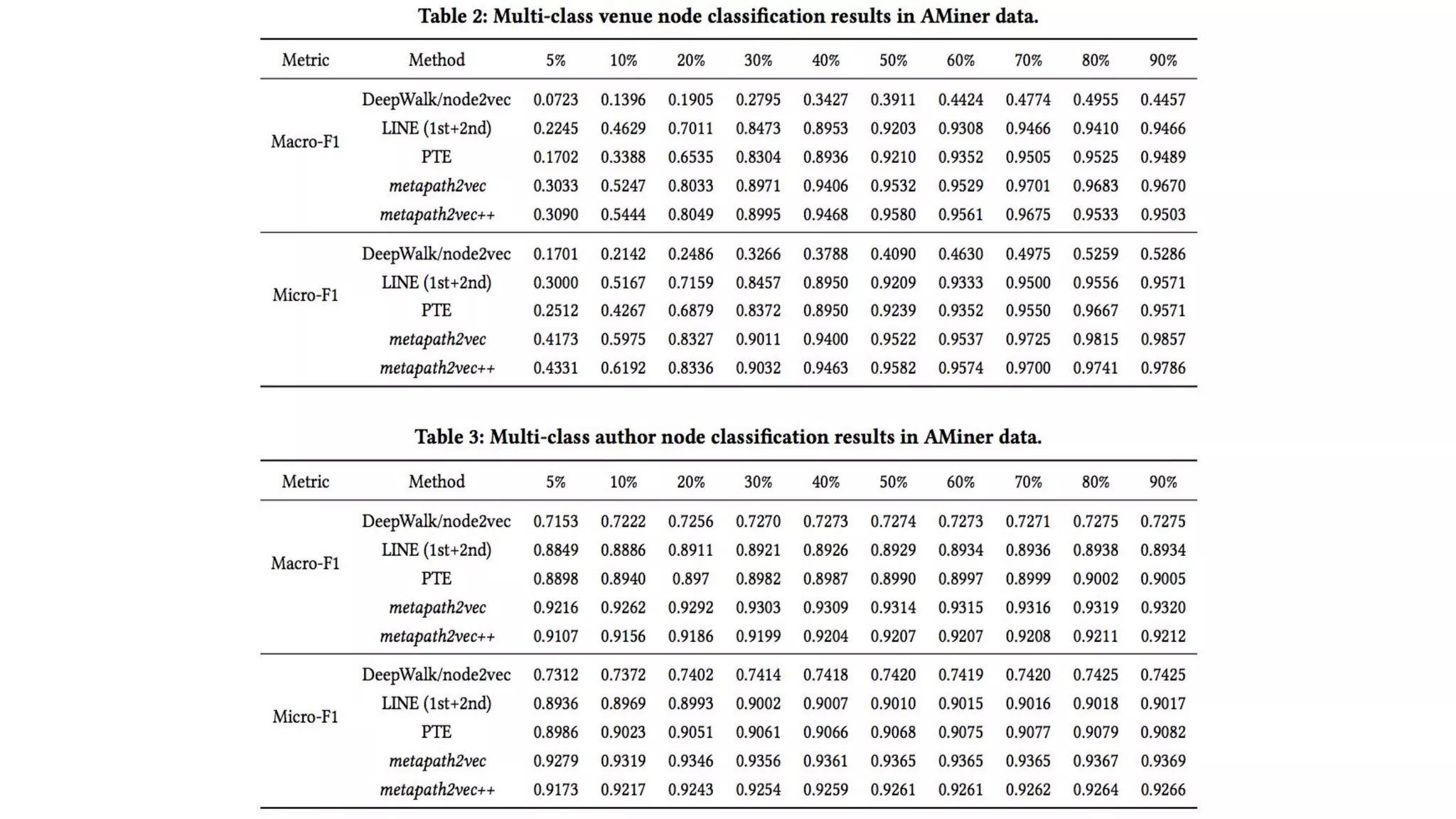
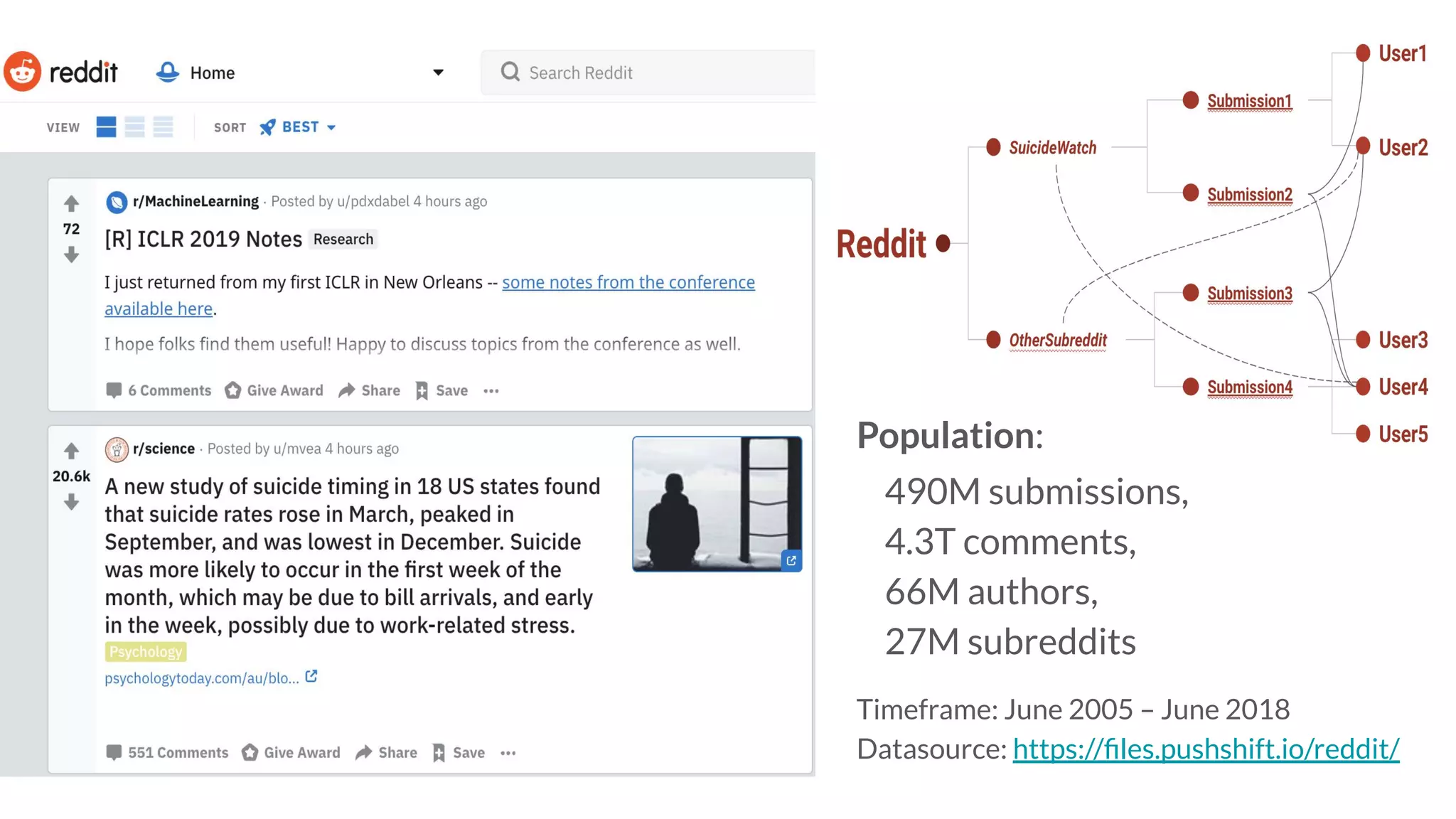
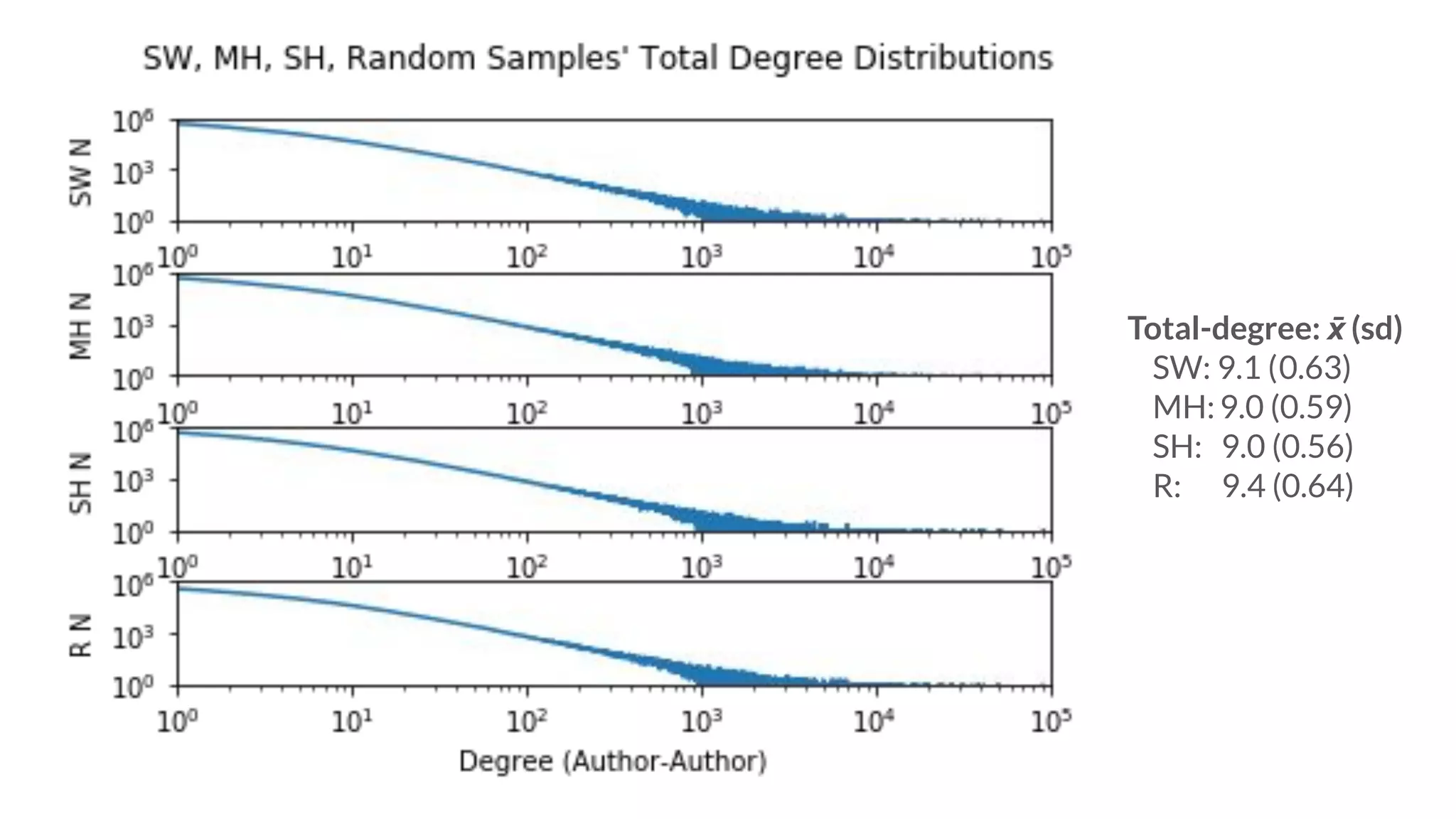
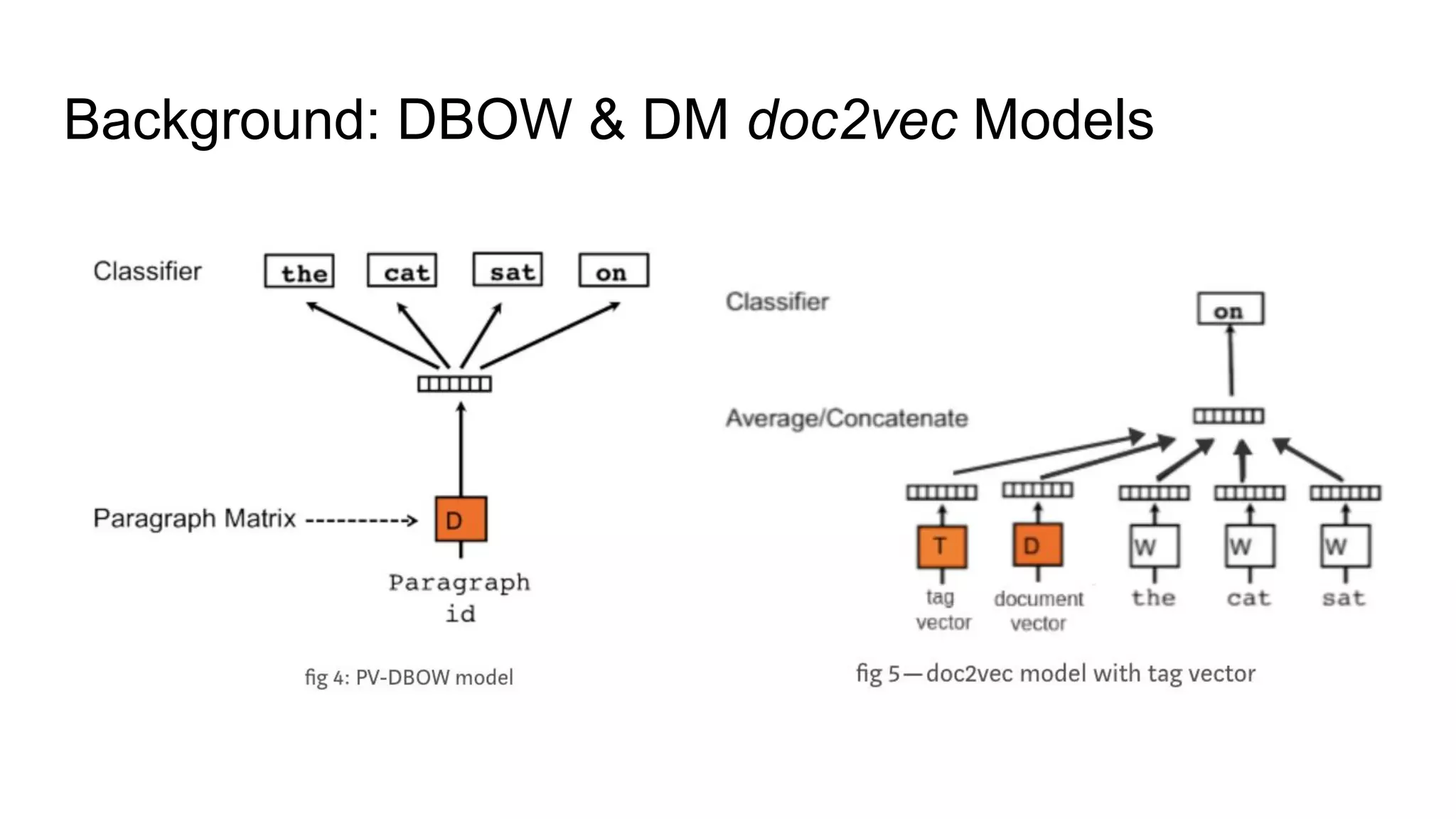
