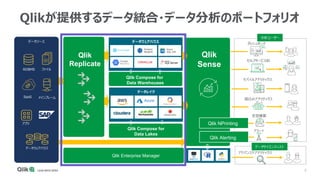
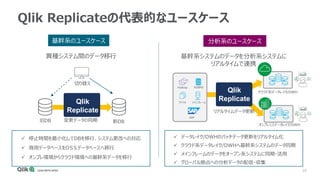
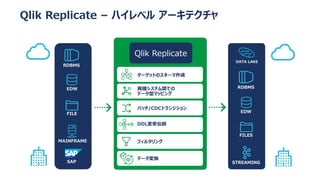
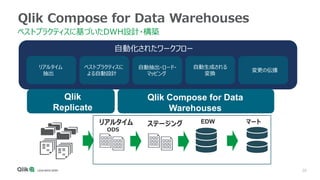
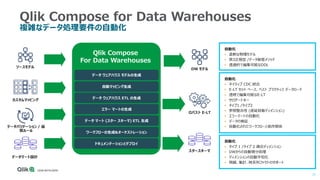
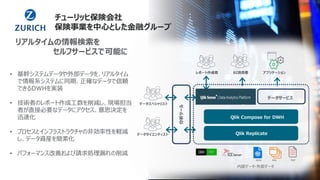
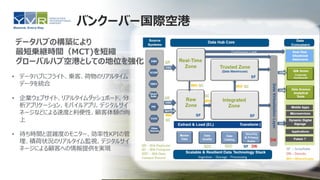
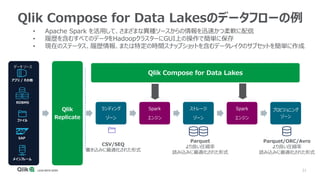
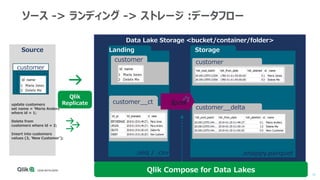
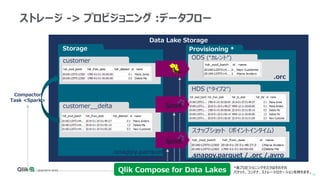
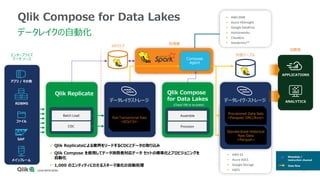
Qlik Compose for Data Warehouses automates the design and construction of data warehouses based on best practices. It can automatically extract, load, map, and transform data in real-time from source systems into operational data stores, data staging areas, and enterprise data warehouses. It also automatically propagates changes and designs the data warehouse architecture and schemas according to best practices like handling slowly changing dimensions for time series data.





![15
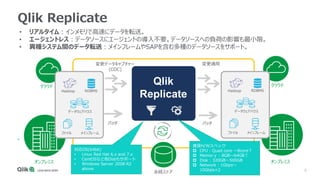
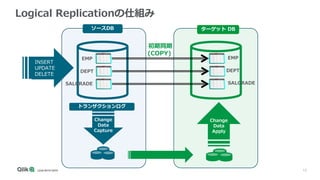
変更データキャプチャータスクのオプション
• [Full Load]:全てのデータを初期ロード
• [Apply Changes]:初期ロード完了後、ソースに対する変更キャプ
チャーしてターゲットに適用
• [Store Changes]: 適用された変更の履歴を保存(「テーブル名_ct」
の名称のテーブルに履歴を保存)
以下のタスクオプションをそれぞれ有効化・無効化が可能](https://image.slidesharecdn.com/qliktechtalk20200908qdi-201026082631/85/TECHTALK-20200908-Qlik-DWH-15-320.jpg)
![16
変更適用のモード
• [バッチ最適化]
✓ 変更を一括(変更のグループ)で適用することで、
似たような変更をまとめて適用
✓ シーケンシャルな整合性よりもパフォーマンスを優先
• [トランザクショナル]
✓ ソースに適用されたのと同じ順序でデータの更新分
をコピー
✓ パフォーマンスよりもシーケンシャルな整合性を優先
• [ストリーム最適化]
✓ メッセージストリーム (Kafka、Amazon Kinesis
など) の更新を複製
以下から変更適用のモードを選択可能](https://image.slidesharecdn.com/qliktechtalk20200908qdi-201026082631/85/TECHTALK-20200908-Qlik-DWH-16-320.jpg)




























































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)








