Downloaded 19 times











![@chbatey
RDD Operations
• Transformations - Similar to Scala collections API
• Produce new RDDs
• filter, flatmap, map, distinct, groupBy, union, zip, reduceByKey, subtract
• Actions
• Require materialization of the records to generate a value
• collect: Array[T], count, fold, reduce..](https://image.slidesharecdn.com/munichmarkch2015-cassandrasparkoverview-150305095417-conversion-gate01/85/Munich-March-2015-Cassandra-Spark-Overview-18-320.jpg)
![@chbatey
Word count
val file: RDD[String] = sc.textFile("hdfs://...")
val counts: RDD[(String, Int)] = file.flatMap(line =>
line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/munichmarkch2015-cassandrasparkoverview-150305095417-conversion-gate01/85/Munich-March-2015-Cassandra-Spark-Overview-19-320.jpg)




![@chbatey
Boiler plate
import com.datastax.spark.connector.rdd._
import org.apache.spark._
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
object BasicCassandraInteraction extends App {
val conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1")
val sc = new SparkContext("local[4]", "AppName", conf)
// cool stuff
}
Cassandra Host
Spark master e.g spark://host:port](https://image.slidesharecdn.com/munichmarkch2015-cassandrasparkoverview-150305095417-conversion-gate01/85/Munich-March-2015-Cassandra-Spark-Overview-28-320.jpg)
![@chbatey
Word Count + Save to Cassandra
val textFile: RDD[String] = sc.textFile("Spark-Readme.md")
val words: RDD[String] = textFile.flatMap(line => line.split("s+"))
val wordAndCount: RDD[(String, Int)] = words.map((_, 1))
val wordCounts: RDD[(String, Int)] = wordAndCount.reduceByKey(_ + _)
println(wordCounts.first())
wordCounts.saveToCassandra("test", "words", SomeColumns("word", "count"))](https://image.slidesharecdn.com/munichmarkch2015-cassandrasparkoverview-150305095417-conversion-gate01/85/Munich-March-2015-Cassandra-Spark-Overview-29-320.jpg)





![@chbatey
Now now…
val cc = new CassandraSQLContext(sc)
cc.setKeyspace("test")
val rdd: SchemaRDD = cc.sql("SELECT store_name, event_type, count(store_name) from customer_events
GROUP BY store_name, event_type")
rdd.collect().foreach(println)
[SportsApp,WATCH_STREAM,1]
[SportsApp,LOGOUT,1]
[SportsApp,LOGIN,1]
[ChrisBatey.com,WATCH_MOVIE,1]
[ChrisBatey.com,LOGOUT,1]
[ChrisBatey.com,BUY_MOVIE,1]
[SportsApp,WATCH_MOVIE,2]](https://image.slidesharecdn.com/munichmarkch2015-cassandrasparkoverview-150305095417-conversion-gate01/85/Munich-March-2015-Cassandra-Spark-Overview-35-320.jpg)




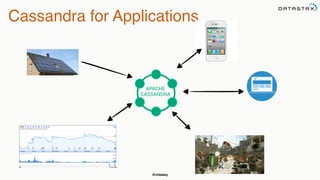
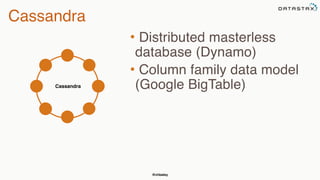
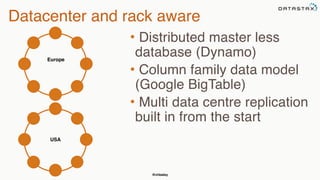
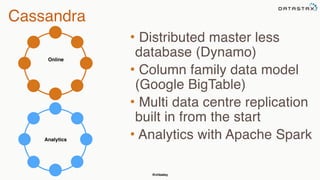
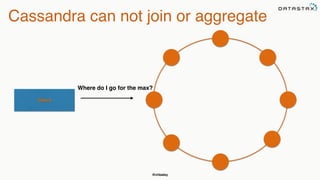
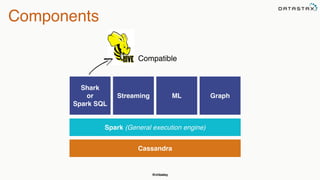
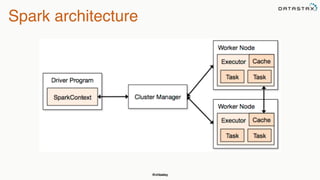
This document summarizes a presentation about integrating Apache Cassandra with Apache Spark. It introduces Christopher Batey as a technical evangelist for Cassandra and discusses DataStax as an enterprise distribution of Cassandra. It then provides overviews of Cassandra and Spark, describing their architectures and common use cases. The bulk of the document focuses on the Spark Cassandra Connector and examples of using it to load Cassandra data into Spark, perform analytics and aggregations, and write results back to Cassandra. It positions Spark as enabling slower, more flexible queries and analytics on Cassandra data.











































































