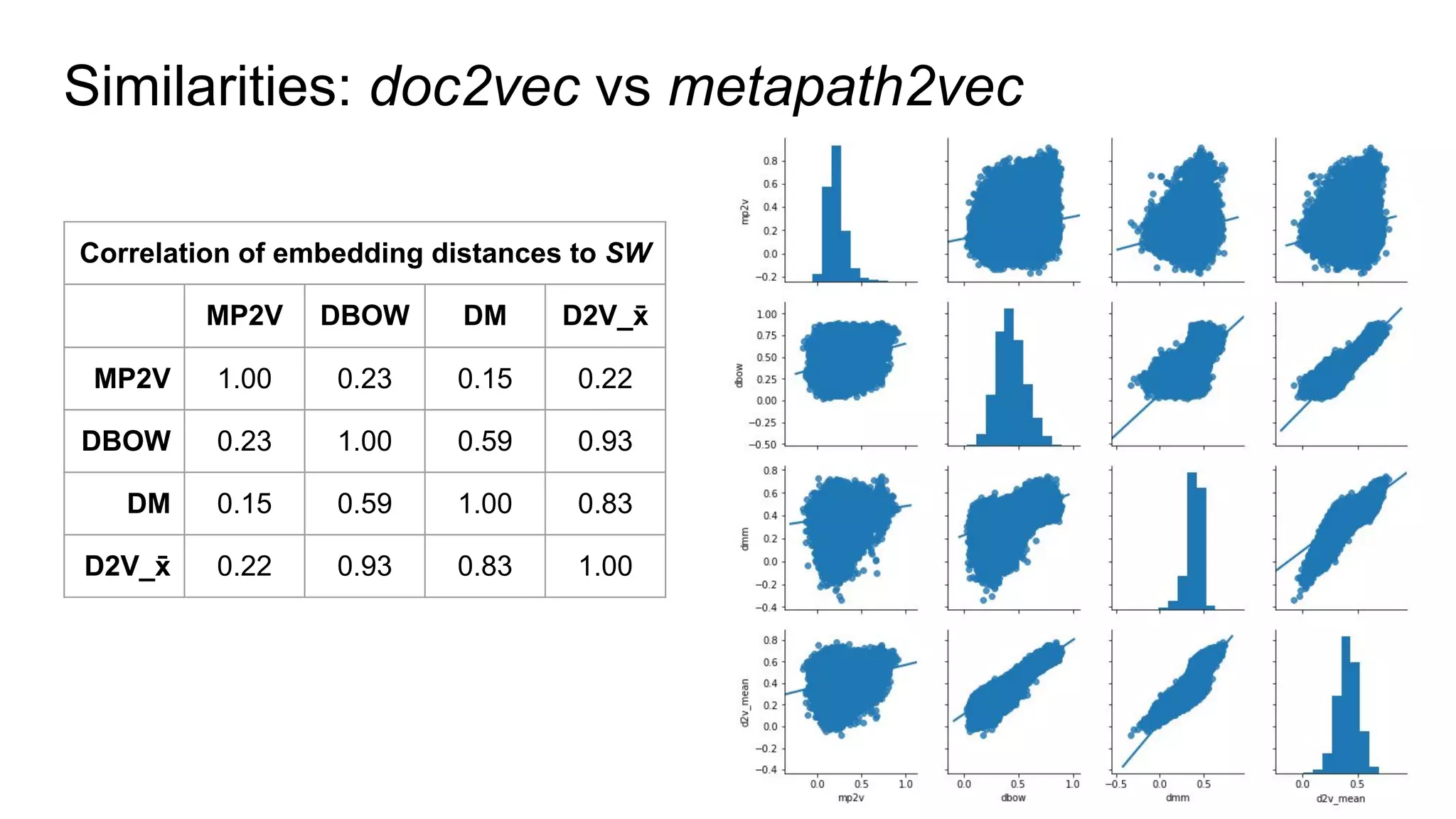
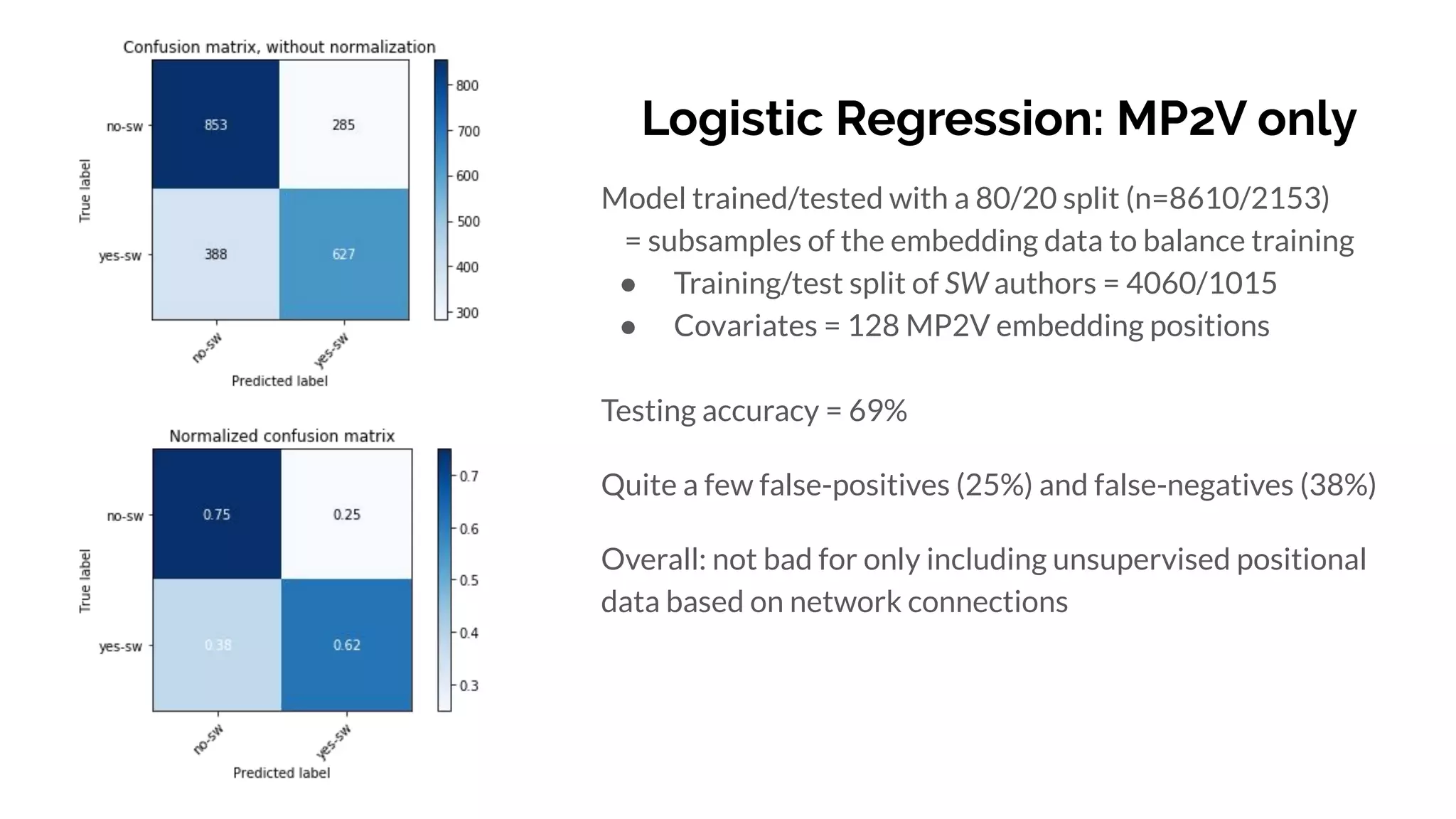
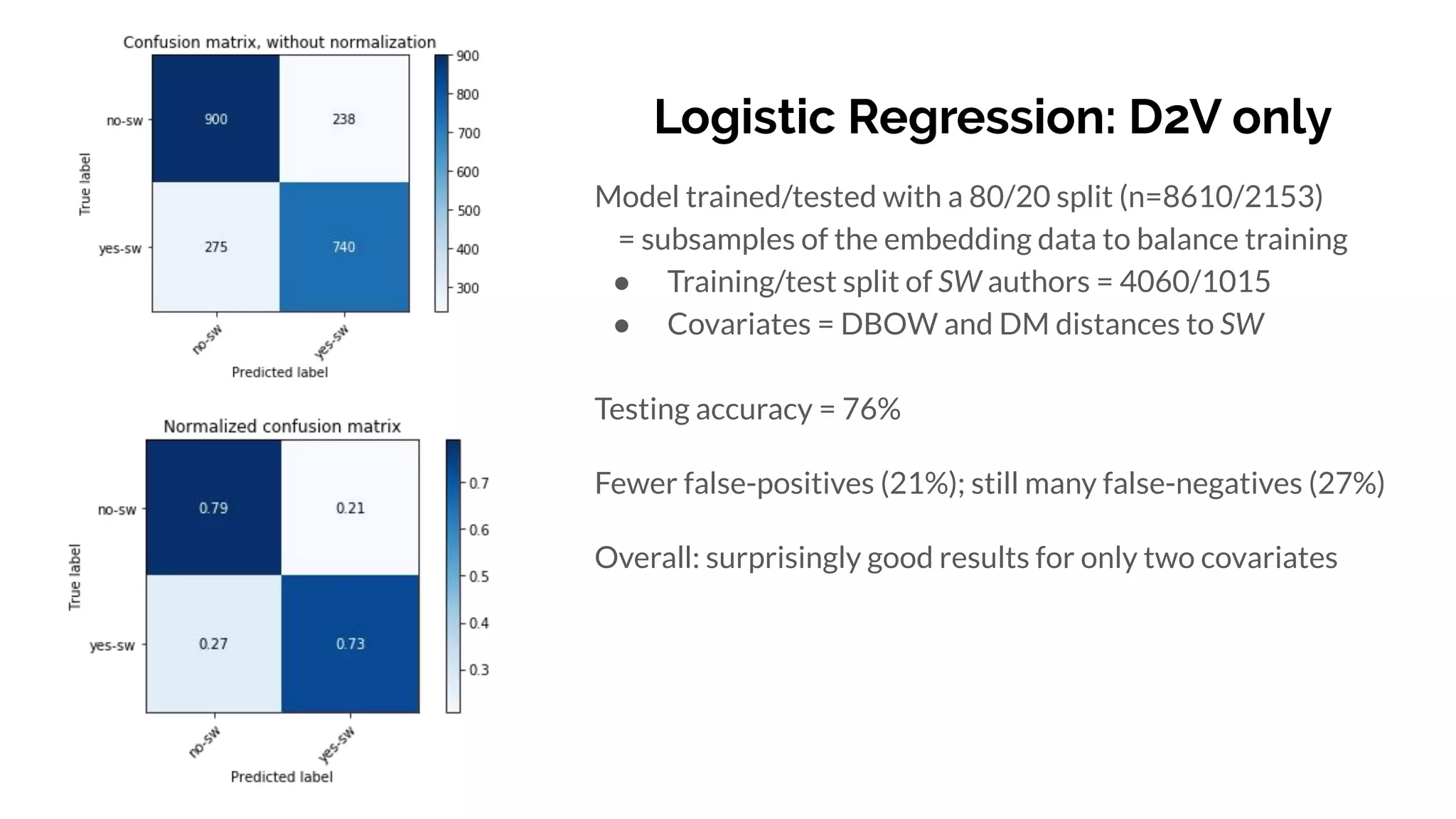
