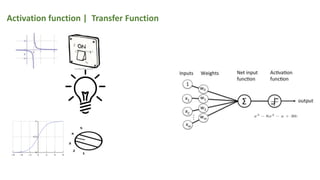
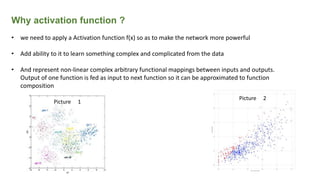
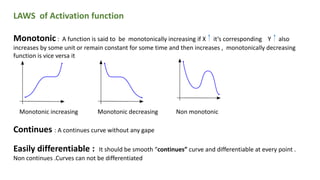
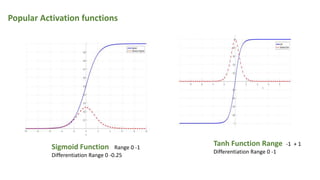
This document provides an overview of activation functions in deep learning. It discusses the purpose of activation functions, common types of activation functions like sigmoid, tanh, and ReLU, and issues like vanishing gradients that can occur with some activation functions. It explains that activation functions introduce non-linearity, allowing neural networks to learn complex patterns from data. The document also covers concepts like monotonicity, continuity, and differentiation properties that activation functions should have, as well as popular methods for updating weights during training like SGD, Adam, etc.






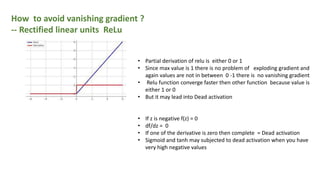
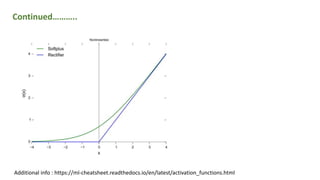
![Rectified liner unit Range 0 , x
Differentiations range 0 or 1
[tan 45 = 1]
Liki Rectified liner unit Range -x , x
Differentiations range -x or 1
Continued………..](https://image.slidesharecdn.com/activationfunction-191015105652/85/Activation-function-12-320.jpg)
![Weight update function
• Since we random initialize the weights we end up with some error.
• Now adjust your weights by differentiating your pervious output
• until you reach minimum error
Example : simple weight update
F(x) = x2 -3x + 2
df/dx = 0
df/dx = 2x – 3 + 0 = 0
x = 1.5 is this maxima or minima ?
put 1.5 in x2 – 3x + 2
f(1.5) = -0.25
f(1) = 0
Standard weight update functions
• SGD
• Min batch SGD
• SGD with momentum
• Ada grad
• Ada delta and RMS prop
• Adam [Adaptive momentum estimate ]Heart of gradient decent is chain rule in differentiation
When tangent is horizontal to x axis you may be at minima or maxima](https://image.slidesharecdn.com/activationfunction-191015105652/85/Activation-function-14-320.jpg)
![Vanishing Gradient in Sigmoid and Tanh functions
Dated from 1980 - 2012 people tried 2 - 3 layer neural networks
• Biggest problem faced is vanishing gradient [mathematical problem]
• Too little labelled data
• computation powers
History of activation function
We can get stuck in local minima or at saddle points](https://image.slidesharecdn.com/activationfunction-191015105652/85/Activation-function-15-320.jpg)