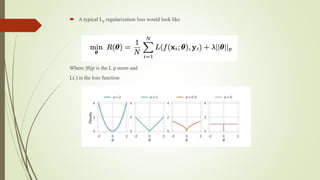
The document discusses the learning of sparse neural networks using l0 regularization, emphasizing its advantages in model compression and sparsification to combat overfitting. It describes the computational challenges posed by the non-differentiability of the l0 norm and introduces a re-parameterization approach that employs a continuous random variable to reformulate the loss function. The findings highlight the importance of optimizing network weights to achieve sparsity while maintaining differentiability through the re-parameterization trick.












































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