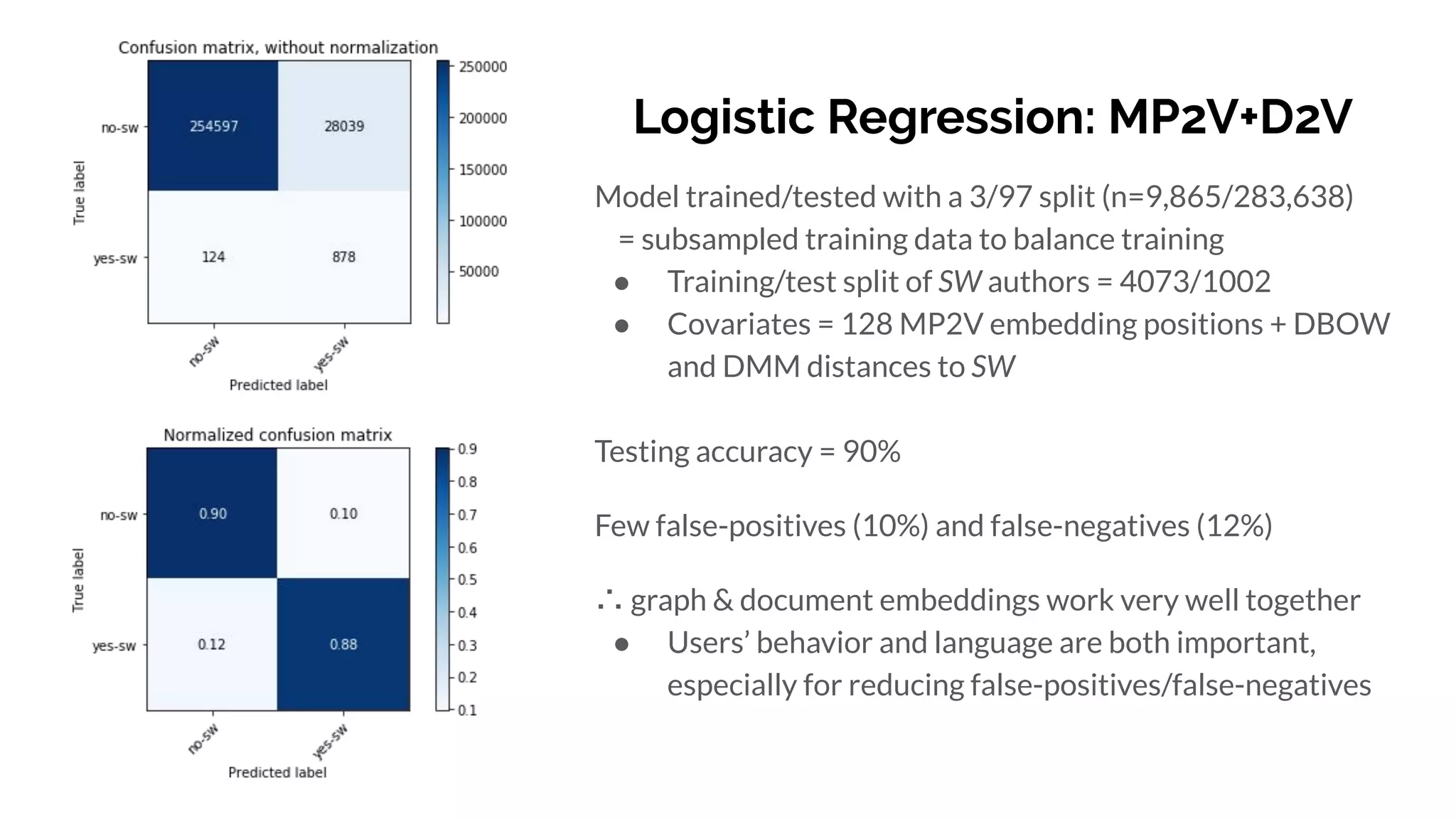
Graph and language embeddings were used to analyze user data from Reddit to predict whether authors would post in the SuicideWatch subreddit. Metapath2vec was used to generate graph embeddings from subreddit and author relationships. Doc2vec was used to generate document embeddings based on language similarity between submissions and subreddits. Combining the graph and document embeddings in a logistic regression achieved 90% accuracy in predicting SuicideWatch posters, reducing both false positives and false negatives compared to using the embeddings separately. Next steps proposed using the embeddings to better understand similarities between related subreddits and predict risk factors in posts.








