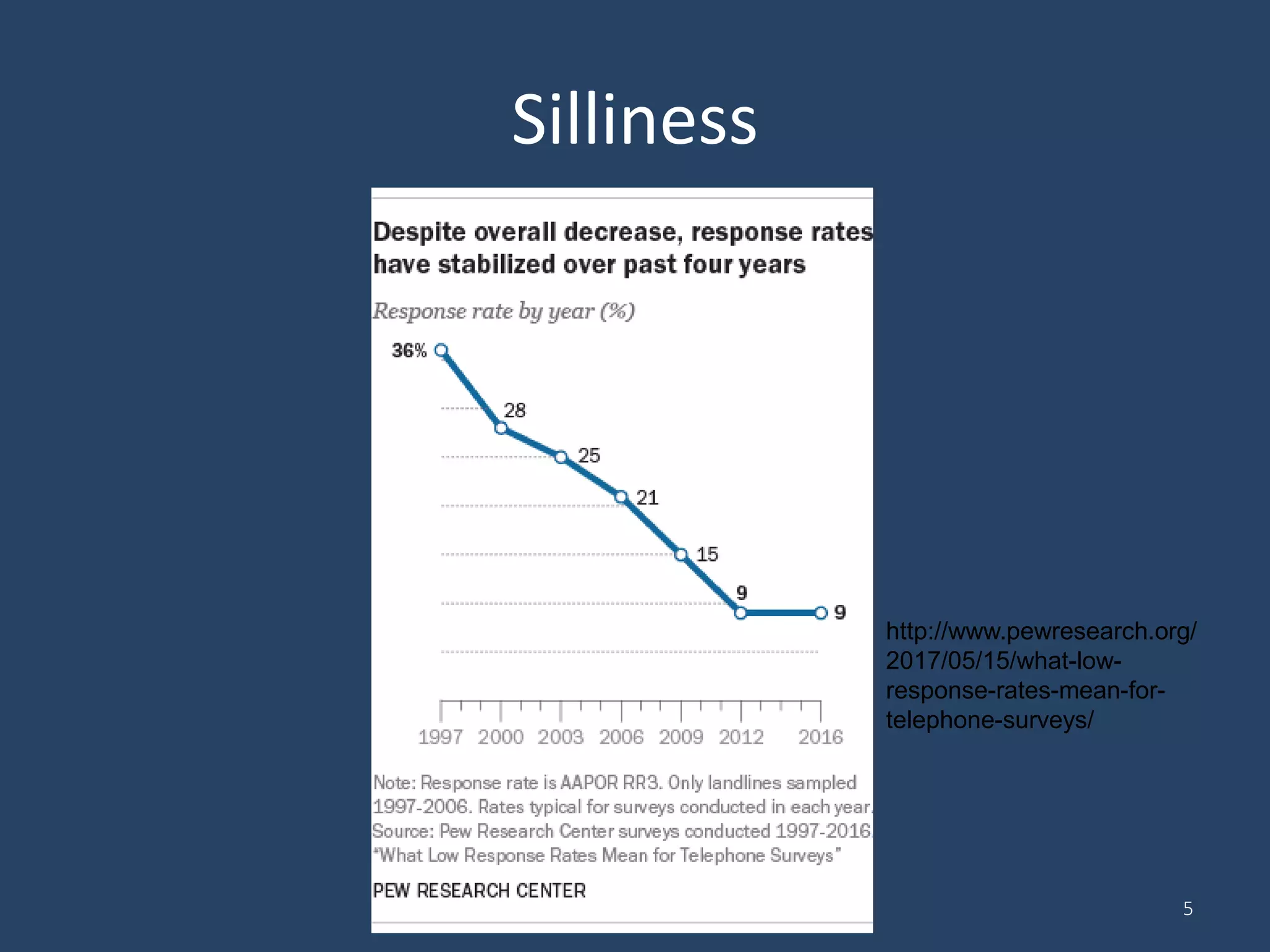
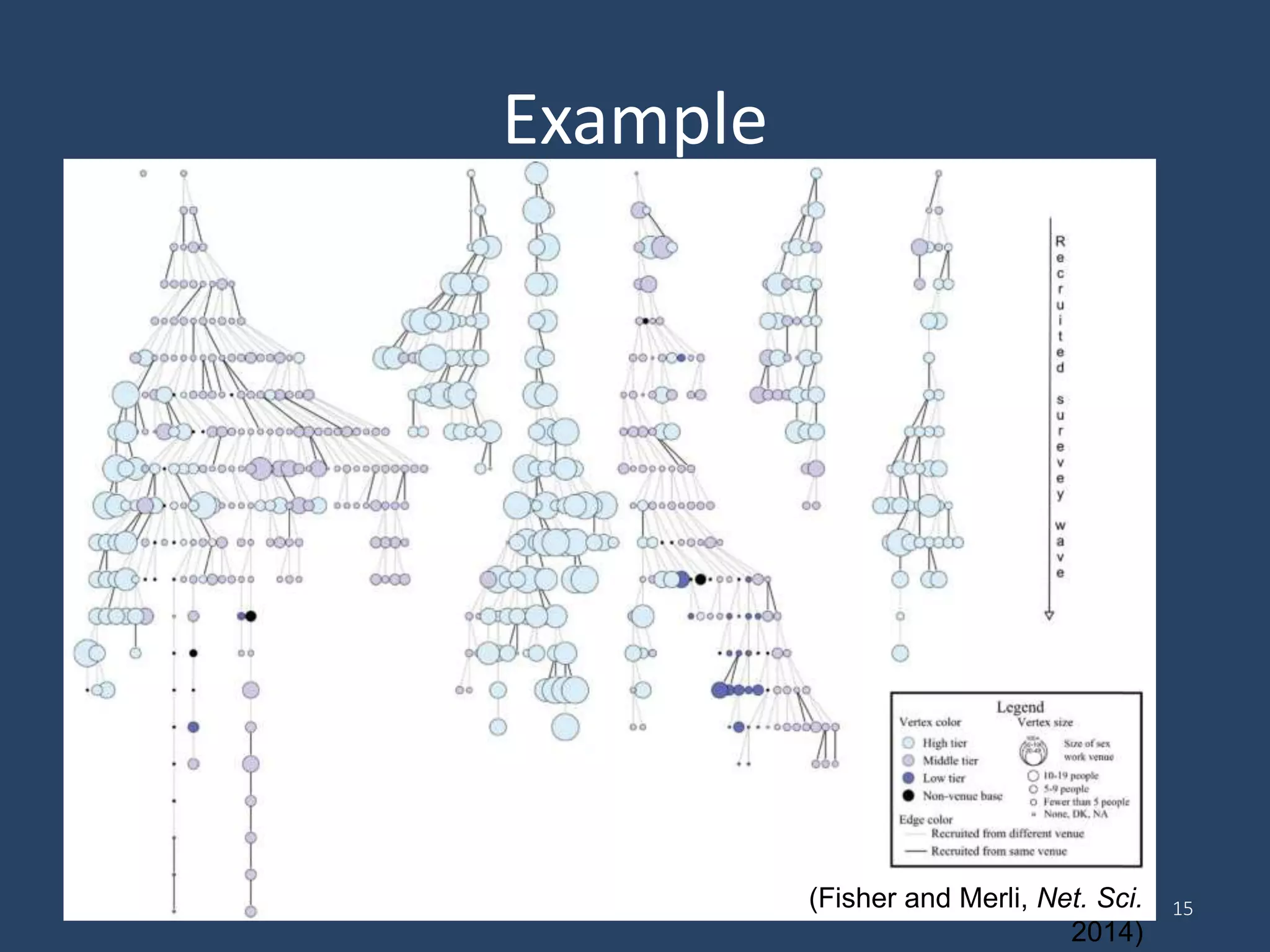
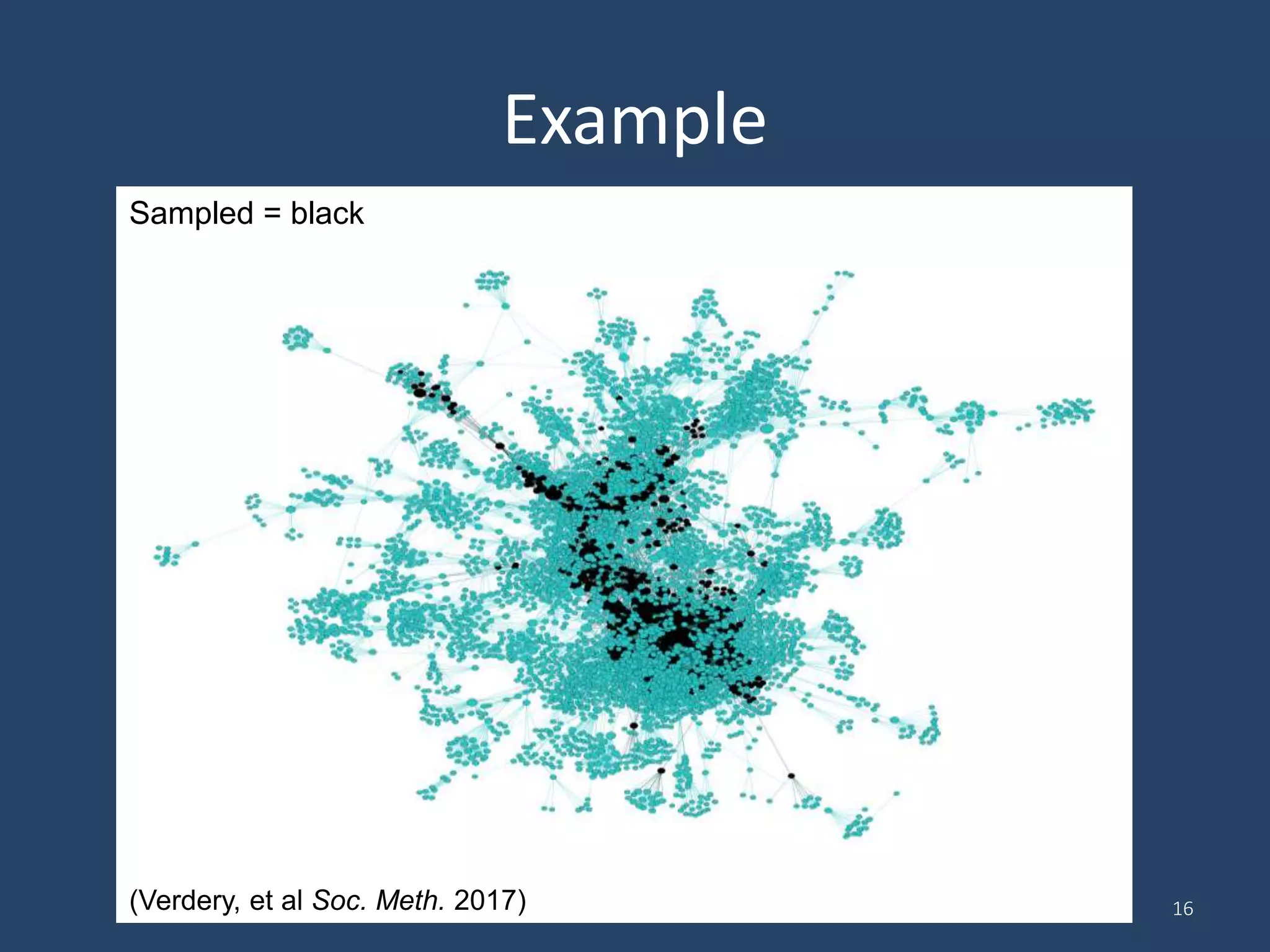
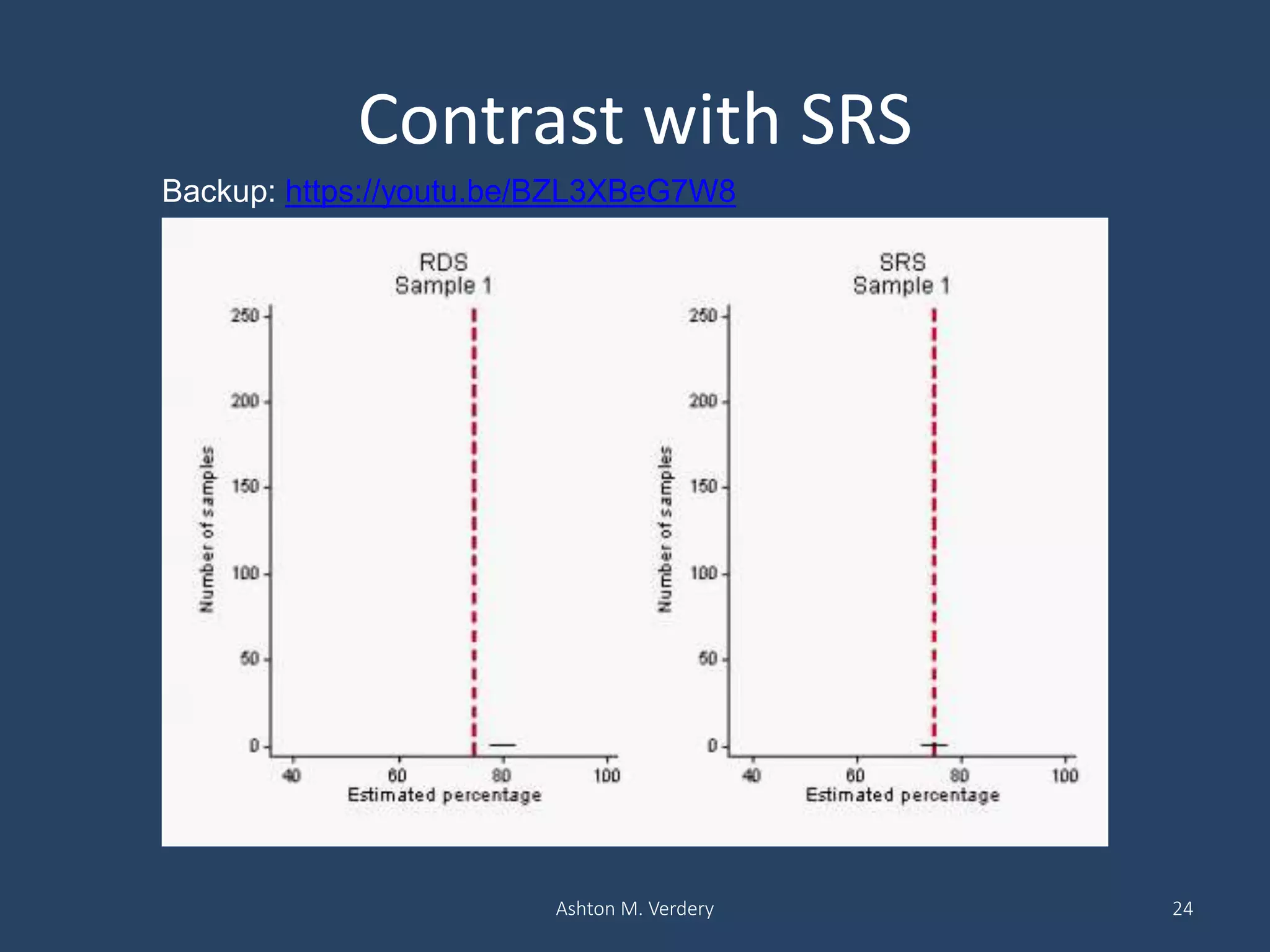
