Download as PDF, PPTX













![First Attempt: Sharded Mongo
● Familiar database
● Sharded Mongo by region
● Flexible data structures
● Large documents
○ Hard to prune old visits
○ Huge indexes (long rebuilds during scaling)
● Primary/secondary/mongos
○ Complicated deployment/updates
○ Vertical Scaling
● Bugs encountered with sharding
○ Shard boundaries
○ Cleanup after shard split
https://jira.mongodb.org/browse/SERVER-38971, https://jira.mongodb.org/browse/SERVER-38969
{
"_id": "alex",
"dc": "gce-us-east1",
"site": "games",
"events": [
{
"time": "10:01",
"type": "visit",
"url": "...",
...
},
{
"time": "10:02",
"type": "engage",
"url": "...",
...
},
...
],
"lastEvent": 10:02"
}](https://image.slidesharecdn.com/big-data-in-real-time-at-admiral-200616194453/75/Big-Data-in-Real-Time-How-ClickHouse-powers-Admiral-s-visitor-relationships-for-publishers-24-2048.jpg)

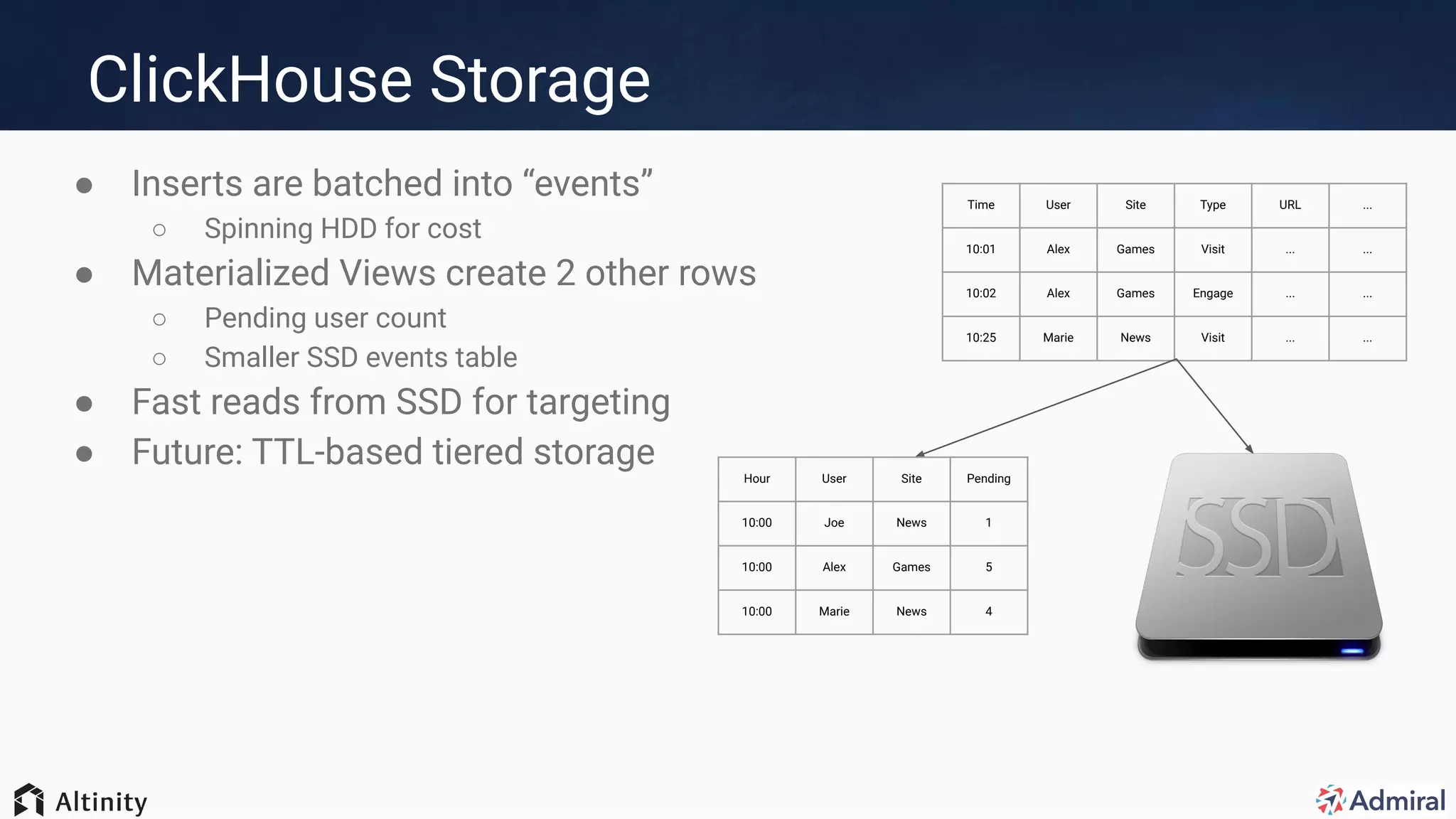


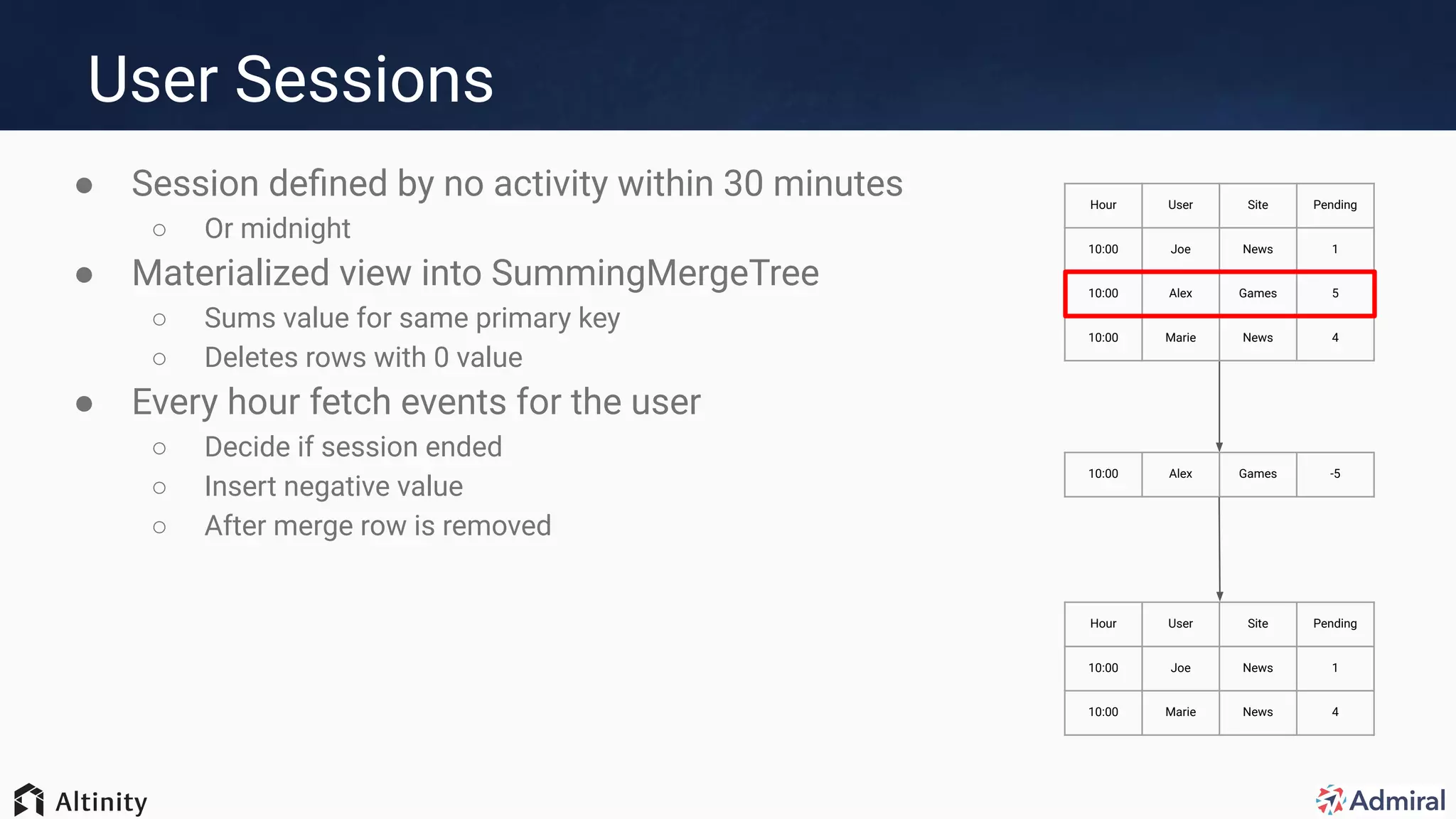

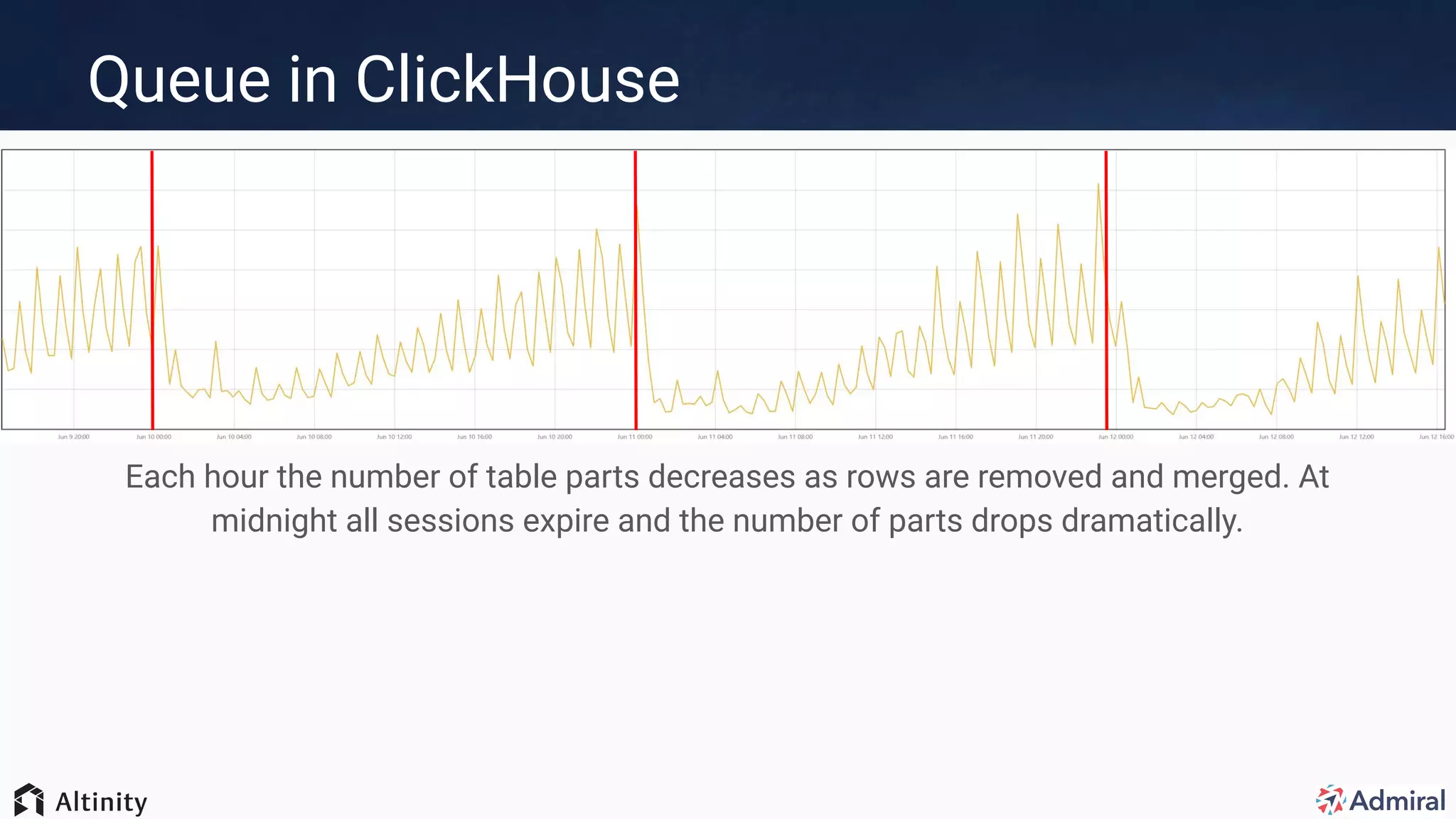




The document presents an overview of Admiral's use of ClickHouse for their visitor relationship management platform, highlighting the technical stack and features for scalable, efficient data handling. Key points include the transition from MongoDB to ClickHouse for improved storage capacity, performance, and reduced complexity in deployments. Admiral's implementation showcases real-time targeting, materialized views, and optimized query performance across multiple regions.













































![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)












![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