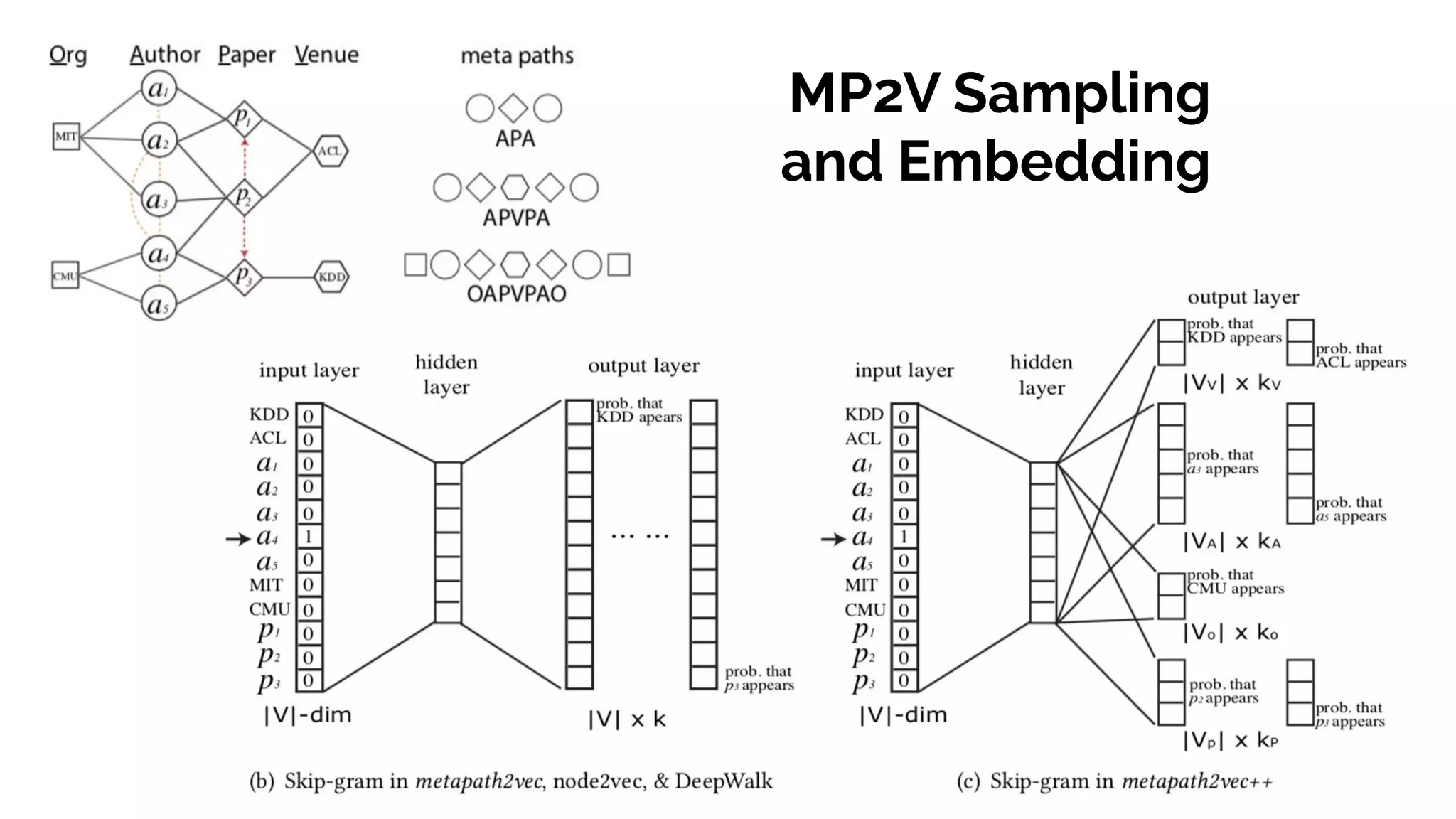












![Metapath Examples and Complexity
# author to subr (via subm or comm)
["author", "submission", "subreddit", "submission", "author"], #subm to same subr
["author", "comment", "submission", "subreddit", "submission", "comment", "author"], #comm to same subr
# submission to submission (via subm or auth)
["submission", "subreddit", "submission"], #subm to same subr
["submission", "author", "submission"], #subm by same auth
# comment to comment (via subm or auth)
["comment", "submission", "comment"], #comm to same subm
["comment", "author", "comment"], #comm by same auth
# subreddit to subreddit
["subreddit", "submission", "author", "submission", "subreddit"], #subr by same auth via subm
["subreddit", "submission", "comment", "author", "comment", "submission", "subreddit"] #subr by same auth via comm
Estimated complexity:
SBM: O((Vln2
V + E) × MCMC_sweeps) → O(SMBv=10M,e=45M,s=15
) = 40B (1 sweep = 2.7B)
HSBM:O((Vln2
V + E×Blocks) × MCMC_sweeps) → O(HSBMv=10M,e=45M,b=20,s=15
) = 52B
MP2V: O((V_seeds × walks × walk_length) + ((V_sampled - mp2v_window) × mp2v_iter)) → O(MP2Vv=10M,e=45M,iter=15
) =
2B
∴ MP2V 8 times more computationally efficient](https://image.slidesharecdn.com/ruch2019snhcanx2vecsavelives-190924152422/75/00-Automatic-Mental-Health-Classification-in-Online-Settings-and-Language-Embeddings-30-2048.jpg)