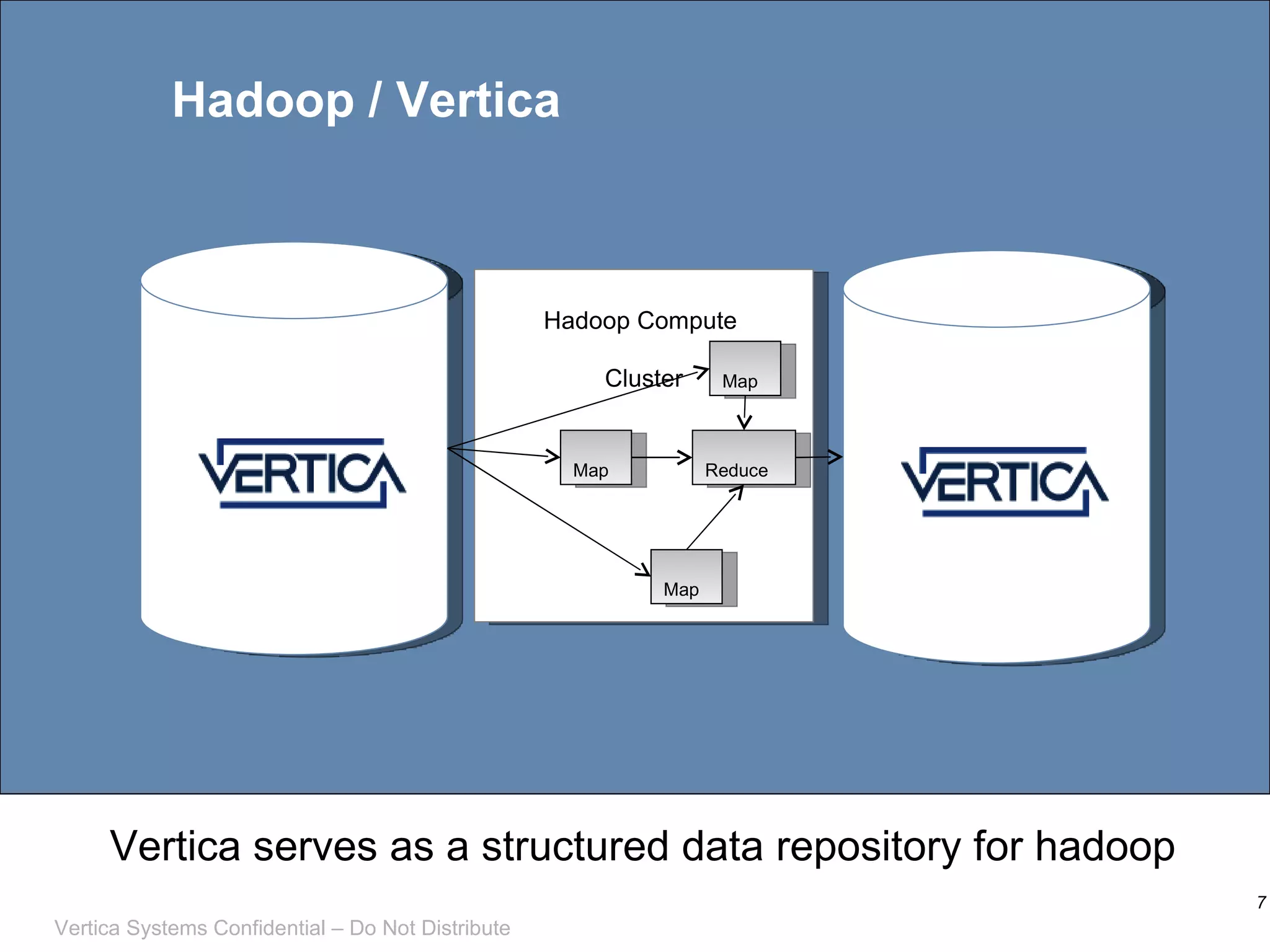
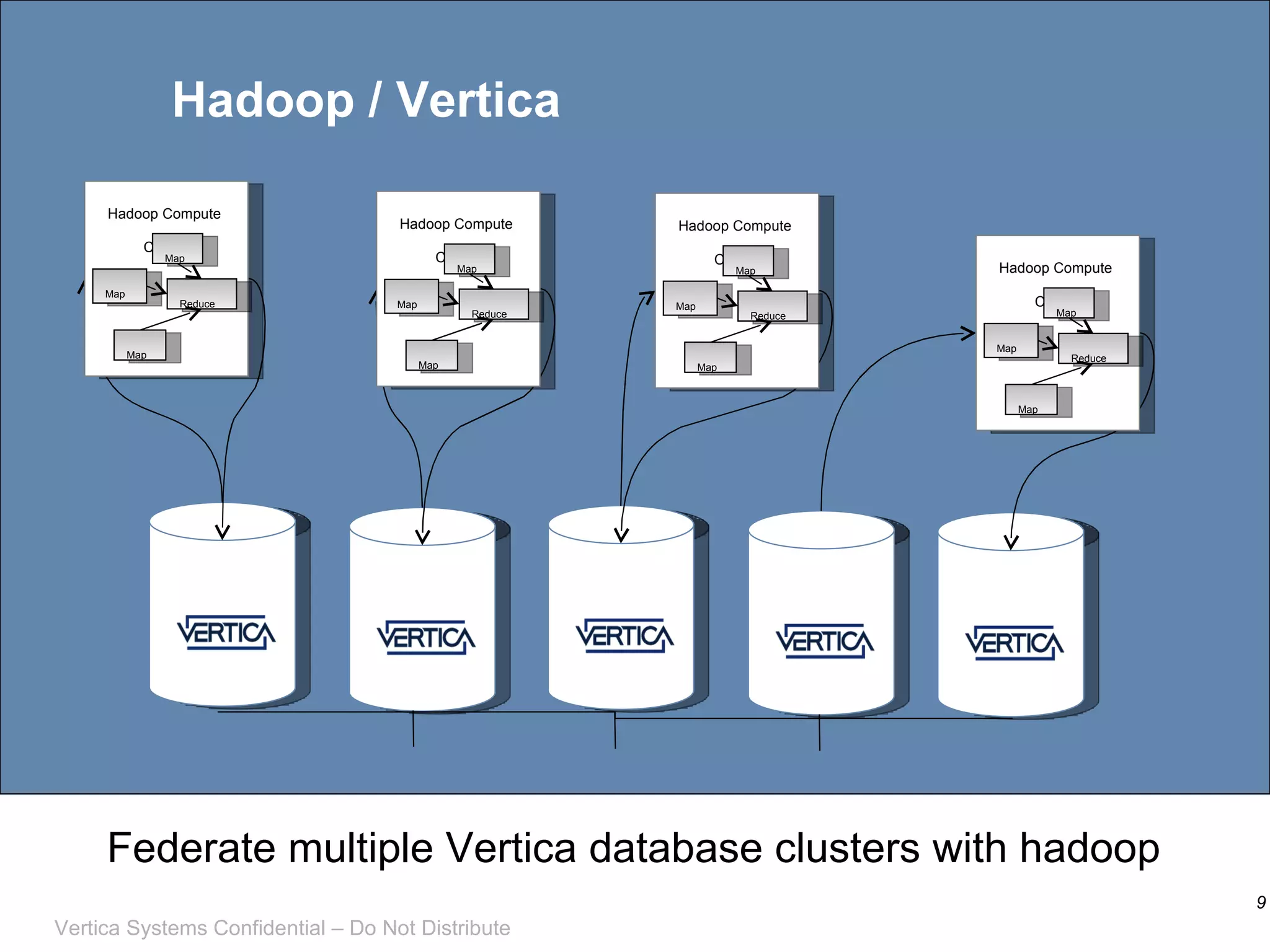
This document discusses integrating Apache Hadoop with Vertica, an analytic database with MPP columnar architecture. It describes how Vertica can be used as a data source and target for Hadoop MapReduce jobs, with Vertica input and output formatters allowing data to be moved between the two systems. Examples are provided of using Vertica to serve as a structured data repository for Hadoop and running algorithms like tickstore with map pushdown to optimize queries.










































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












