Download as PDF, PPTX




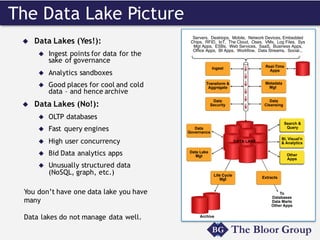






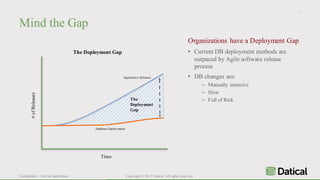



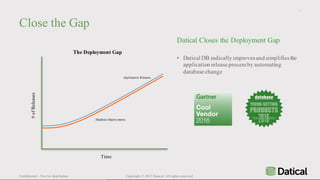
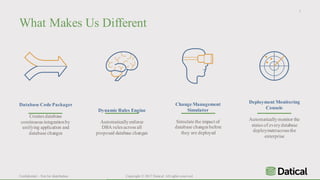
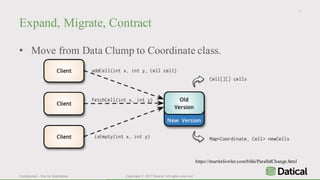
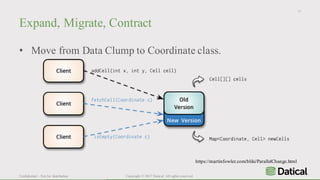
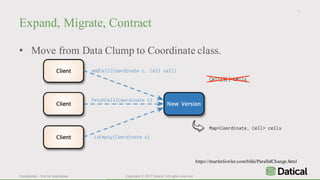
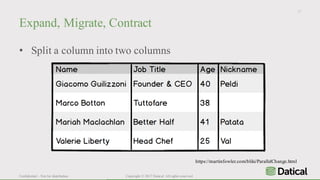

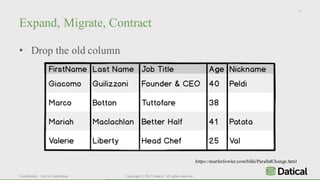
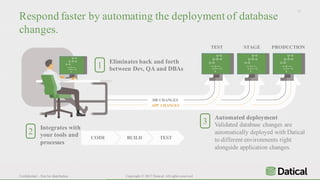



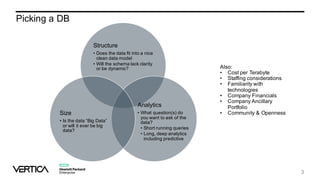


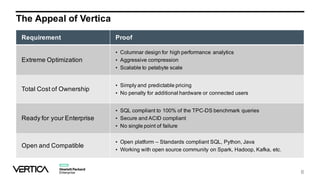



The document discusses the similarities and differences between data lakes and traditional databases, emphasizing the complexities of data management and the necessity for automation in database deployments due to increasing release delays and errors. It presents Datical's solutions for automating database changes to close the deployment gap and enhance application release processes. Additionally, the document highlights HPE Vertica's capabilities in data analytics, scalability, and integration with various data sources for optimized performance.



![Kb 40 kevin_klineukug_reading20070717[1]](https://cdn.slidesharecdn.com/ss_thumbnails/kb40kevinklineukugreading200707171-101026100915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































































