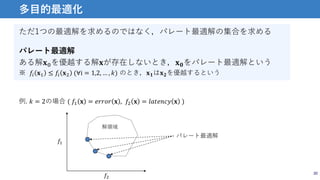
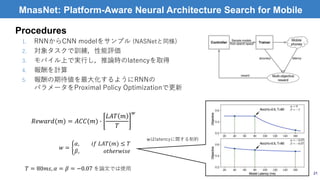
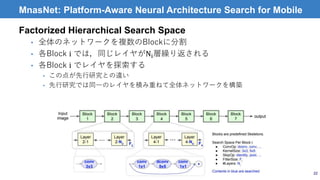
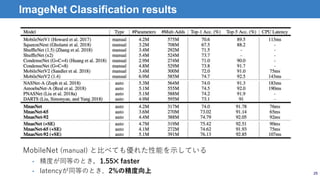
MnasNet: Platform-Aware NeuralArchitecture Search for Mobile
• Mingxing Tan et al., Google Brain
• arXiv:1807.11626v1
18
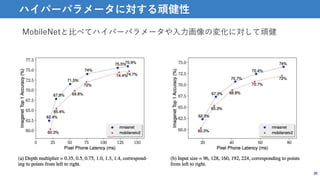
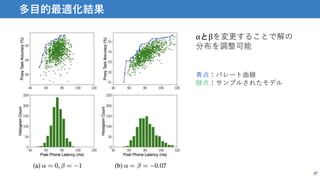
紹介する論文
• 性能だけでなく,modelの処理速度も考慮した多目的構造最適化
手法
• mobile phoneでの実行速度を最適化に使用
#2 I will talk about image restoration using evolutionary search.
Image restoration is to recover a clean image from its corrupted version.
These are image restoration tasks, image inpainting and denoising.
#3 In order to solve this task, learning-based methods which use CNNs have been introduced, and have shown good performance.
In these studies, researchers have approached the problem mainly from two directions.
One is to design new network architectures.
For example, the network of the bottom left is called MemNet, which contains many recursive connections and gate units.
The other is to develop new loss functions or training methods.
A recent trend is to use adversarial training, in which a generator is trained to perform image restoration, and a discriminator is trained to distinguish whether an input image is true image or a recovered one.


![菅沼 雅徳(すがぬま まさのり)
2
自己紹介
• 所属
• 2017.09 博士卒
• 2017.10 - 理化学研究所 AIP 特別研究員(東北大@岡谷研)
• 2018.10 - 東北大学 〇〇
• 研究分野
• 進化計算+深層学習
• [M. Suganuma et al.] Exploiting the potential of standard convolutional autoencoders for
image restoration by evolutionary search, ICML 2018
• [M. Suganuma et al.] A genetic programming approach to designing convolutional neural
network architectures, GECCO 2017 (Best paper award)](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-2-320.jpg)
![DLベースのSLAMにおいてもネットワーク構造は重要 (なはず)
• 精度,処理速度に大きな影響
• 構造設計には労力がかかる
3
Why architecture search?
CodeSLAM [Bloesch et al. 2018] DeepTAM [Zhou et al. 2018]
CNN-SLAM [Tateno et al. 2017]](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-3-320.jpg)
![4
Manual vs Auto
PSNR results
Noise
level
REDNet
[Mao et al., 2016]
MemNet
[Tai et al., 2017]
Designed arch.
[Suganuma et al., 2018]
𝜎 = 30 27.95 28.04 28.23
𝜎 = 50 25.75 25.86 26.17
𝜎 = 70 24.37 24.53 24.83
REDNet 30
MemNet 80
Designed arch. 15
Depth of the network
MemNet architecture [Tai et al. ICCV 2017] Designed architecture [Suganuma et al. ICML 2018]](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-4-320.jpg)