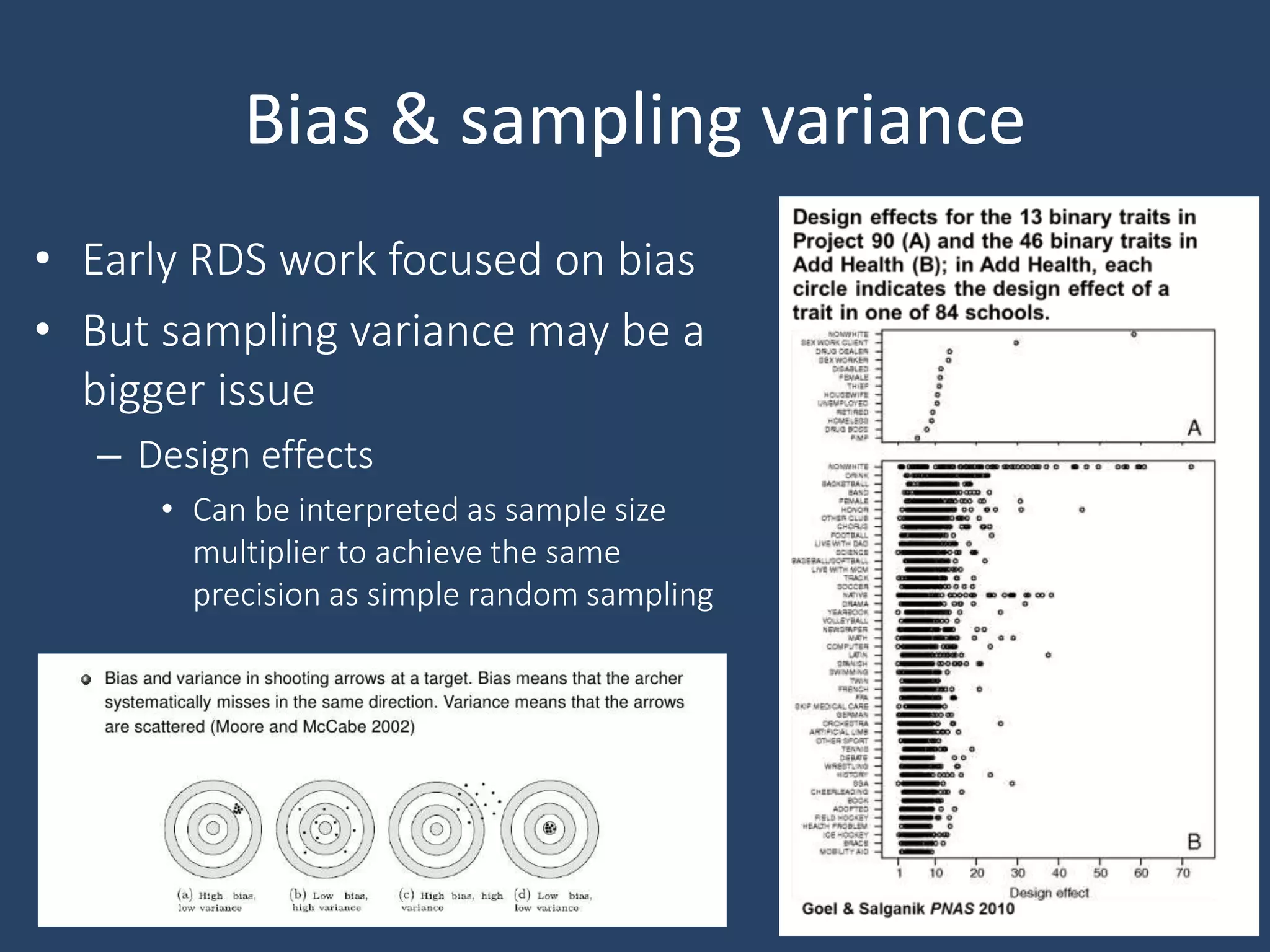
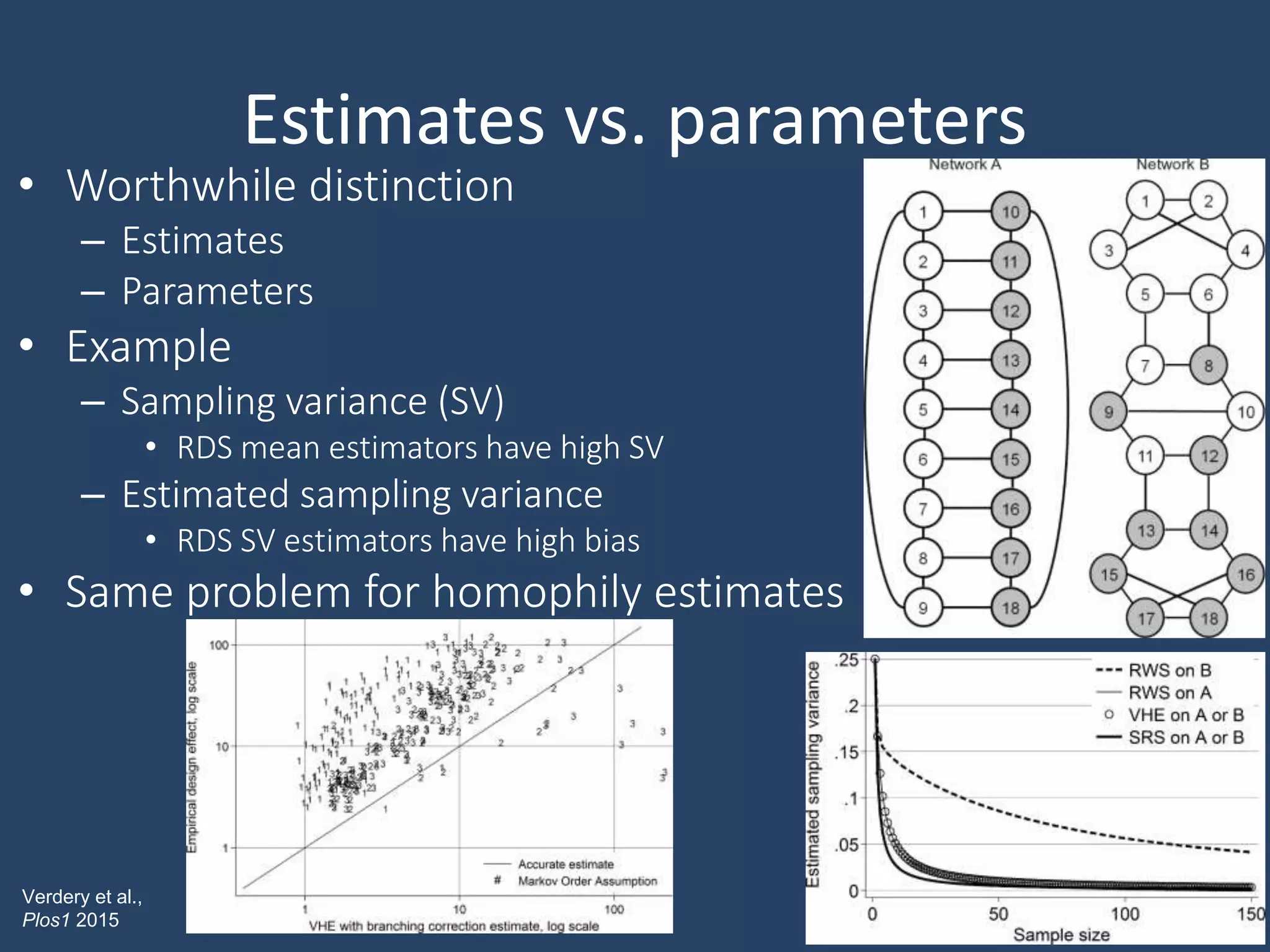
Respondent-Driven Sampling (RDS) is a method for sampling hidden populations by leveraging social networks. RDS begins with a small number of initial participants (seeds) who are given coupons to recruit a limited number of people from their social networks. Those recruits then recruit others from their own networks. The process continues in chains of referrals until the target sample size is reached. RDS aims to correct for biases through statistical weighting based on network properties like degree. Over 500 studies have used RDS across diverse fields. While RDS has enabled new insights, its assumptions of random recruitment and unbiased seeds are often violated. Estimates of sampling variance from RDS also tend to be problematic. Nonetheless, R