Download as PDF, PPTX




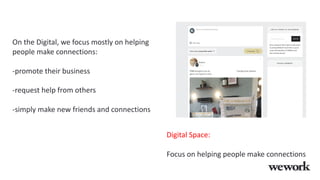














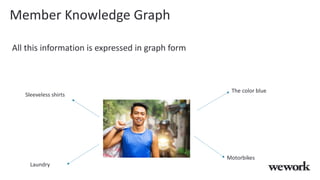
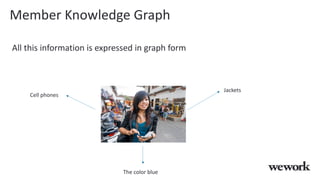


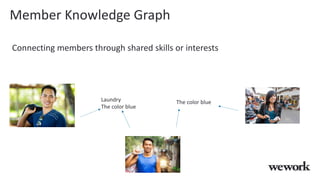
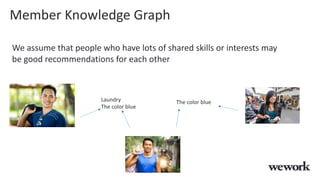
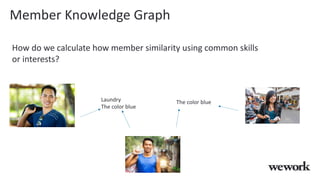


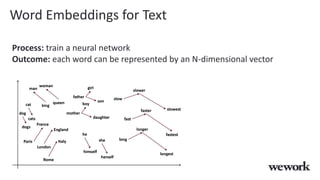
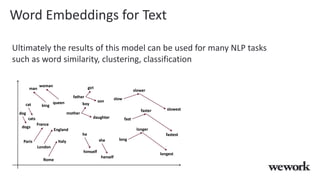
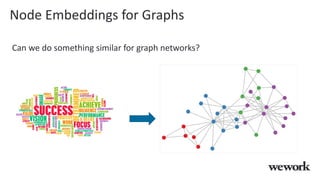

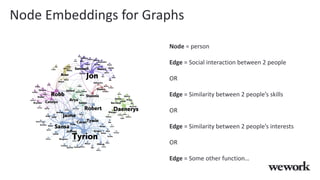
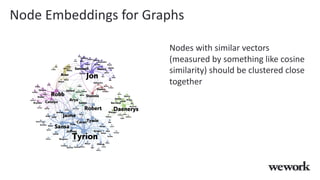




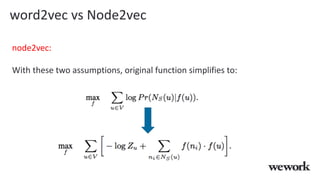

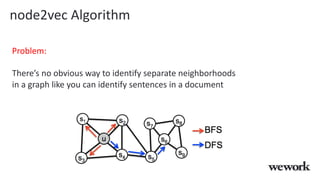
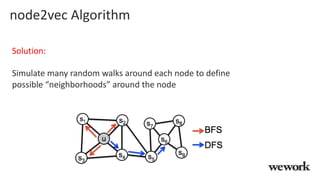






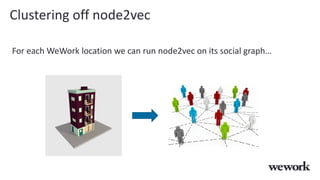
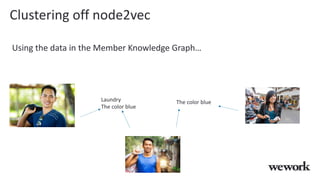
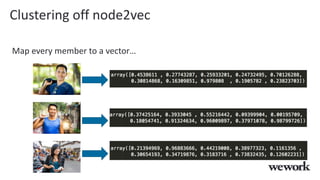






This document discusses how WeWork is using graph embeddings and the node2vec algorithm to power member recommendations. It first describes WeWork's member knowledge graph that contains data on members' profiles, interactions, interests and skills. It then explains how node2vec can learn vector representations of each member node that capture similarities, which can be used for recommendations. WeWork runs node2vec on the social graph of each location to map members to vectors and identify the most similar members to power recommendations like onboarding suggestions and introductions between members.




































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