![7
最近の構造最適化手法 (CIFAR-10での性能)
GPU days
Accuracy
1.0
16800
0.9308
0.5 10
MetaQNN
[ICLR 2017]
NAS
[ICLR 2017]
0.9635 Efficient AS
[AAAI 2018]
0.9577
ENAS
[ICML 2018]
0.9711
NASNet-A
[CVPR 2018]0.9735
1800
CGPCNN
[GECCO 2017]
30
0.9503 Large-scale Evolution
[ICML 2017]
2700
0.9460
Hierarchical Evolution
[ICLR 2018]
300
AmoebaNet
[arXiv 2018]0.9745
3150
PNAS
[ECCV 2018]
0.9659
225
DARTS
[arXiv 2018]
4
RL EA
……
DenseNet SMBOGB](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-7-320.jpg)
![Large-scale Evolution [Real et al., ICML2017]
• シンプルな遺伝的アルゴリズム (GA)を用いた手法
• GPU250台使用
8
進化計算による構造最適化例
進化の様子](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-8-320.jpg)
![Large-scale Evolution [Real et al., ICML2017]
• Mutationの種類
• Conv層の追加
• Conv層の除去
• strideの変更
• チャネル数の変更
• フィルタサイズの変更
• skip connectionの追加
• skip connectionの削除
• 学習率の変更
• 重みの初期化
9
進化計算による構造最適化例
current
individuals
next
individuals
a. 2個体を選択
b. 2個体を比較し,
良い方を残す
c. 新しい個体を
生成 (mutation)
d. a〜cの繰返し](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-9-320.jpg)
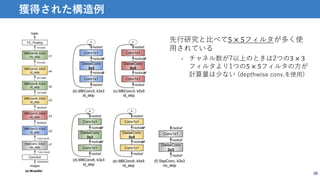
![CGP-CNN [Suganuma et al., GECCO2017]
• 遺伝的プログラミングの一種であるCartesian Genetic Programming (CGP)を
用いた手法.CNNをDirected acyclic graphで表現.
• 計算コストを抑えつつ,柔軟な構造探索が可能
• 層数やskip connectionも自動で調整可能
10
進化計算による構造最適化例
CGP → CNN
獲得された構造例](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-10-320.jpg)
![11
強化学習による構造最適化例
Neural Architecture Search (NAS) [Zoph et al., ICLR2017]
1. RNNでCNNの各層のハイパーパラメータ(フィルタ数/サイズなど)を出力
2. CNNをtraining setで訓練し,validation setで性能評価(報酬R)
3. 報酬Rの期待値を最大化するように強化学習(policy gradient)でRNNの
パラメータを最適化
• GPU800台使用( >人間を大学まで通わせる金額)
𝐽 𝜃𝑐 = 𝐸 𝑃(𝑎1:𝑇;𝜃)[𝑅]
∇ 𝜃 𝑐
𝐽 𝜃𝑐
=
𝑡=1
𝑇
𝐸 𝑃(𝑎1:𝑇;𝜃 𝑐)[∇ 𝜃 𝑐
log𝑃 𝑎 𝑡 𝑎 𝑡−1:1; 𝜃𝑐 𝑅]](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-11-320.jpg)
![12
強化学習による構造最適化例
Neural Architecture Search (NAS) [Zoph et al., ICLR2017]
• CIFAR-10で獲得された構造
• 各層の入力が複数ある場合はチャネルを結合
• 7 × 7のフィルタが多く使われている
• skip connectionが多い
• Large-scale evolutionとは対照的](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-12-320.jpg)
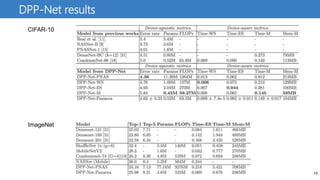
![13
強化学習による構造最適化例
NASNet [Zoph et al., CVPR2018]
• ネットワーク全体ではなく,2種類のセルの最適化を行う
• それらのセルを繰り返したものがネットワーク全体の構造を表す
• セル内のハイパーパラメータ(演算種類や接続関係)をRNNで探索(NASと同様)
• GPU500台使用
セルの例 全体のネット
ワーク構造](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-13-320.jpg)
![DPP-Net: Device-aware Progressive Search for Pareto-optimal Neural
Architectures [Dong et al., ECCV 2018]
• childすべてを学習するのではなく,surrogate functionによって性能○と判断された
childのみ学習を行う
• surrogate functionはRNN.入力はarch.の符号化したもの,出力はchildのaccuracy
• Mutation → surrogate functionによる予測 → 選択 → Train → Mutation → … の繰り返し
• Mutationは層の追加 (conv. or norm/act)
14
SMBOによる構造最適化例
処理の流れ Surrogate function](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-14-320.jpg)
![DARTS: Differentiable Architecture Search [Liu et al., arXiv:1806.09055v1]
• NASの問題設定を微分可能にし,勾配法によって構造最適化を行う
• 各エッジには演算処理(e.g., conv, pool)が予め複数個定義されており,各エッジにどの
演算を割り当てるかという問題設定(左下図(a))
• conv層などのweight parameterとは別に演算ごとに重み𝛼を付与し,それぞれ交互に最適化
• 最終的に𝛼が大きい演算を残す(左下図(b))
• 下式のように,各ノードの出力を各演算結果と各演算の重み𝛼の重み付き和として定義
することで微分可能にしている
16
Gradient-based methodによる構造最適化例
セルの表現
𝑜 𝑖,𝑗 𝑥
=
𝑜∈𝑂
exp 𝛼 𝑜
𝑖,𝑗
𝑜′∈𝑂 exp 𝛼 𝑜′
𝑖,𝑗
𝑜(𝑥)
(a) (b)
𝑖, 𝑗は接続関係を表す
構築されたセルの例](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-16-320.jpg)
![Efficient Neural Architecture Search via Parameter Sharing [Pham et al., ICML2018]
• 探索空間をDirected acyclic graphで定義し,subgraphをchildとみなす
• child間で重みを共有する(スクラッチから学習しない)
• あらかじめ入力しうる数の重みを保持しておき,入力に応じて切り替える
• 1GPU, 0.45 day の探索で 2.89% の error rateを達成 (CIFAR-10)
17
Weight sharing
DAG(探索空間) RNN (DAGのノード数が4の場合)
Child](https://image.slidesharecdn.com/201809293dsuganumamodify-181002005713/85/CNN-17-320.jpg)






![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)










